 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Inner Workings of Language Models Through Representation Dissimilarity
Oct 23, 2023



As language models are applied to an increasing number of real-world applications, understanding their inner workings has become an important issue in model trust, interpretability, and transparency. In this work we show that representation dissimilarity measures, which are functions that measure the extent to which two model's internal representations differ, can be a valuable tool for gaining insight into the mechanics of language models. Among our insights are: (i) an apparent asymmetry in the internal representations of model using SoLU and GeLU activation functions, (ii) evidence that dissimilarity measures can identify and locate generalization properties of models that are invisible via in-distribution test set performance, and (iii) new evaluations of how language model features vary as width and depth are increased. Our results suggest that dissimilarity measures are a promising set of tools for shedding light on the inner workings of language models.
Attributing Learned Concepts in Neural Networks to Training Data
Oct 06, 2023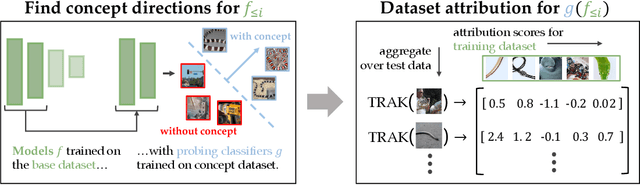

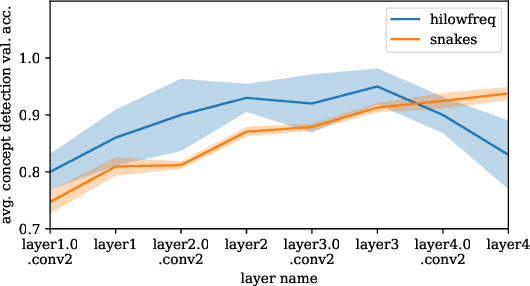
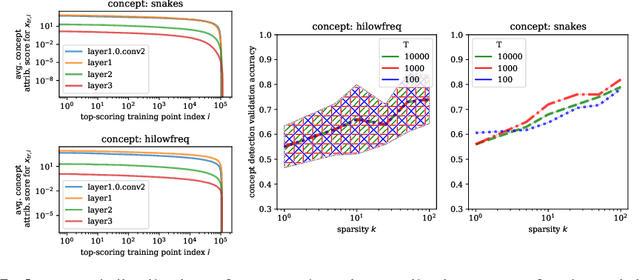
By now there is substantial evidence that deep learning models learn certain human-interpretable features as part of their internal representations of data. As having the right (or wrong) concepts is critical to trustworthy machine learning systems, it is natural to ask which inputs from the model's original training set were most important for learning a concept at a given layer. To answer this, we combine data attribution methods with methods for probing the concepts learned by a model. Training network and probe ensembles for two concept datasets on a range of network layers, we use the recently developed TRAK method for large-scale data attribution. We find some evidence for convergence, where removing the 10,000 top attributing images for a concept and retraining the model does not change the location of the concept in the network nor the probing sparsity of the concept. This suggests that rather than being highly dependent on a few specific examples, the features that inform the development of a concept are spread in a more diffuse manner across its exemplars, implying robustness in concept formation.
Robustness of edited neural networks
Feb 28, 2023



Successful deployment in uncertain, real-world environments requires that deep learning models can be efficiently and reliably modified in order to adapt to unexpected issues. However, the current trend toward ever-larger models makes standard retraining procedures an ever-more expensive burden. For this reason, there is growing interest in model editing, which enables computationally inexpensive, interpretable, post-hoc model modifications. While many model editing techniques are promising, research on the properties of edited models is largely limited to evaluation of validation accuracy. The robustness of edited models is an important and yet mostly unexplored topic. In this paper, we employ recently developed techniques from the field of deep learning robustness to investigate both how model editing affects the general robustness of a model, as well as the robustness of the specific behavior targeted by the edit. We find that edits tend to reduce general robustness, but that the degree of degradation depends on the editing algorithm chosen. In particular, robustness is best preserved by more constrained techniques that modify less of the model. Motivated by these observations, we introduce two new model editing algorithms, direct low-rank model editing and 1-layer interpolation (1-LI), which each exhibit strong generalization performance.