 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptM$^3$oE: Concept-Guided Multimodal Mixture of Experts for Interpretable Computational Pathology
May 27, 2026Healthcare models are transitioning from unimodal prediction toward multimodal reasoning over heterogeneous diagnostic inputs. In computational pathology, for complex tumor subtypes where morphology alone can be challenging to distinguish, pathology reports and molecular measurements may provide additional diagnostic evidence alongside whole-slide images, yet existing models often fail to clarify how diverse signals assemble into recognizable diagnostic concepts. We propose ConceptM$^3$oE (Concept Multimodal MoE), which embeds concept formation directly within interaction-aware mixture-of-experts (MoE) pathways. The architecture decomposes evidence into modality-specific, redundant, and synergistic experts, which are then projected into structured concept bottlenecks mapping latent features to a hierarchy of morphology and biomarker concepts. To prevent the information loss typical of interpretable bottlenecks, we utilize residual pathways within each expert to allow task-relevant signals to flow both through the concepts and directly to the final task prediction, so that high performance is maintained alongside interpretability. Across an institutional pediatric brain tumor cohort and a public glioma cohort, the framework delivers competitive performance to unconstrained models while producing reasoning traces validated by an independent neuropathologist. In data-limited regimes, ConceptM$^3$oE improves limited-data performance, increasing macro-F1 from 56.41% to 66.70% at small training sizes compared to non-concept-informed baselines, while also showing faster training convergence consistent with the regularizing effect of concept learning. This work offers a scalable path toward high-performance medical AI that is inherently verifiable and better aligned with the complex decision-making of clinical practice.
Clinically-Informed Modeling for Pediatric Brain Tumor Classification from Whole-Slide Histopathology Images
Apr 22, 2026Accurate diagnosis of pediatric brain tumors, starting with histopathology, presents unique challenges for deep learning, including severe data scarcity, class imbalance, and fine-grained morphologic overlap across diagnostically distinct subtypes. While pathology foundation models have advanced patch-level representation learning, their effective adaptation to weakly supervised pediatric brain tumor classification under limited data remains underexplored. In this work, we introduce an expert-guided contrastive fine-tuning framework for pediatric brain tumor diagnosis from whole-slide images (WSI). Our approach integrates contrastive learning into slide-level multiple instance learning (MIL) to explicitly regularize the geometry of slide-level representations during downstream fine-tuning. We propose both a general supervised contrastive setting and an expert-guided variant that incorporates clinically informed hard negatives targeting diagnostically confusable subtypes. Through comprehensive experiments on pediatric brain tumor WSI classification under realistic low-sample and class-imbalanced conditions, we demonstrate that contrastive fine-tuning yields measurable improvements in fine-grained diagnostic distinctions. Our experimental analyses reveal complementary strengths across different contrastive strategies, with expert-guided hard negatives promoting more compact intra-class representations and improved inter-class separation. This work highlights the importance of explicitly shaping slide-level representations for robust fine-grained classification in data-scarce pediatric pathology settings.
PathMoE: Interpretable Multimodal Interaction Experts for Pediatric Brain Tumor Classification
Mar 02, 2026Accurate classification of pediatric central nervous system tumors remains challenging due to histological complexity and limited training data. While pathology foundation models have advanced whole-slide image (WSI) analysis, they often fail to leverage the rich, complementary information found in clinical text and tissue microarchitecture. To this end, we propose PathMoE, an interpretable multimodal framework that integrates H\&E slides, pathology reports, and nuclei-level cell graphs via an interaction-aware mixture-of-experts architecture built on state-of-the-art foundation models for each modality. By training specialized experts to capture modality uniqueness, redundancy, and synergy, PathMoE employs an input-dependent gating mechanism that dynamically weights these interactions, providing sample-level interpretability. We evaluate our framework on two dataset-specific classification tasks on an internal pediatric brain tumor dataset (PBT) and external TCGA datasets. PathMoE improves macro-F1 from 0.762 to 0.799 (+0.037) on PBT when integrating WSI, text, and graph modalities; on TCGA, augmenting WSI with graph knowledge improves macro-F1 from 0.668 to 0.709 (+0.041). These results demonstrate significant performance gains over state-of-the-art image-only baselines while revealing the specific modality interactions driving individual predictions. This interpretability is particularly critical for rare tumor subtypes, where transparent model reasoning is essential for clinical trust and diagnostic validation.
MRI-CORE: A Foundation Model for Magnetic Resonance Imaging
Jun 13, 2025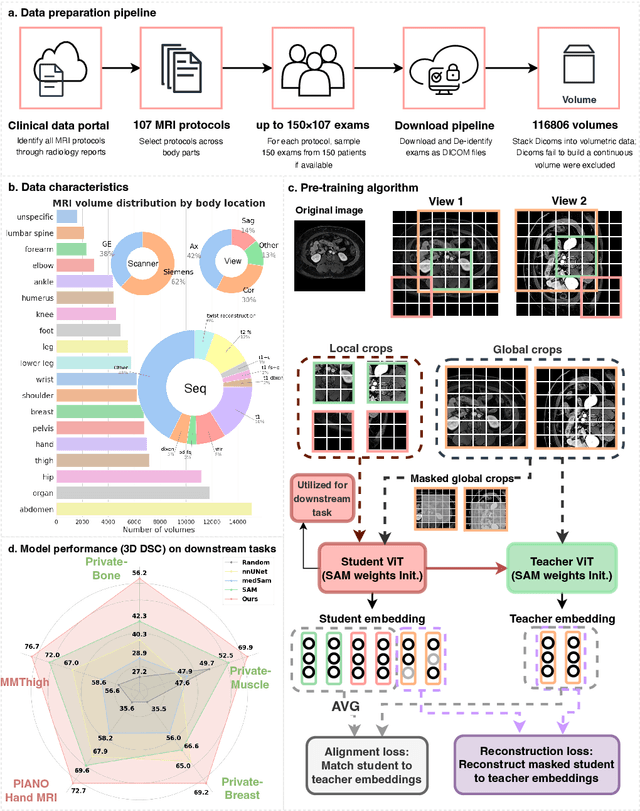
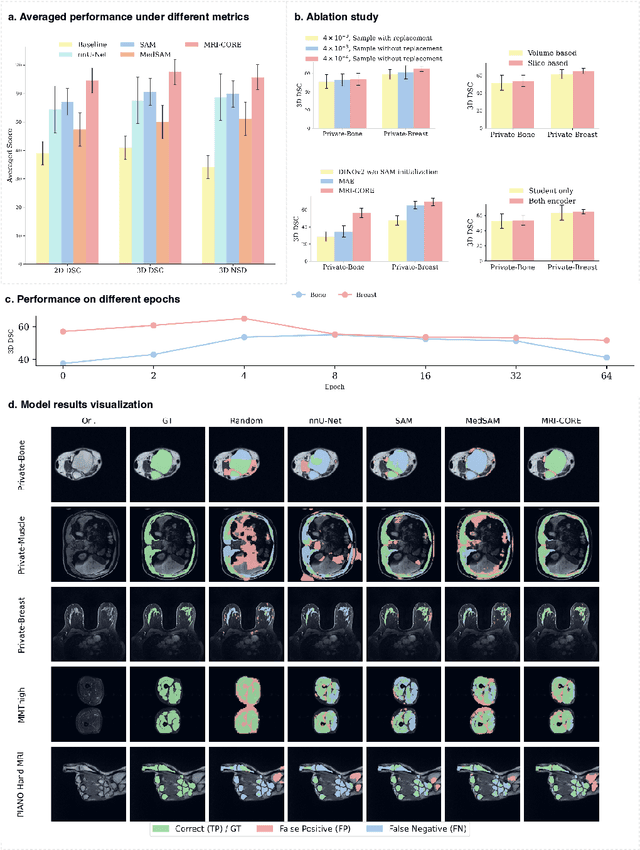
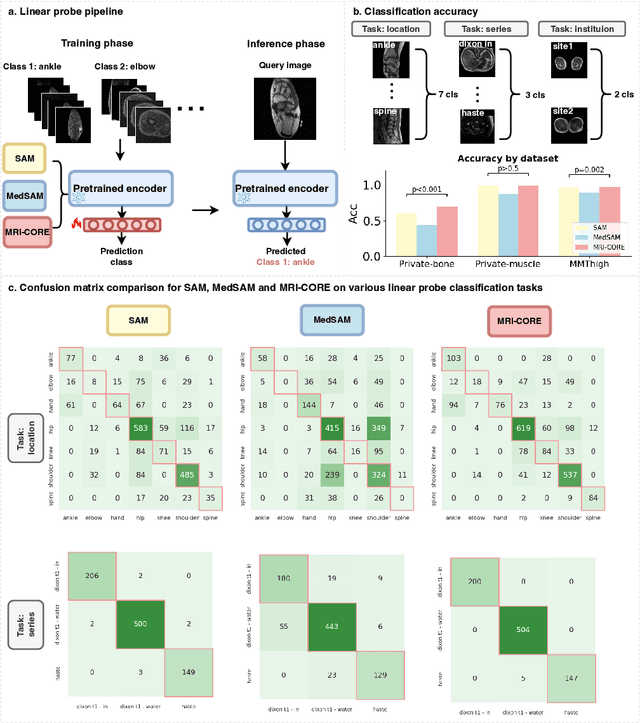
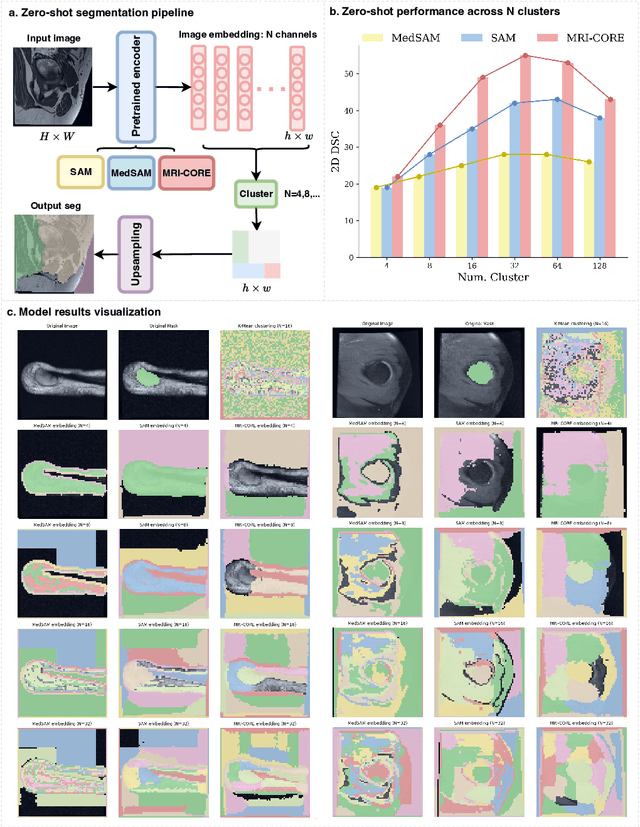
The widespread use of Magnetic Resonance Imaging (MRI) and the rise of deep learning have enabled the development of powerful predictive models for a wide range of diagnostic tasks in MRI, such as image classification or object segmentation. However, training models for specific new tasks often requires large amounts of labeled data, which is difficult to obtain due to high annotation costs and data privacy concerns. To circumvent this issue, we introduce MRI-CORE (MRI COmprehensive Representation Encoder), a vision foundation model pre-trained using more than 6 million slices from over 110,000 MRI volumes across 18 main body locations. Experiments on five diverse object segmentation tasks in MRI demonstrate that MRI-CORE can significantly improve segmentation performance in realistic scenarios with limited labeled data availability, achieving an average gain of 6.97% 3D Dice Coefficient using only 10 annotated slices per task. We further demonstrate new model capabilities in MRI such as classification of image properties including body location, sequence type and institution, and zero-shot segmentation. These results highlight the value of MRI-CORE as a generalist vision foundation model for MRI, potentially lowering the data annotation resource barriers for many applications.
GuidedMorph: Two-Stage Deformable Registration for Breast MRI
May 19, 2025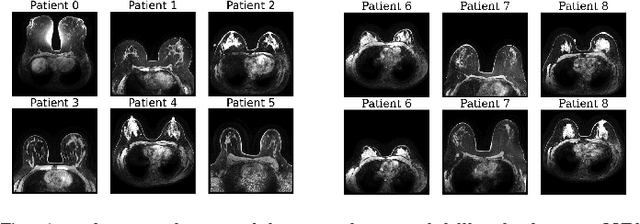
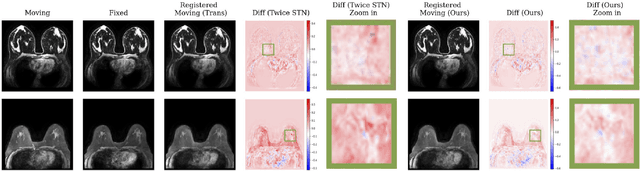
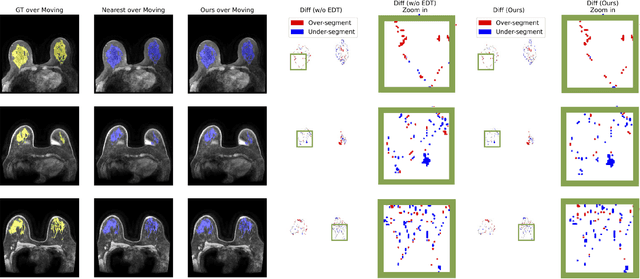
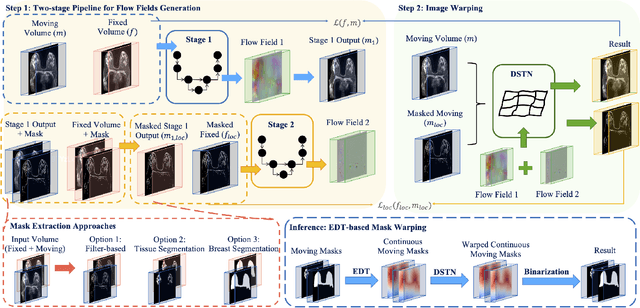
Accurately registering breast MR images from different time points enables the alignment of anatomical structures and tracking of tumor progression, supporting more effective breast cancer detection, diagnosis, and treatment planning. However, the complexity of dense tissue and its highly non-rigid nature pose challenges for conventional registration methods, which primarily focus on aligning general structures while overlooking intricate internal details. To address this, we propose \textbf{GuidedMorph}, a novel two-stage registration framework designed to better align dense tissue. In addition to a single-scale network for global structure alignment, we introduce a framework that utilizes dense tissue information to track breast movement. The learned transformation fields are fused by introducing the Dual Spatial Transformer Network (DSTN), improving overall alignment accuracy. A novel warping method based on the Euclidean distance transform (EDT) is also proposed to accurately warp the registered dense tissue and breast masks, preserving fine structural details during deformation. The framework supports paradigms that require external segmentation models and with image data only. It also operates effectively with the VoxelMorph and TransMorph backbones, offering a versatile solution for breast registration. We validate our method on ISPY2 and internal dataset, demonstrating superior performance in dense tissue, overall breast alignment, and breast structural similarity index measure (SSIM), with notable improvements by over 13.01% in dense tissue Dice, 3.13% in breast Dice, and 1.21% in breast SSIM compared to the best learning-based baseline.
Accelerating Volumetric Medical Image Annotation via Short-Long Memory SAM 2
May 03, 2025Manual annotation of volumetric medical images, such as magnetic resonance imaging (MRI) and computed tomography (CT), is a labor-intensive and time-consuming process. Recent advancements in foundation models for video object segmentation, such as Segment Anything Model 2 (SAM 2), offer a potential opportunity to significantly speed up the annotation process by manually annotating one or a few slices and then propagating target masks across the entire volume. However, the performance of SAM 2 in this context varies. Our experiments show that relying on a single memory bank and attention module is prone to error propagation, particularly at boundary regions where the target is present in the previous slice but absent in the current one. To address this problem, we propose Short-Long Memory SAM 2 (SLM-SAM 2), a novel architecture that integrates distinct short-term and long-term memory banks with separate attention modules to improve segmentation accuracy. We evaluate SLM-SAM 2 on three public datasets covering organs, bones, and muscles across MRI and CT modalities. We show that the proposed method markedly outperforms the default SAM 2, achieving average Dice Similarity Coefficient improvement of 0.14 and 0.11 in the scenarios when 5 volumes and 1 volume are available for the initial adaptation, respectively. SLM-SAM 2 also exhibits stronger resistance to over-propagation, making a notable step toward more accurate automated annotation of medical images for segmentation model development.
Quantifying the Limits of Segment Anything Model: Analyzing Challenges in Segmenting Tree-Like and Low-Contrast Structures
Dec 05, 2024Segment Anything Model (SAM) has shown impressive performance in interactive and zero-shot segmentation across diverse domains, suggesting that they have learned a general concept of "objects" from their large-scale training. However, we observed that SAM struggles with certain types of objects, particularly those featuring dense, tree-like structures and low textural contrast from their surroundings. These failure modes are critical for understanding its limitations in real-world use. In order to systematically examine this issue, we propose metrics to quantify two key object characteristics: tree-likeness and textural separability. Through extensive controlled synthetic experiments and testing on real datasets, we demonstrate that SAM's performance is noticeably correlated with these factors. We link these behaviors under the concept of "textural confusion", where SAM misinterprets local structure as global texture, leading to over-segmentation, or struggles to differentiate objects from similarly textured backgrounds. These findings offer the first quantitative framework to model SAM's challenges, providing valuable insights into its limitations and guiding future improvements for vision foundation models.
RaD: A Metric for Medical Image Distribution Comparison in Out-of-Domain Detection and Other Applications
Dec 02, 2024Determining whether two sets of images belong to the same or different domain is a crucial task in modern medical image analysis and deep learning, where domain shift is a common problem that commonly results in decreased model performance. This determination is also important to evaluate the output quality of generative models, e.g., image-to-image translation models used to mitigate domain shift. Current metrics for this either rely on the (potentially biased) choice of some downstream task such as segmentation, or adopt task-independent perceptual metrics (e.g., FID) from natural imaging which insufficiently capture anatomical consistency and realism in medical images. We introduce a new perceptual metric tailored for medical images: Radiomic Feature Distance (RaD), which utilizes standardized, clinically meaningful and interpretable image features. We show that RaD is superior to other metrics for out-of-domain (OOD) detection in a variety of experiments. Furthermore, RaD outperforms previous perceptual metrics (FID, KID, etc.) for image-to-image translation by correlating more strongly with downstream task performance as well as anatomical consistency and realism, and shows similar utility for evaluating unconditional image generation. RaD also offers additional benefits such as interpretability, as well as stability and computational efficiency at low sample sizes. Our results are supported by broad experiments spanning four multi-domain medical image datasets, nine downstream tasks, six image translation models, and other factors, highlighting the broad potential of RaD for medical image analysis.
The Impact of Scanner Domain Shift on Deep Learning Performance in Medical Imaging: an Experimental Study
Sep 06, 2024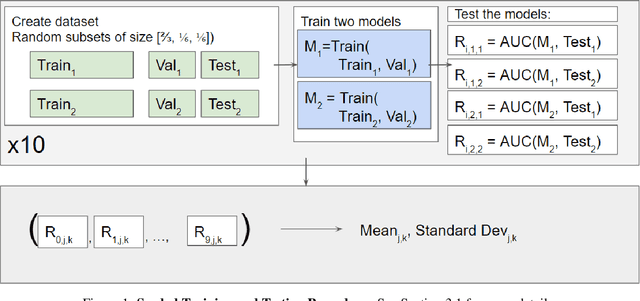
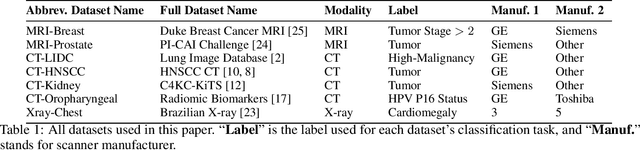
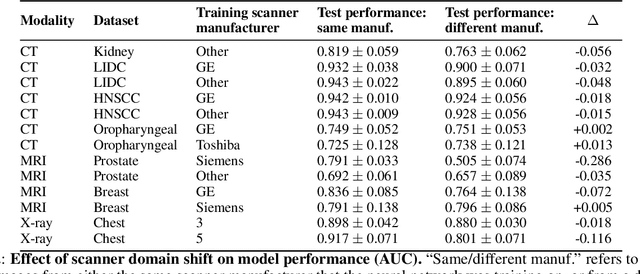
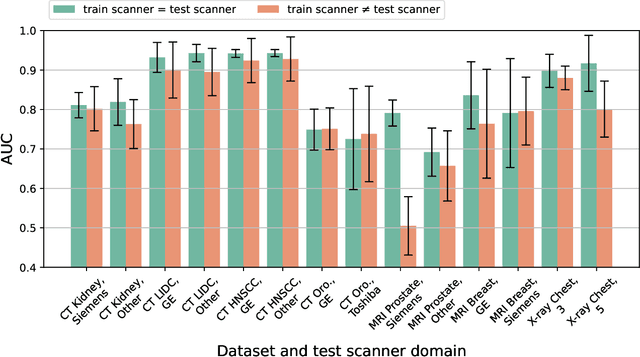
Purpose: Medical images acquired using different scanners and protocols can differ substantially in their appearance. This phenomenon, scanner domain shift, can result in a drop in the performance of deep neural networks which are trained on data acquired by one scanner and tested on another. This significant practical issue is well-acknowledged, however, no systematic study of the issue is available across different modalities and diagnostic tasks. Materials and Methods: In this paper, we present a broad experimental study evaluating the impact of scanner domain shift on convolutional neural network performance for different automated diagnostic tasks. We evaluate this phenomenon in common radiological modalities, including X-ray, CT, and MRI. Results: We find that network performance on data from a different scanner is almost always worse than on same-scanner data, and we quantify the degree of performance drop across different datasets. Notably, we find that this drop is most severe for MRI, moderate for X-ray, and quite small for CT, on average, which we attribute to the standardized nature of CT acquisition systems which is not present in MRI or X-ray. We also study how injecting varying amounts of target domain data into the training set, as well as adding noise to the training data, helps with generalization. Conclusion: Our results provide extensive experimental evidence and quantification of the extent of performance drop caused by scanner domain shift in deep learning across different modalities, with the goal of guiding the future development of robust deep learning models for medical image analysis.
Pre-processing and Compression: Understanding Hidden Representation Refinement Across Imaging Domains via Intrinsic Dimension
Aug 15, 2024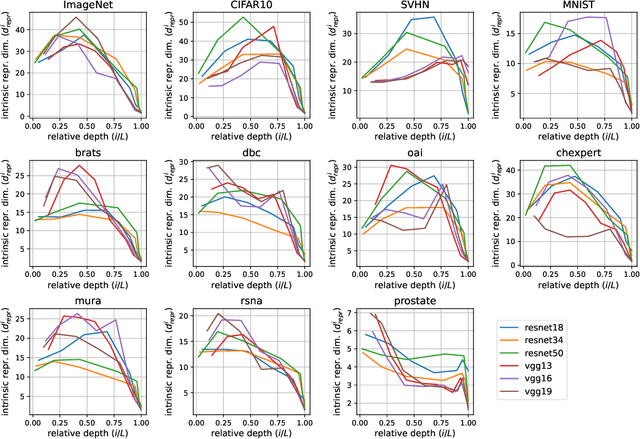

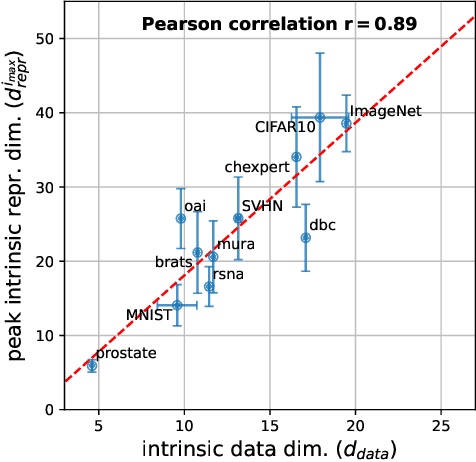

In recent years, there has been interest in how geometric properties such as intrinsic dimension (ID) of a neural network's hidden representations evolve through its layers, and how such properties are predictive of important model behavior such as generalization ability. However, evidence has begun to emerge that such behavior can change significantly depending on the domain of the network's training data, such as natural versus medical images. Here, we further this inquiry by exploring how the ID of a network's learned representations evolves through its layers, in essence, characterizing how the network successively refines the information content of input data to be used for predictions. Analyzing eleven natural and medical image datasets across six network architectures, we find that the shape of this ID evolution curve differs noticeably between natural and medical image models: medical image models peak in representation ID earlier in the network, implying a difference in the image features and their abstractness that are typically used for downstream tasks in these domains. Additionally, we discover a strong correlation of this peak representation ID with the ID of the data in its input space, implying that the intrinsic information content of a model's learned representations is guided by that of the data it was trained on. Overall, our findings emphasize notable discrepancies in network behavior between natural and non-natural imaging domains regarding hidden representation information content, and provide further insights into how a network's learned features are shaped by its training data.