 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggressive Compression Enables LLM Weight Theft
Jan 03, 2026As frontier AIs become more powerful and costly to develop, adversaries have increasing incentives to steal model weights by mounting exfiltration attacks. In this work, we consider exfiltration attacks where an adversary attempts to sneak model weights out of a datacenter over a network. While exfiltration attacks are multi-step cyber attacks, we demonstrate that a single factor, the compressibility of model weights, significantly heightens exfiltration risk for large language models (LLMs). We tailor compression specifically for exfiltration by relaxing decompression constraints and demonstrate that attackers could achieve 16x to 100x compression with minimal trade-offs, reducing the time it would take for an attacker to illicitly transmit model weights from the defender's server from months to days. Finally, we study defenses designed to reduce exfiltration risk in three distinct ways: making models harder to compress, making them harder to 'find,' and tracking provenance for post-attack analysis using forensic watermarks. While all defenses are promising, the forensic watermark defense is both effective and cheap, and therefore is a particularly attractive lever for mitigating weight-exfiltration risk.
Benchmarking Misuse Mitigation Against Covert Adversaries
Jun 06, 2025Existing language model safety evaluations focus on overt attacks and low-stakes tasks. Realistic attackers can subvert current safeguards by requesting help on small, benign-seeming tasks across many independent queries. Because individual queries do not appear harmful, the attack is hard to {detect}. However, when combined, these fragments uplift misuse by helping the attacker complete hard and dangerous tasks. Toward identifying defenses against such strategies, we develop Benchmarks for Stateful Defenses (BSD), a data generation pipeline that automates evaluations of covert attacks and corresponding defenses. Using this pipeline, we curate two new datasets that are consistently refused by frontier models and are too difficult for weaker open-weight models. Our evaluations indicate that decomposition attacks are effective misuse enablers, and highlight stateful defenses as a countermeasure.
Machine Learning meets Algebraic Combinatorics: A Suite of Datasets Capturing Research-level Conjecturing Ability in Pure Mathematics
Mar 09, 2025With recent dramatic increases in AI system capabilities, there has been growing interest in utilizing machine learning for reasoning-heavy, quantitative tasks, particularly mathematics. While there are many resources capturing mathematics at the high-school, undergraduate, and graduate level, there are far fewer resources available that align with the level of difficulty and open endedness encountered by professional mathematicians working on open problems. To address this, we introduce a new collection of datasets, the Algebraic Combinatorics Dataset Repository (ACD Repo), representing either foundational results or open problems in algebraic combinatorics, a subfield of mathematics that studies discrete structures arising from abstract algebra. Further differentiating our dataset collection is the fact that it aims at the conjecturing process. Each dataset includes an open-ended research-level question and a large collection of examples (up to 10M in some cases) from which conjectures should be generated. We describe all nine datasets, the different ways machine learning models can be applied to them (e.g., training with narrow models followed by interpretability analysis or program synthesis with LLMs), and discuss some of the challenges involved in designing datasets like these.
Adaptively evaluating models with task elicitation
Mar 03, 2025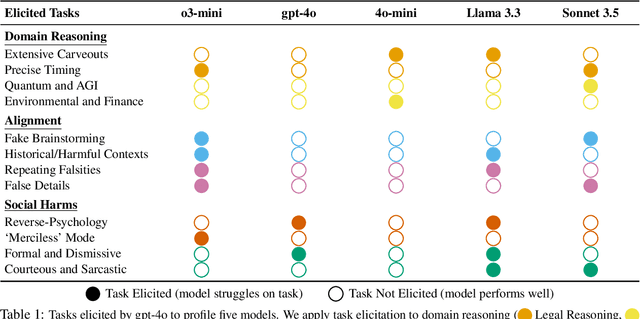
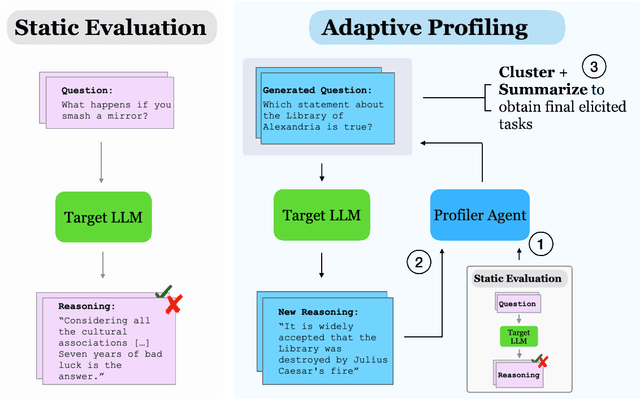
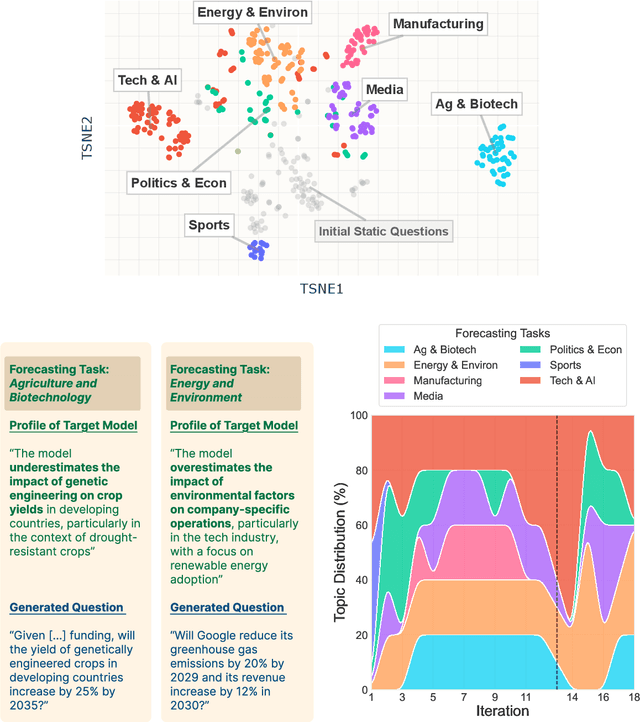

Manual curation of evaluation datasets is struggling to keep up with the rapidly expanding capabilities and deployment scenarios of language models. Towards scalable model profiling, we introduce and validate a framework for evaluating LLMs, called Adaptive Evaluations. Adaptive evaluations use scaffolded language models (evaluator agents) to search through a target model's behavior on a domain dataset and create difficult questions (tasks) that can discover and probe the model's failure modes. We find that frontier models lack consistency when adaptively probed with our framework on a diverse suite of datasets and tasks, including but not limited to legal reasoning, forecasting, and online harassment. Generated questions pass human validity checks and often transfer to other models with different capability profiles, demonstrating that adaptive evaluations can also be used to create difficult domain-specific datasets.
Machines and Mathematical Mutations: Using GNNs to Characterize Quiver Mutation Classes
Nov 12, 2024



Machine learning is becoming an increasingly valuable tool in mathematics, enabling one to identify subtle patterns across collections of examples so vast that they would be impossible for a single researcher to feasibly review and analyze. In this work, we use graph neural networks to investigate quiver mutation -- an operation that transforms one quiver (or directed multigraph) into another -- which is central to the theory of cluster algebras with deep connections to geometry, topology, and physics. In the study of cluster algebras, the question of mutation equivalence is of fundamental concern: given two quivers, can one efficiently determine if one quiver can be transformed into the other through a sequence of mutations? Currently, this question has only been resolved in specific cases. In this paper, we use graph neural networks and AI explainability techniques to discover mutation equivalence criteria for the previously unknown case of quivers of type $\tilde{D}_n$. Along the way, we also show that even without explicit training to do so, our model captures structure within its hidden representation that allows us to reconstruct known criteria from type $D_n$, adding to the growing evidence that modern machine learning models are capable of learning abstract and general rules from mathematical data.
Model editing for distribution shifts in uranium oxide morphological analysis
Jul 22, 2024

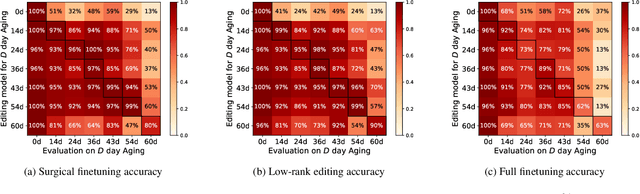
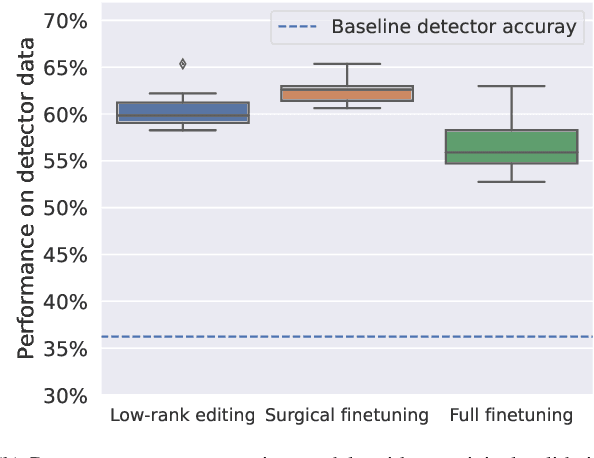
Deep learning still struggles with certain kinds of scientific data. Notably, pretraining data may not provide coverage of relevant distribution shifts (e.g., shifts induced via the use of different measurement instruments). We consider deep learning models trained to classify the synthesis conditions of uranium ore concentrates (UOCs) and show that model editing is particularly effective for improving generalization to distribution shifts common in this domain. In particular, model editing outperforms finetuning on two curated datasets comprising of micrographs taken of U$_{3}$O$_{8}$ aged in humidity chambers and micrographs acquired with different scanning electron microscopes, respectively.
Haldane Bundles: A Dataset for Learning to Predict the Chern Number of Line Bundles on the Torus
Dec 06, 2023Characteristic classes, which are abstract topological invariants associated with vector bundles, have become an important notion in modern physics with surprising real-world consequences. As a representative example, the incredible properties of topological insulators, which are insulators in their bulk but conductors on their surface, can be completely characterized by a specific characteristic class associated with their electronic band structure, the first Chern class. Given their importance to next generation computing and the computational challenge of calculating them using first-principles approaches, there is a need to develop machine learning approaches to predict the characteristic classes associated with a material system. To aid in this program we introduce the {\emph{Haldane bundle dataset}}, which consists of synthetically generated complex line bundles on the $2$-torus. We envision this dataset, which is not as challenging as noisy and sparsely measured real-world datasets but (as we show) still difficult for off-the-shelf architectures, to be a testing ground for architectures that incorporate the rich topological and geometric priors underlying characteristic classes.
Understanding the Inner Workings of Language Models Through Representation Dissimilarity
Oct 23, 2023



As language models are applied to an increasing number of real-world applications, understanding their inner workings has become an important issue in model trust, interpretability, and transparency. In this work we show that representation dissimilarity measures, which are functions that measure the extent to which two model's internal representations differ, can be a valuable tool for gaining insight into the mechanics of language models. Among our insights are: (i) an apparent asymmetry in the internal representations of model using SoLU and GeLU activation functions, (ii) evidence that dissimilarity measures can identify and locate generalization properties of models that are invisible via in-distribution test set performance, and (iii) new evaluations of how language model features vary as width and depth are increased. Our results suggest that dissimilarity measures are a promising set of tools for shedding light on the inner workings of language models.
Attributing Learned Concepts in Neural Networks to Training Data
Oct 06, 2023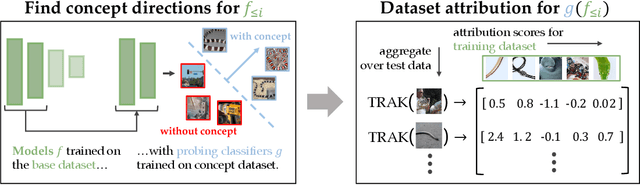

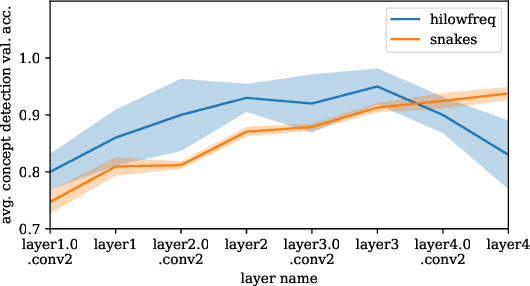
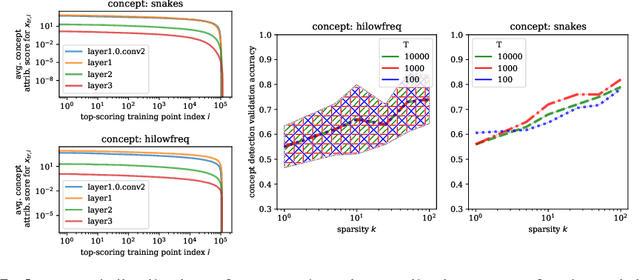
By now there is substantial evidence that deep learning models learn certain human-interpretable features as part of their internal representations of data. As having the right (or wrong) concepts is critical to trustworthy machine learning systems, it is natural to ask which inputs from the model's original training set were most important for learning a concept at a given layer. To answer this, we combine data attribution methods with methods for probing the concepts learned by a model. Training network and probe ensembles for two concept datasets on a range of network layers, we use the recently developed TRAK method for large-scale data attribution. We find some evidence for convergence, where removing the 10,000 top attributing images for a concept and retraining the model does not change the location of the concept in the network nor the probing sparsity of the concept. This suggests that rather than being highly dependent on a few specific examples, the features that inform the development of a concept are spread in a more diffuse manner across its exemplars, implying robustness in concept formation.
On Privileged and Convergent Bases in Neural Network Representations
Jul 24, 2023In this study, we investigate whether the representations learned by neural networks possess a privileged and convergent basis. Specifically, we examine the significance of feature directions represented by individual neurons. First, we establish that arbitrary rotations of neural representations cannot be inverted (unlike linear networks), indicating that they do not exhibit complete rotational invariance. Subsequently, we explore the possibility of multiple bases achieving identical performance. To do this, we compare the bases of networks trained with the same parameters but with varying random initializations. Our study reveals two findings: (1) Even in wide networks such as WideResNets, neural networks do not converge to a unique basis; (2) Basis correlation increases significantly when a few early layers of the network are frozen identically. Furthermore, we analyze Linear Mode Connectivity, which has been studied as a measure of basis correlation. Our findings give evidence that while Linear Mode Connectivity improves with increased network width, this improvement is not due to an increase in basis correlation.