 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOscillator-Based Associative Memory with Exponential Capacity: Theory, Algorithms, and Hardware Implementation
Apr 01, 2026Associative memory systems enable content-addressable storage and retrieval of patterns, a capability central to biological neural computation and artificial intelligence. Classical implementations such as Hopfield networks face fundamental limitations in memory capacity, scaling at most linearly with network size. We present an associative memory architecture based on Kuramoto oscillator networks with honeycomb topology in which memories are encoded as stable phase-locked configurations. The honeycomb network consists of multiple cycles that share nodes in a chain-like arrangement, creating a one-dimensional lattice of chained+loops. We prove that this architecture achieves exponential memory capacity: a network of $N$ oscillators can store $(2\lceil n_c/4 \rceil - 1)^m$ distinct patterns, where $m$ honeycomb cycles each contain $n_c$ oscillators. Moreover, we fully characterize all stable configurations and prove that each memory's basin of attraction maintains a guaranteed minimum size independent of network scale. Simulations using charge-density-wave (CDW) oscillators validate predicted phase-locking behavior, demonstrating practical realizability in neuromorphic hardware.
Model editing for distribution shifts in uranium oxide morphological analysis
Jul 22, 2024

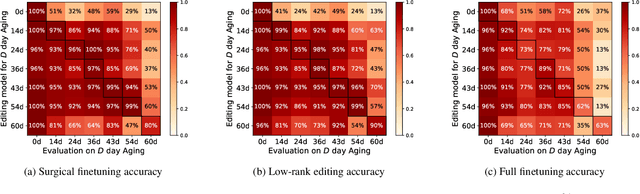
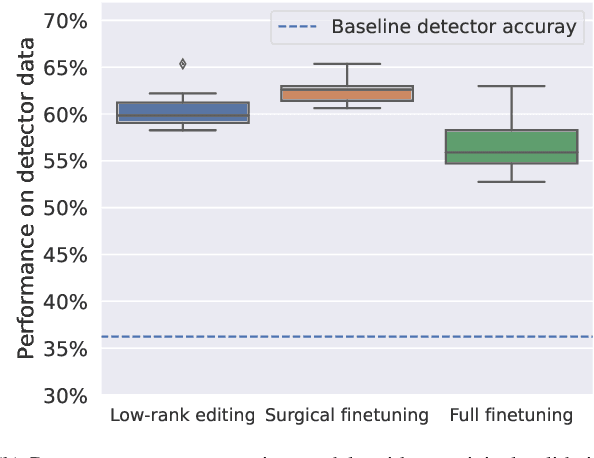
Deep learning still struggles with certain kinds of scientific data. Notably, pretraining data may not provide coverage of relevant distribution shifts (e.g., shifts induced via the use of different measurement instruments). We consider deep learning models trained to classify the synthesis conditions of uranium ore concentrates (UOCs) and show that model editing is particularly effective for improving generalization to distribution shifts common in this domain. In particular, model editing outperforms finetuning on two curated datasets comprising of micrographs taken of U$_{3}$O$_{8}$ aged in humidity chambers and micrographs acquired with different scanning electron microscopes, respectively.
Neural Differential Algebraic Equations
Mar 19, 2024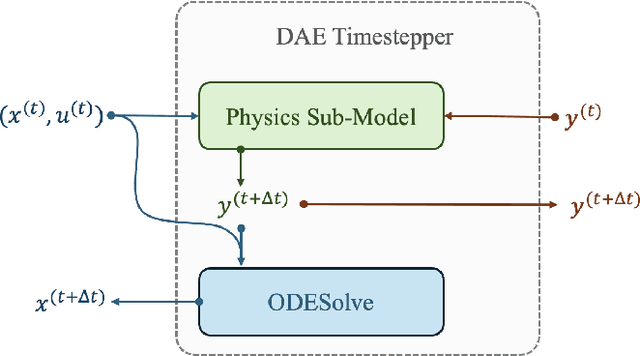
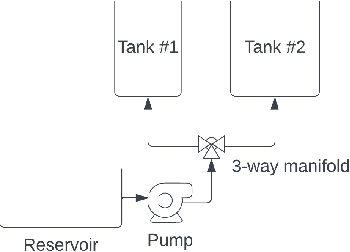
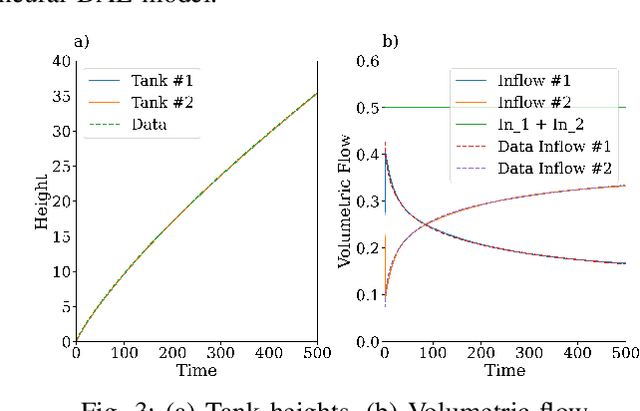
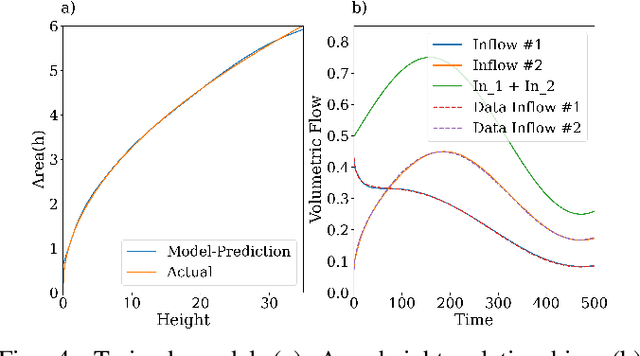
Differential-Algebraic Equations (DAEs) describe the temporal evolution of systems that obey both differential and algebraic constraints. Of particular interest are systems that contain implicit relationships between their components, such as conservation relationships. Here, we present Neural Differential-Algebraic Equations (NDAEs) suitable for data-driven modeling of DAEs. This methodology is built upon the concept of the Universal Differential Equation; that is, a model constructed as a system of Neural Ordinary Differential Equations informed by theory from particular science domains. In this work, we show that the proposed NDAEs abstraction is suitable for relevant system-theoretic data-driven modeling tasks. Presented examples include (i) the inverse problem of tank-manifold dynamics and (ii) discrepancy modeling of a network of pumps, tanks, and pipes. Our experiments demonstrate the proposed method's robustness to noise and extrapolation ability to (i) learn the behaviors of the system components and their interaction physics and (ii) disambiguate between data trends and mechanistic relationships contained in the system.
Attributing Learned Concepts in Neural Networks to Training Data
Oct 06, 2023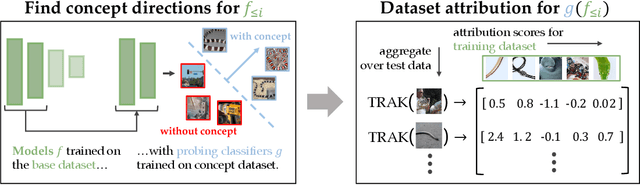

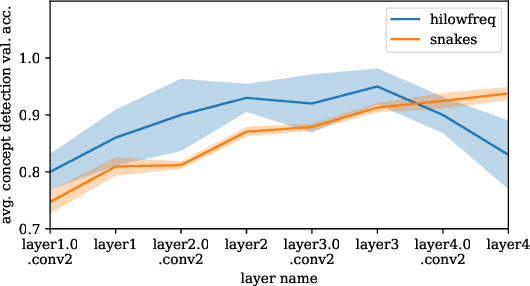
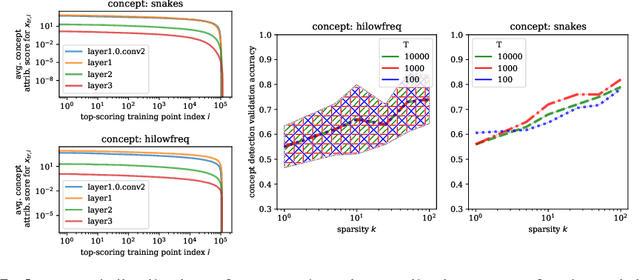
By now there is substantial evidence that deep learning models learn certain human-interpretable features as part of their internal representations of data. As having the right (or wrong) concepts is critical to trustworthy machine learning systems, it is natural to ask which inputs from the model's original training set were most important for learning a concept at a given layer. To answer this, we combine data attribution methods with methods for probing the concepts learned by a model. Training network and probe ensembles for two concept datasets on a range of network layers, we use the recently developed TRAK method for large-scale data attribution. We find some evidence for convergence, where removing the 10,000 top attributing images for a concept and retraining the model does not change the location of the concept in the network nor the probing sparsity of the concept. This suggests that rather than being highly dependent on a few specific examples, the features that inform the development of a concept are spread in a more diffuse manner across its exemplars, implying robustness in concept formation.
Experimental Observations of the Topology of Convolutional Neural Network Activations
Dec 01, 2022
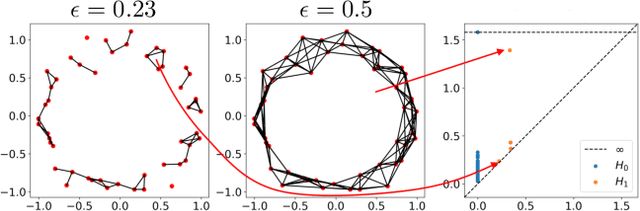
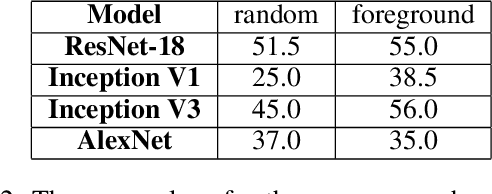
Topological data analysis (TDA) is a branch of computational mathematics, bridging algebraic topology and data science, that provides compact, noise-robust representations of complex structures. Deep neural networks (DNNs) learn millions of parameters associated with a series of transformations defined by the model architecture, resulting in high-dimensional, difficult-to-interpret internal representations of input data. As DNNs become more ubiquitous across multiple sectors of our society, there is increasing recognition that mathematical methods are needed to aid analysts, researchers, and practitioners in understanding and interpreting how these models' internal representations relate to the final classification. In this paper, we apply cutting edge techniques from TDA with the goal of gaining insight into the interpretability of convolutional neural networks used for image classification. We use two common TDA approaches to explore several methods for modeling hidden-layer activations as high-dimensional point clouds, and provide experimental evidence that these point clouds capture valuable structural information about the model's process. First, we demonstrate that a distance metric based on persistent homology can be used to quantify meaningful differences between layers, and we discuss these distances in the broader context of existing representational similarity metrics for neural network interpretability. Second, we show that a mapper graph can provide semantic insight into how these models organize hierarchical class knowledge at each layer. These observations demonstrate that TDA is a useful tool to help deep learning practitioners unlock the hidden structures of their models.
The SVD of Convolutional Weights: A CNN Interpretability Framework
Aug 14, 2022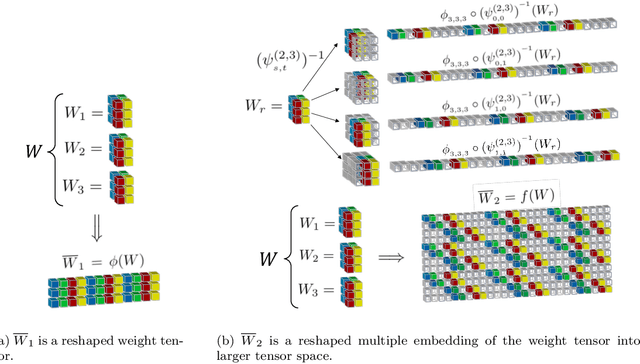
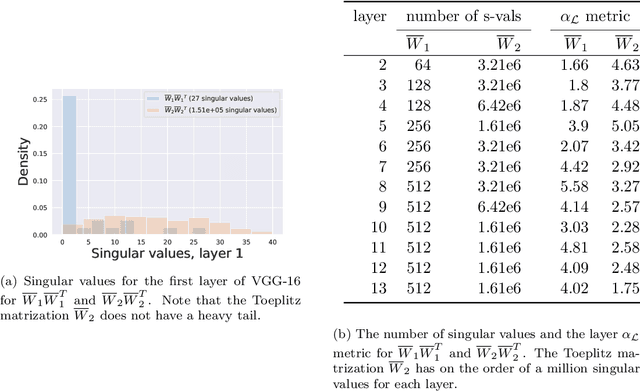
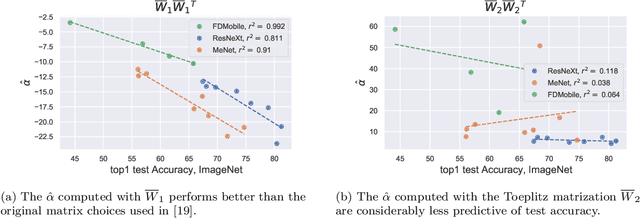
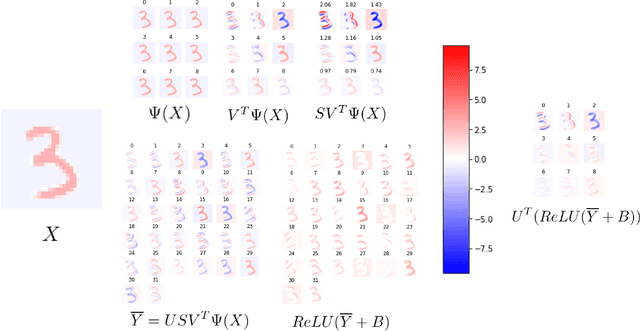
Deep neural networks used for image classification often use convolutional filters to extract distinguishing features before passing them to a linear classifier. Most interpretability literature focuses on providing semantic meaning to convolutional filters to explain a model's reasoning process and confirm its use of relevant information from the input domain. Fully connected layers can be studied by decomposing their weight matrices using a singular value decomposition, in effect studying the correlations between the rows in each matrix to discover the dynamics of the map. In this work we define a singular value decomposition for the weight tensor of a convolutional layer, which provides an analogous understanding of the correlations between filters, exposing the dynamics of the convolutional map. We validate our definition using recent results in random matrix theory. By applying the decomposition across the linear layers of an image classification network we suggest a framework against which interpretability methods might be applied using hypergraphs to model class separation. Rather than looking to the activations to explain the network, we use the singular vectors with the greatest corresponding singular values for each linear layer to identify those features most important to the network. We illustrate our approach with examples and introduce the DeepDataProfiler library, the analysis tool used for this study.