 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do Geometric Hallucination Detection Metrics Actually Measure?
Feb 09, 2026Hallucination remains a barrier to deploying generative models in high-consequence applications. This is especially true in cases where external ground truth is not readily available to validate model outputs. This situation has motivated the study of geometric signals in the internal state of an LLM that are predictive of hallucination and require limited external knowledge. Given that there are a range of factors that can lead model output to be called a hallucination (e.g., irrelevance vs incoherence), in this paper we ask what specific properties of a hallucination these geometric statistics actually capture. To assess this, we generate a synthetic dataset which varies distinct properties of output associated with hallucination. This includes output correctness, confidence, relevance, coherence, and completeness. We find that different geometric statistics capture different types of hallucinations. Along the way we show that many existing geometric detection methods have substantial sensitivity to shifts in task domain (e.g., math questions vs. history questions). Motivated by this, we introduce a simple normalization method to mitigate the effect of domain shift on geometric statistics, leading to AUROC gains of +34 points in multi-domain settings.
Which Way from B to A: The role of embedding geometry in image interpolation for Stable Diffusion
Nov 16, 2025It can be shown that Stable Diffusion has a permutation-invariance property with respect to the rows of Contrastive Language-Image Pretraining (CLIP) embedding matrices. This inspired the novel observation that these embeddings can naturally be interpreted as point clouds in a Wasserstein space rather than as matrices in a Euclidean space. This perspective opens up new possibilities for understanding the geometry of embedding space. For example, when interpolating between embeddings of two distinct prompts, we propose reframing the interpolation problem as an optimal transport problem. By solving this optimal transport problem, we compute a shortest path (or geodesic) between embeddings that captures a more natural and geometrically smooth transition through the embedding space. This results in smoother and more coherent intermediate (interpolated) images when rendered by the Stable Diffusion generative model. We conduct experiments to investigate this effect, comparing the quality of interpolated images produced using optimal transport to those generated by other standard interpolation methods. The novel optimal transport--based approach presented indeed gives smoother image interpolations, suggesting that viewing the embeddings as point clouds (rather than as matrices) better reflects and leverages the geometry of the embedding space.
STARS: Sensor-agnostic Transformer Architecture for Remote Sensing
Nov 08, 2024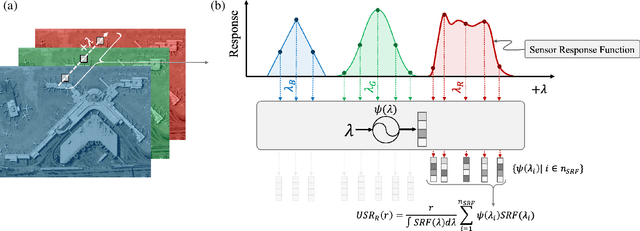

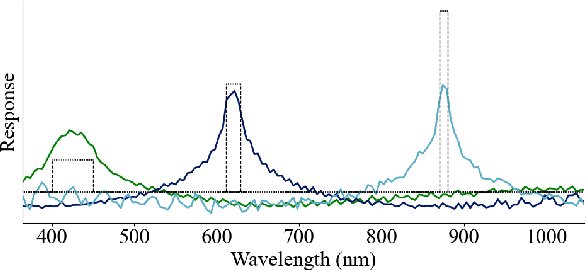

We present a sensor-agnostic spectral transformer as the basis for spectral foundation models. To that end, we introduce a Universal Spectral Representation (USR) that leverages sensor meta-data, such as sensing kernel specifications and sensing wavelengths, to encode spectra obtained from any spectral instrument into a common representation, such that a single model can ingest data from any sensor. Furthermore, we develop a methodology for pre-training such models in a self-supervised manner using a novel random sensor-augmentation and reconstruction pipeline to learn spectral features independent of the sensing paradigm. We demonstrate that our architecture can learn sensor independent spectral features that generalize effectively to sensors not seen during training. This work sets the stage for training foundation models that can both leverage and be effective for the growing diversity of spectral data.
ICML Topological Deep Learning Challenge 2024: Beyond the Graph Domain
Sep 08, 2024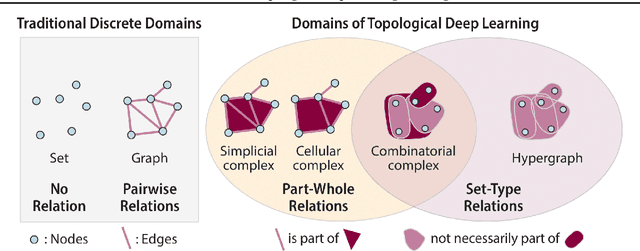
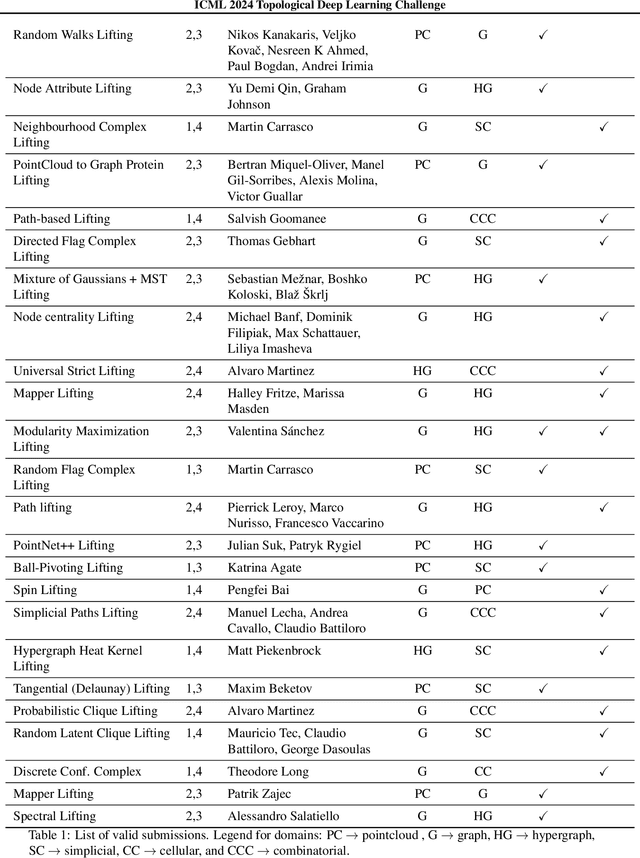
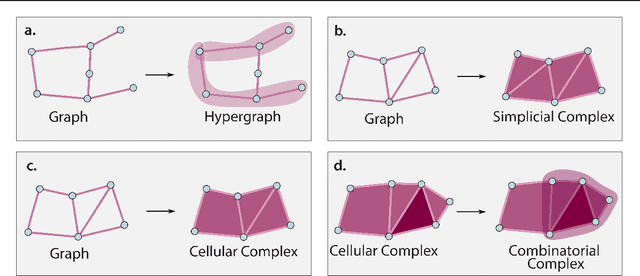
This paper describes the 2nd edition of the ICML Topological Deep Learning Challenge that was hosted within the ICML 2024 ELLIS Workshop on Geometry-grounded Representation Learning and Generative Modeling (GRaM). The challenge focused on the problem of representing data in different discrete topological domains in order to bridge the gap between Topological Deep Learning (TDL) and other types of structured datasets (e.g. point clouds, graphs). Specifically, participants were asked to design and implement topological liftings, i.e. mappings between different data structures and topological domains --like hypergraphs, or simplicial/cell/combinatorial complexes. The challenge received 52 submissions satisfying all the requirements. This paper introduces the main scope of the challenge, and summarizes the main results and findings.
Generalist Multimodal AI: A Review of Architectures, Challenges and Opportunities
Jun 08, 2024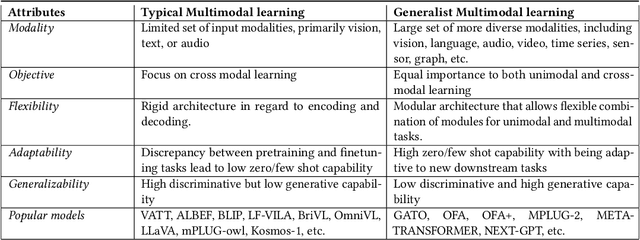
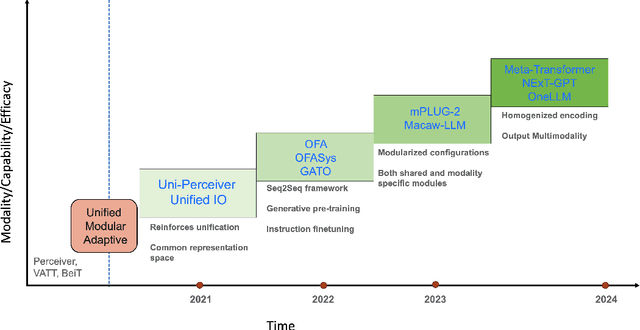
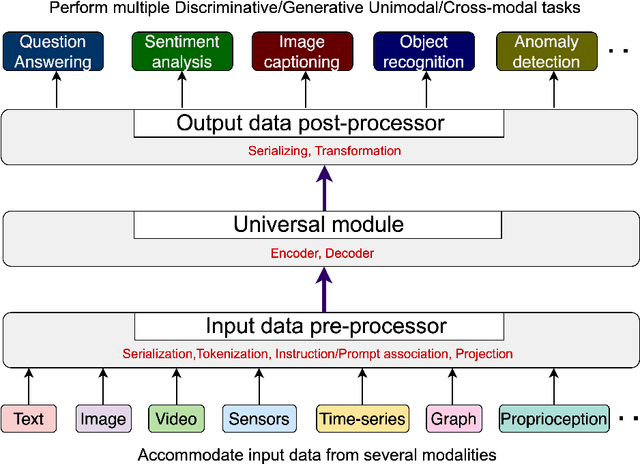
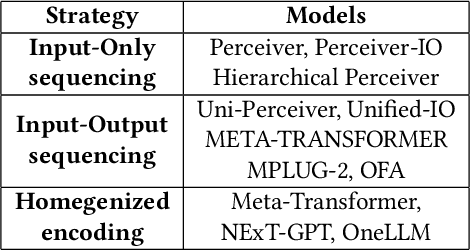
Multimodal models are expected to be a critical component to future advances in artificial intelligence. This field is starting to grow rapidly with a surge of new design elements motivated by the success of foundation models in natural language processing (NLP) and vision. It is widely hoped that further extending the foundation models to multiple modalities (e.g., text, image, video, sensor, time series, graph, etc.) will ultimately lead to generalist multimodal models, i.e. one model across different data modalities and tasks. However, there is little research that systematically analyzes recent multimodal models (particularly the ones that work beyond text and vision) with respect to the underling architecture proposed. Therefore, this work provides a fresh perspective on generalist multimodal models (GMMs) via a novel architecture and training configuration specific taxonomy. This includes factors such as Unifiability, Modularity, and Adaptability that are pertinent and essential to the wide adoption and application of GMMs. The review further highlights key challenges and prospects for the field and guide the researchers into the new advancements.
Data-Driven Invertible Neural Surrogates of Atmospheric Transmission
Apr 30, 2024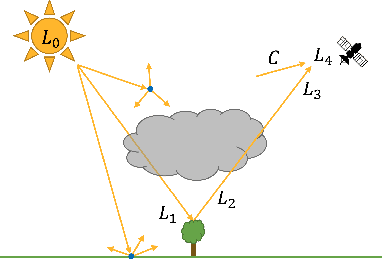
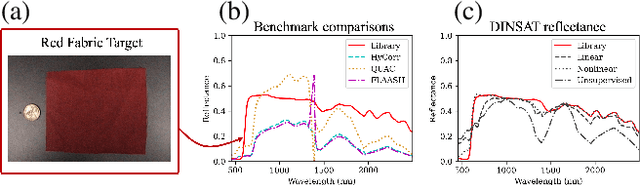
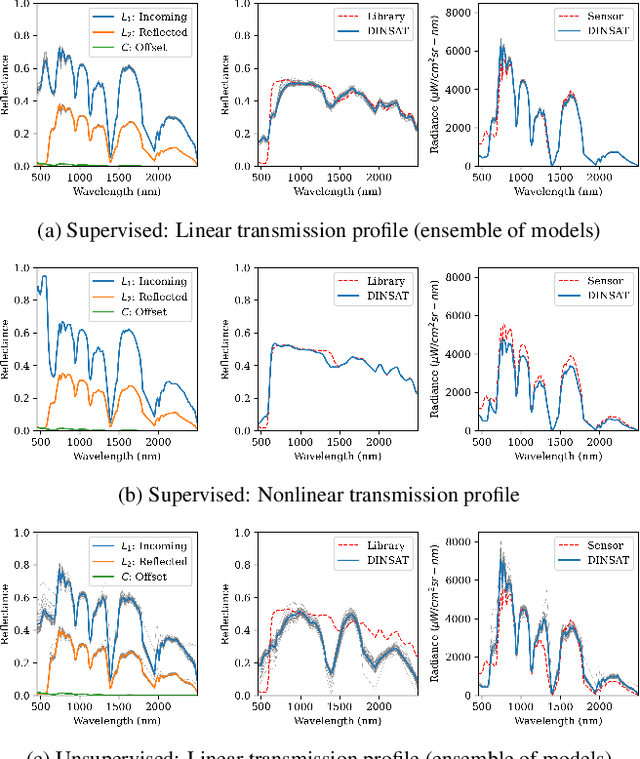
We present a framework for inferring an atmospheric transmission profile from a spectral scene. This framework leverages a lightweight, physics-based simulator that is automatically tuned - by virtue of autodifferentiation and differentiable programming - to construct a surrogate atmospheric profile to model the observed data. We demonstrate utility of the methodology by (i) performing atmospheric correction, (ii) recasting spectral data between various modalities (e.g. radiance and reflectance at the surface and at the sensor), and (iii) inferring atmospheric transmission profiles, such as absorbing bands and their relative magnitudes.
Haldane Bundles: A Dataset for Learning to Predict the Chern Number of Line Bundles on the Torus
Dec 06, 2023Characteristic classes, which are abstract topological invariants associated with vector bundles, have become an important notion in modern physics with surprising real-world consequences. As a representative example, the incredible properties of topological insulators, which are insulators in their bulk but conductors on their surface, can be completely characterized by a specific characteristic class associated with their electronic band structure, the first Chern class. Given their importance to next generation computing and the computational challenge of calculating them using first-principles approaches, there is a need to develop machine learning approaches to predict the characteristic classes associated with a material system. To aid in this program we introduce the {\emph{Haldane bundle dataset}}, which consists of synthetically generated complex line bundles on the $2$-torus. We envision this dataset, which is not as challenging as noisy and sparsely measured real-world datasets but (as we show) still difficult for off-the-shelf architectures, to be a testing ground for architectures that incorporate the rich topological and geometric priors underlying characteristic classes.
ICML 2023 Topological Deep Learning Challenge : Design and Results
Oct 02, 2023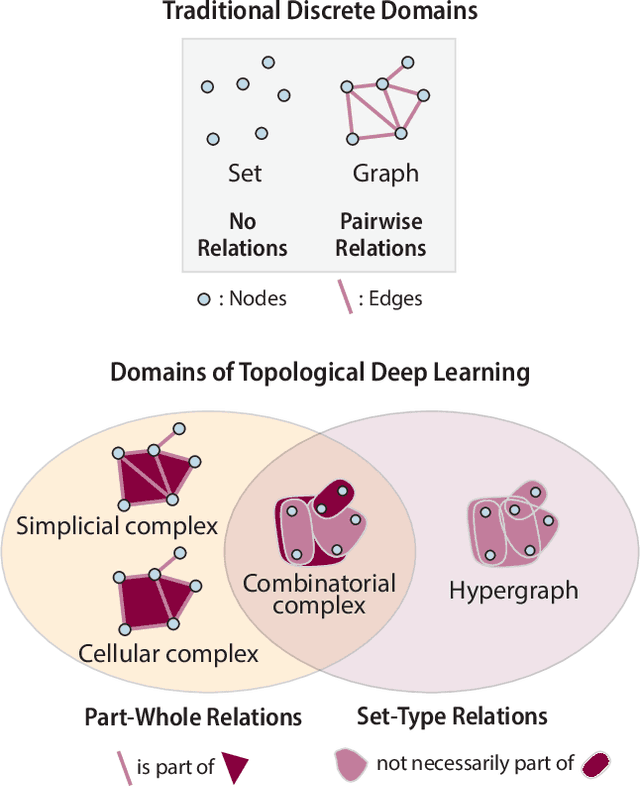
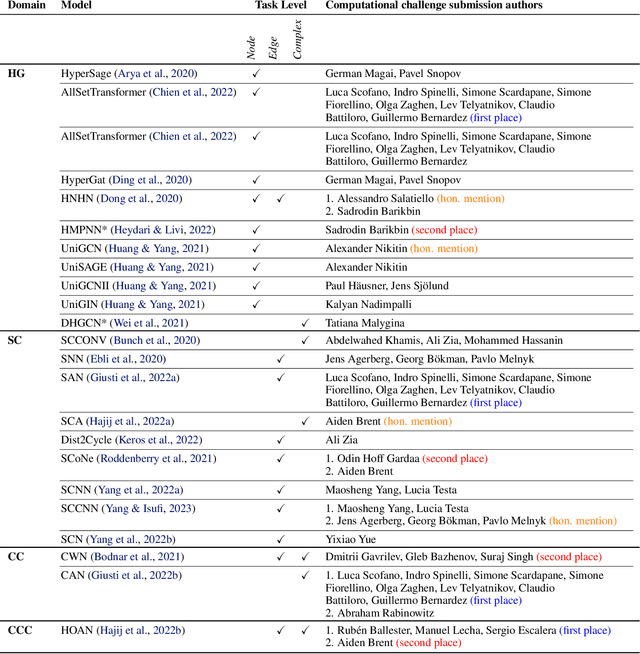
This paper presents the computational challenge on topological deep learning that was hosted within the ICML 2023 Workshop on Topology and Geometry in Machine Learning. The competition asked participants to provide open-source implementations of topological neural networks from the literature by contributing to the python packages TopoNetX (data processing) and TopoModelX (deep learning). The challenge attracted twenty-eight qualifying submissions in its two-month duration. This paper describes the design of the challenge and summarizes its main findings.
Reproducing Kernel Hilbert Space Pruning for Sparse Hyperspectral Abundance Prediction
Aug 16, 2023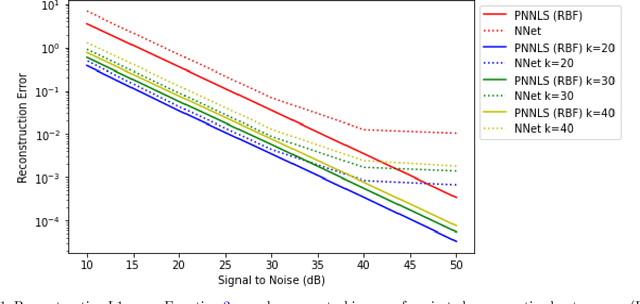
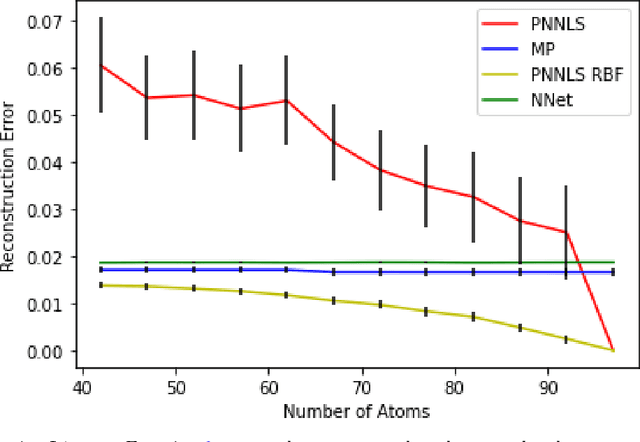
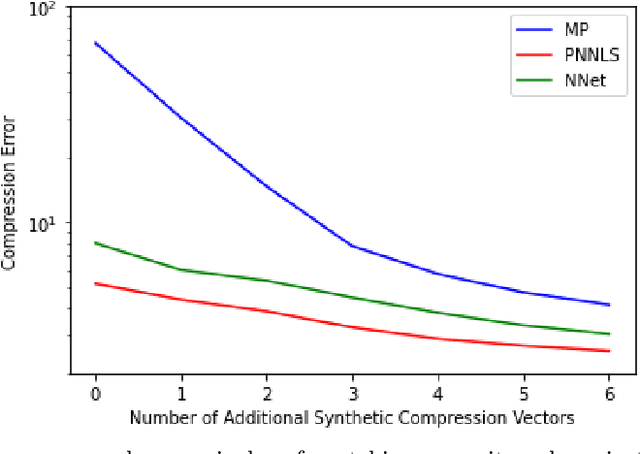
Hyperspectral measurements from long range sensors can give a detailed picture of the items, materials, and chemicals in a scene but analysis can be difficult, slow, and expensive due to high spatial and spectral resolutions of state-of-the-art sensors. As such, sparsity is important to enable the future of spectral compression and analytics. It has been observed that environmental and atmospheric effects, including scattering, can produce nonlinear effects posing challenges for existing source separation and compression methods. We present a novel transformation into Hilbert spaces for pruning and constructing sparse representations via non-negative least squares minimization. Then we introduce max likelihood compression vectors to decrease information loss. Our approach is benchmarked against standard pruning and least squares as well as deep learning methods. Our methods are evaluated in terms of overall spectral reconstruction error and compression rate using real and synthetic data. We find that pruning least squares methods converge quickly unlike matching pursuit methods. We find that Hilbert space pruning can reduce error by as much as 40% of the error of standard pruning and also outperform neural network autoencoders.
Neural frames: A Tool for Studying the Tangent Bundles Underlying Image Datasets and How Deep Learning Models Process Them
Nov 19, 2022The assumption that many forms of high-dimensional data, such as images, actually live on low-dimensional manifolds, sometimes known as the manifold hypothesis, underlies much of our intuition for how and why deep learning works. Despite the central role that they play in our intuition, data manifolds are surprisingly hard to measure in the case of high-dimensional, sparsely sampled image datasets. This is particularly frustrating since the capability to measure data manifolds would provide a revealing window into the inner workings and dynamics of deep learning models. Motivated by this, we introduce neural frames, a novel and easy to use tool inspired by the notion of a frame from differential geometry. Neural frames can be used to explore the local neighborhoods of data manifolds as they pass through the hidden layers of neural networks even when one only has a single datapoint available. We present a mathematical framework for neural frames and explore some of their properties. We then use them to make a range of observations about how modern model architectures and training routines, such as heavy augmentation and adversarial training, affect the local behavior of a model.