 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralist Multimodal AI: A Review of Architectures, Challenges and Opportunities
Paper and Code
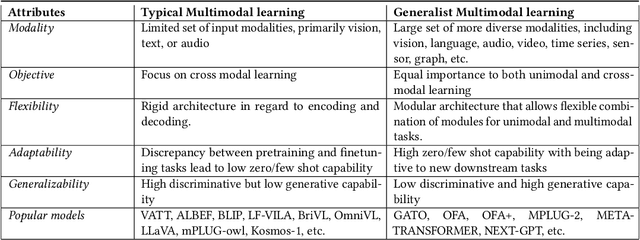
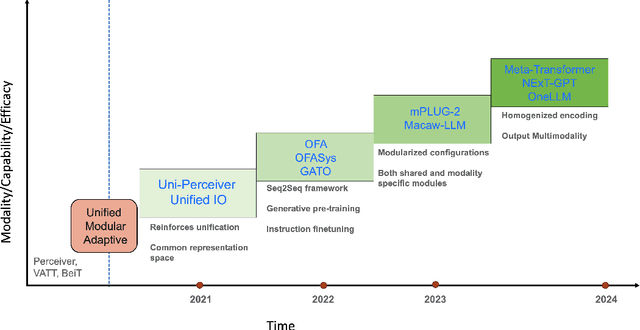
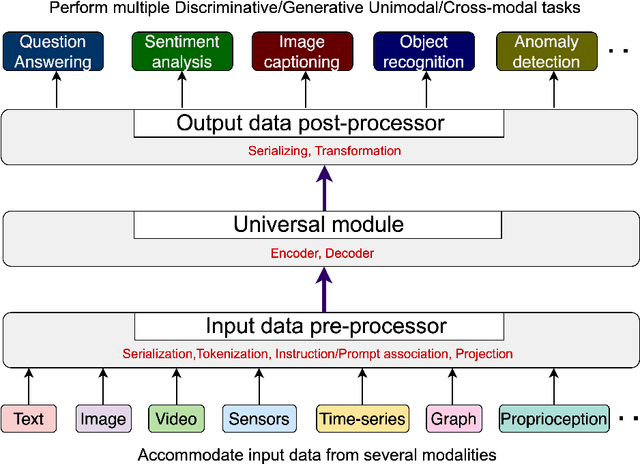
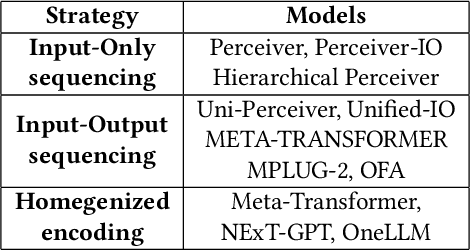
Multimodal models are expected to be a critical component to future advances in artificial intelligence. This field is starting to grow rapidly with a surge of new design elements motivated by the success of foundation models in natural language processing (NLP) and vision. It is widely hoped that further extending the foundation models to multiple modalities (e.g., text, image, video, sensor, time series, graph, etc.) will ultimately lead to generalist multimodal models, i.e. one model across different data modalities and tasks. However, there is little research that systematically analyzes recent multimodal models (particularly the ones that work beyond text and vision) with respect to the underling architecture proposed. Therefore, this work provides a fresh perspective on generalist multimodal models (GMMs) via a novel architecture and training configuration specific taxonomy. This includes factors such as Unifiability, Modularity, and Adaptability that are pertinent and essential to the wide adoption and application of GMMs. The review further highlights key challenges and prospects for the field and guide the researchers into the new advancements.