 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMG-Det: Foundation Model Guided Robust Object Detection
May 29, 2025

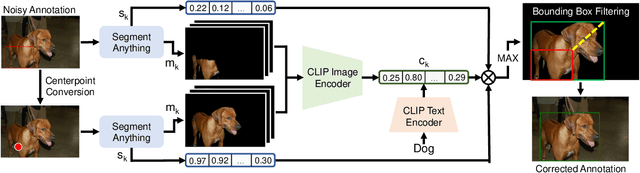

Collecting high quality data for object detection tasks is challenging due to the inherent subjectivity in labeling the boundaries of an object. This makes it difficult to not only collect consistent annotations across a dataset but also to validate them, as no two annotators are likely to label the same object using the exact same coordinates. These challenges are further compounded when object boundaries are partially visible or blurred, which can be the case in many domains. Training on noisy annotations significantly degrades detector performance, rendering them unusable, particularly in few-shot settings, where just a few corrupted annotations can impact model performance. In this work, we propose FMG-Det, a simple, efficient methodology for training models with noisy annotations. More specifically, we propose combining a multiple instance learning (MIL) framework with a pre-processing pipeline that leverages powerful foundation models to correct labels prior to training. This pre-processing pipeline, along with slight modifications to the detector head, results in state-of-the-art performance across a number of datasets, for both standard and few-shot scenarios, while being much simpler and more efficient than other approaches.
Foundation Models for Remote Sensing: An Analysis of MLLMs for Object Localization
Apr 14, 2025


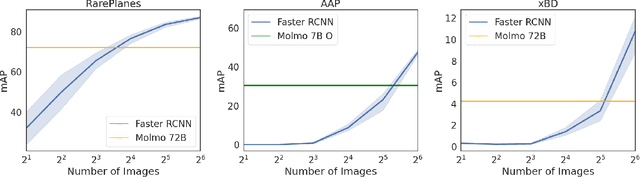
Multimodal large language models (MLLMs) have altered the landscape of computer vision, obtaining impressive results across a wide range of tasks, especially in zero-shot settings. Unfortunately, their strong performance does not always transfer to out-of-distribution domains, such as earth observation (EO) imagery. Prior work has demonstrated that MLLMs excel at some EO tasks, such as image captioning and scene understanding, while failing at tasks that require more fine-grained spatial reasoning, such as object localization. However, MLLMs are advancing rapidly and insights quickly become out-dated. In this work, we analyze more recent MLLMs that have been explicitly trained to include fine-grained spatial reasoning capabilities, benchmarking them on EO object localization tasks. We demonstrate that these models are performant in certain settings, making them well suited for zero-shot scenarios. Additionally, we provide a detailed discussion focused on prompt selection, ground sample distance (GSD) optimization, and analyzing failure cases. We hope that this work will prove valuable as others evaluate whether an MLLM is well suited for a given EO localization task and how to optimize it.
On the Promise for Assurance of Differentiable Neurosymbolic Reasoning Paradigms
Feb 13, 2025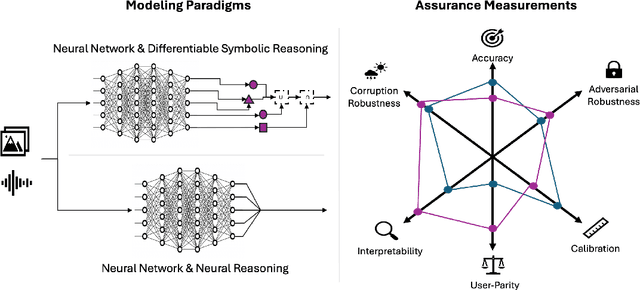
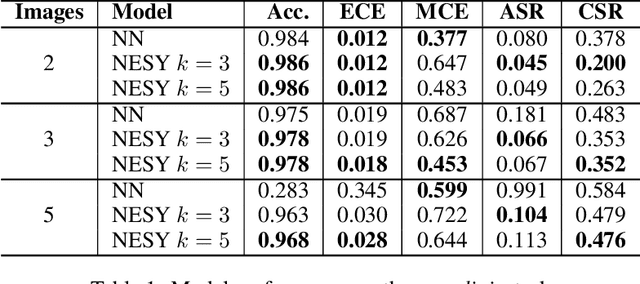
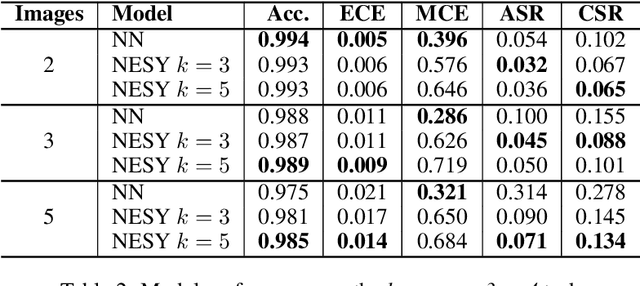
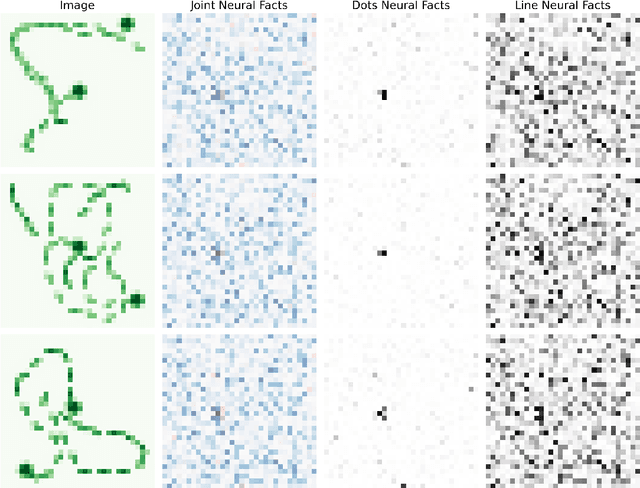
To create usable and deployable Artificial Intelligence (AI) systems, there requires a level of assurance in performance under many different conditions. Many times, deployed machine learning systems will require more classic logic and reasoning performed through neurosymbolic programs jointly with artificial neural network sensing. While many prior works have examined the assurance of a single component of the system solely with either the neural network alone or entire enterprise systems, very few works have examined the assurance of integrated neurosymbolic systems. Within this work, we assess the assurance of end-to-end fully differentiable neurosymbolic systems that are an emerging method to create data-efficient and more interpretable models. We perform this investigation using Scallop, an end-to-end neurosymbolic library, across classification and reasoning tasks in both the image and audio domains. We assess assurance across adversarial robustness, calibration, user performance parity, and interpretability of solutions for catching misaligned solutions. We find end-to-end neurosymbolic methods present unique opportunities for assurance beyond their data efficiency through our empirical results but not across the board. We find that this class of neurosymbolic models has higher assurance in cases where arithmetic operations are defined and where there is high dimensionality to the input space, where fully neural counterparts struggle to learn robust reasoning operations. We identify the relationship between neurosymbolic models' interpretability to catch shortcuts that later result in increased adversarial vulnerability despite performance parity. Finally, we find that the promise of data efficiency is typically only in the case of class imbalanced reasoning problems.
STARS: Sensor-agnostic Transformer Architecture for Remote Sensing
Nov 08, 2024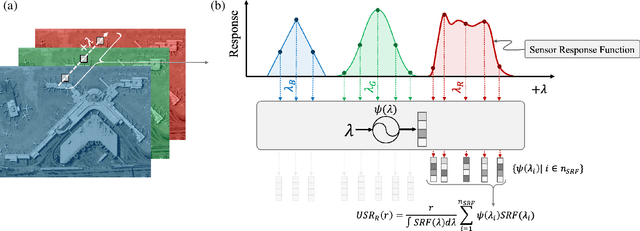

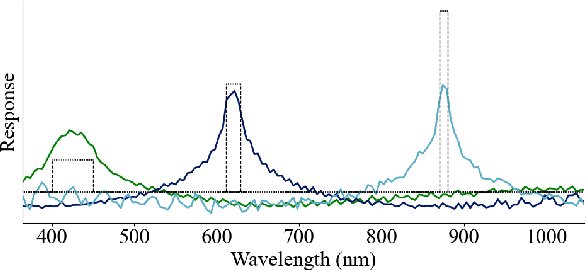

We present a sensor-agnostic spectral transformer as the basis for spectral foundation models. To that end, we introduce a Universal Spectral Representation (USR) that leverages sensor meta-data, such as sensing kernel specifications and sensing wavelengths, to encode spectra obtained from any spectral instrument into a common representation, such that a single model can ingest data from any sensor. Furthermore, we develop a methodology for pre-training such models in a self-supervised manner using a novel random sensor-augmentation and reconstruction pipeline to learn spectral features independent of the sensing paradigm. We demonstrate that our architecture can learn sensor independent spectral features that generalize effectively to sensors not seen during training. This work sets the stage for training foundation models that can both leverage and be effective for the growing diversity of spectral data.
Data-Driven Invertible Neural Surrogates of Atmospheric Transmission
Apr 30, 2024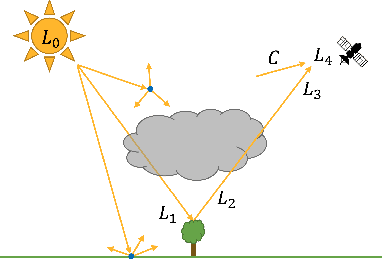
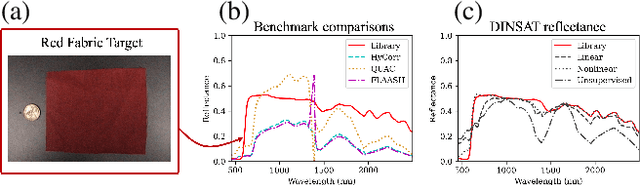
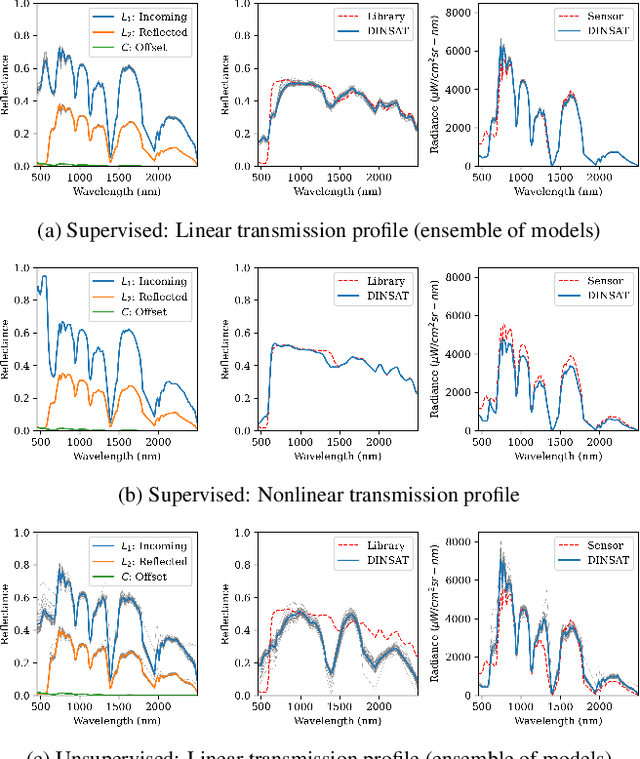
We present a framework for inferring an atmospheric transmission profile from a spectral scene. This framework leverages a lightweight, physics-based simulator that is automatically tuned - by virtue of autodifferentiation and differentiable programming - to construct a surrogate atmospheric profile to model the observed data. We demonstrate utility of the methodology by (i) performing atmospheric correction, (ii) recasting spectral data between various modalities (e.g. radiance and reflectance at the surface and at the sensor), and (iii) inferring atmospheric transmission profiles, such as absorbing bands and their relative magnitudes.
Reproducing Kernel Hilbert Space Pruning for Sparse Hyperspectral Abundance Prediction
Aug 16, 2023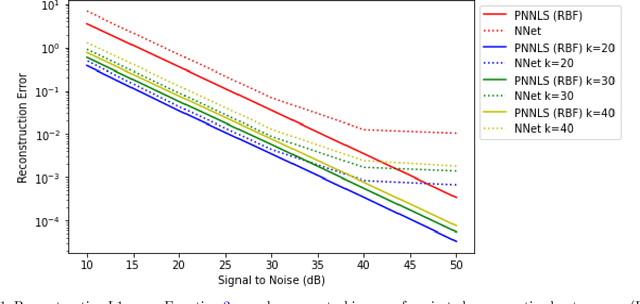
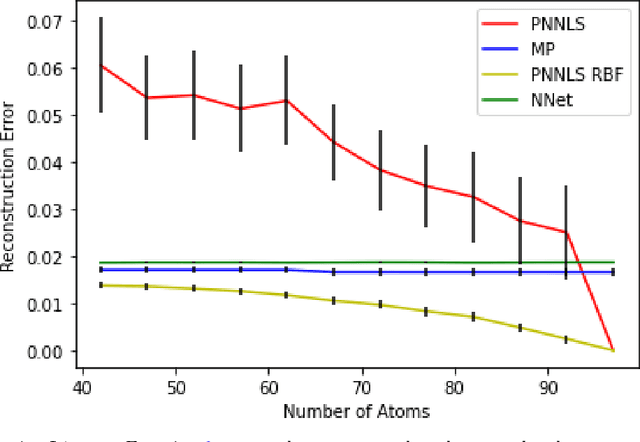
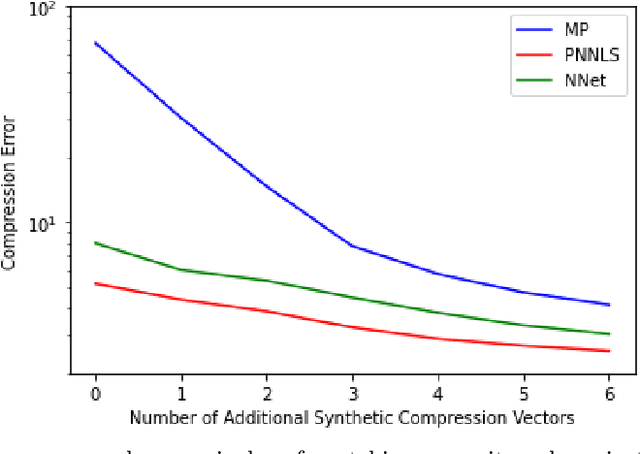
Hyperspectral measurements from long range sensors can give a detailed picture of the items, materials, and chemicals in a scene but analysis can be difficult, slow, and expensive due to high spatial and spectral resolutions of state-of-the-art sensors. As such, sparsity is important to enable the future of spectral compression and analytics. It has been observed that environmental and atmospheric effects, including scattering, can produce nonlinear effects posing challenges for existing source separation and compression methods. We present a novel transformation into Hilbert spaces for pruning and constructing sparse representations via non-negative least squares minimization. Then we introduce max likelihood compression vectors to decrease information loss. Our approach is benchmarked against standard pruning and least squares as well as deep learning methods. Our methods are evaluated in terms of overall spectral reconstruction error and compression rate using real and synthetic data. We find that pruning least squares methods converge quickly unlike matching pursuit methods. We find that Hilbert space pruning can reduce error by as much as 40% of the error of standard pruning and also outperform neural network autoencoders.
In What Ways Are Deep Neural Networks Invariant and How Should We Measure This?
Oct 07, 2022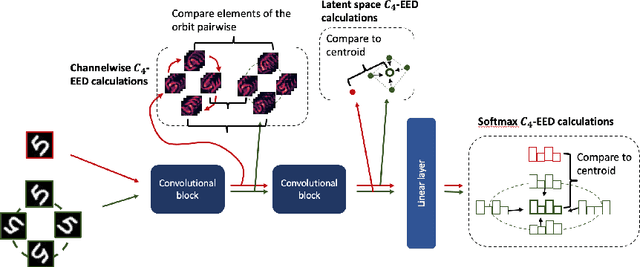
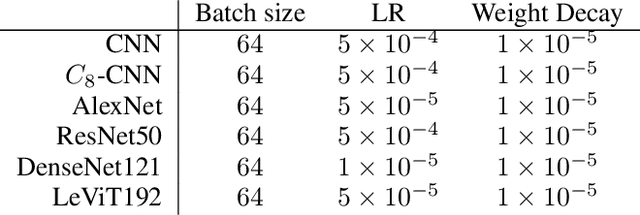
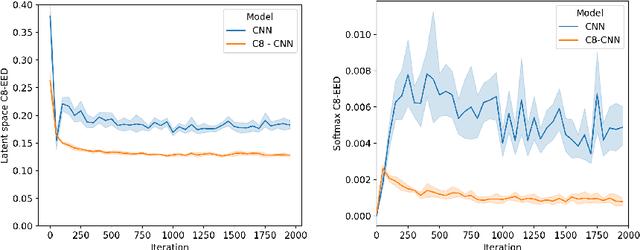
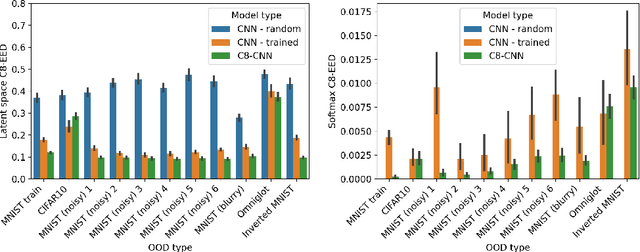
It is often said that a deep learning model is "invariant" to some specific type of transformation. However, what is meant by this statement strongly depends on the context in which it is made. In this paper we explore the nature of invariance and equivariance of deep learning models with the goal of better understanding the ways in which they actually capture these concepts on a formal level. We introduce a family of invariance and equivariance metrics that allows us to quantify these properties in a way that disentangles them from other metrics such as loss or accuracy. We use our metrics to better understand the two most popular methods used to build invariance into networks: data augmentation and equivariant layers. We draw a range of conclusions about invariance and equivariance in deep learning models, ranging from whether initializing a model with pretrained weights has an effect on a trained model's invariance, to the extent to which invariance learned via training can generalize to out-of-distribution data.
Reward-Free Attacks in Multi-Agent Reinforcement Learning
Dec 02, 2021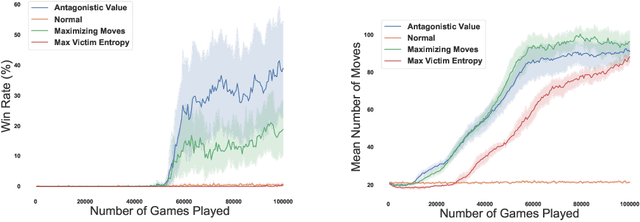

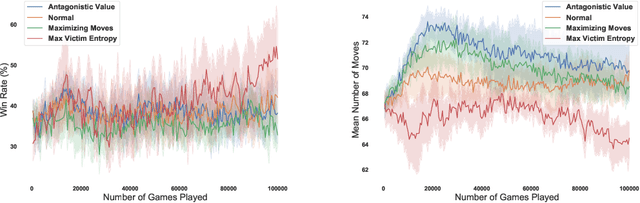

We investigate how effective an attacker can be when it only learns from its victim's actions, without access to the victim's reward. In this work, we are motivated by the scenario where the attacker wants to behave strategically when the victim's motivations are unknown. We argue that one heuristic approach an attacker can use is to maximize the entropy of the victim's policy. The policy is generally not obfuscated, which implies it may be extracted simply by passively observing the victim. We provide such a strategy in the form of a reward-free exploration algorithm that maximizes the attacker's entropy during the exploration phase, and then maximizes the victim's empirical entropy during the planning phase. In our experiments, the victim agents are subverted through policy entropy maximization, implying an attacker might not need access to the victim's reward to succeed. Hence, reward-free attacks, which are based only on observing behavior, show the feasibility of an attacker to act strategically without knowledge of the victim's motives even if the victim's reward information is protected.
Argumentative Topology: Finding Loop(holes) in Logic
Nov 17, 2020
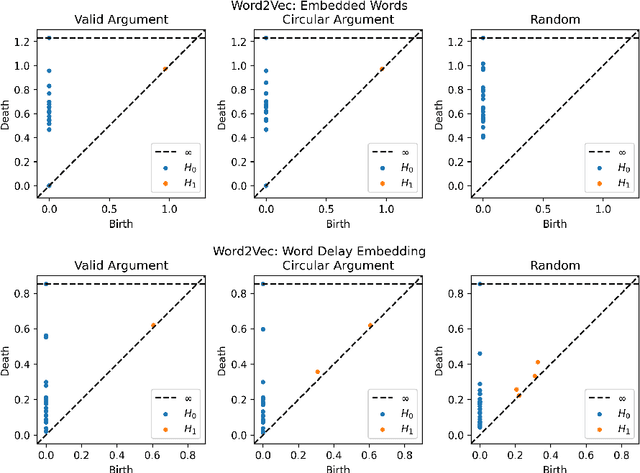
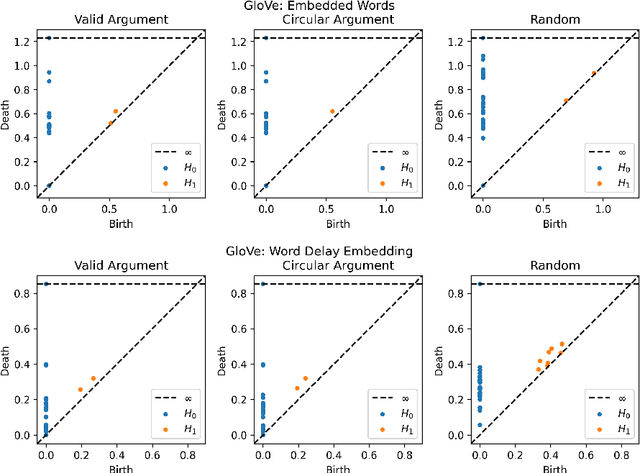
Advances in natural language processing have resulted in increased capabilities with respect to multiple tasks. One of the possible causes of the observed performance gains is the introduction of increasingly sophisticated text representations. While many of the new word embedding techniques can be shown to capture particular notions of sentiment or associative structures, we explore the ability of two different word embeddings to uncover or capture the notion of logical shape in text. To this end we present a novel framework that we call Topological Word Embeddings which leverages mathematical techniques in dynamical system analysis and data driven shape extraction (i.e. topological data analysis). In this preliminary work we show that using a topological delay embedding we are able to capture and extract a different, shape-based notion of logic aimed at answering the question "Can we find a circle in a circular argument?"
Gradual DropIn of Layers to Train Very Deep Neural Networks
Nov 22, 2015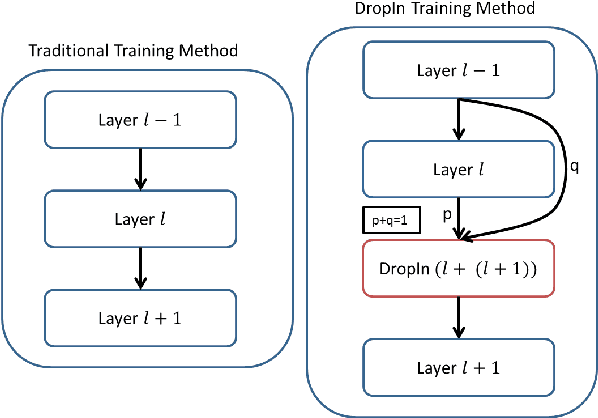

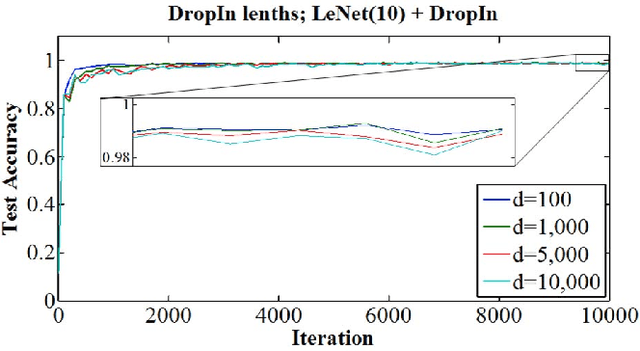
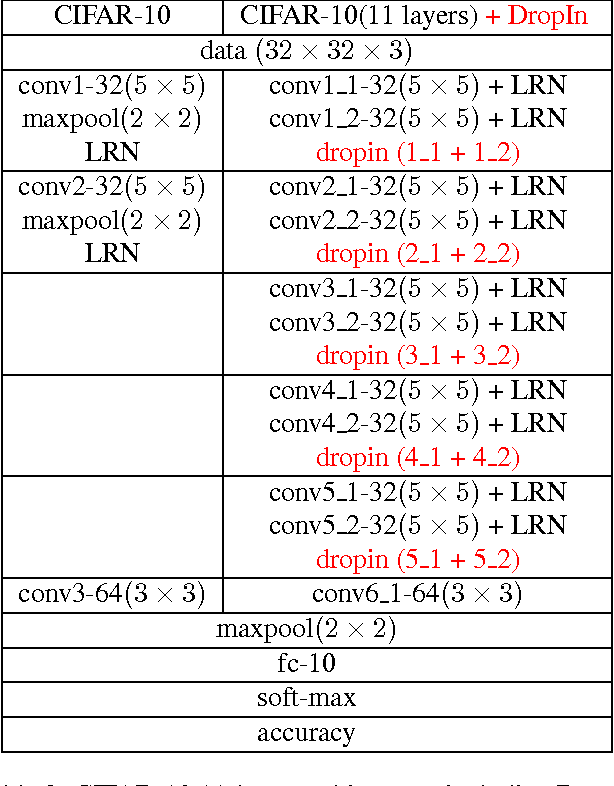
We introduce the concept of dynamically growing a neural network during training. In particular, an untrainable deep network starts as a trainable shallow network and newly added layers are slowly, organically added during training, thereby increasing the network's depth. This is accomplished by a new layer, which we call DropIn. The DropIn layer starts by passing the output from a previous layer (effectively skipping over the newly added layers), then increasingly including units from the new layers for both feedforward and backpropagation. We show that deep networks, which are untrainable with conventional methods, will converge with DropIn layers interspersed in the architecture. In addition, we demonstrate that DropIn provides regularization during training in an analogous way as dropout. Experiments are described with the MNIST dataset and various expanded LeNet architectures, CIFAR-10 dataset with its architecture expanded from 3 to 11 layers, and on the ImageNet dataset with the AlexNet architecture expanded to 13 layers and the VGG 16-layer architecture.