 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Framework for Two-Dimensional, Multi-Frequency Propagation Factor Estimation
May 21, 2025Accurately estimating the refractive environment over multiple frequencies within the marine atmospheric boundary layer is crucial for the effective deployment of radar technologies. Traditional parabolic equation simulations, while effective, can be computationally expensive and time-intensive, limiting their practical application. This communication explores a novel approach using deep neural networks to estimate the pattern propagation factor, a critical parameter for characterizing environmental impacts on signal propagation. Image-to-image translation generators designed to ingest modified refractivity data and generate predictions of pattern propagation factors over the same domain were developed. Findings demonstrate that deep neural networks can be trained to analyze multiple frequencies and reasonably predict the pattern propagation factor, offering an alternative to traditional methods.
Symmetry constrained neural networks for detection and localization of damage in metal plates
Sep 09, 2024The present paper is concerned with deep learning techniques applied to detection and localization of damage in a thin aluminum plate. We used data generated on a tabletop apparatus by mounting to the plate four piezoelectric transducers, each of which took turn to generate a Lamb wave that then traversed the region of interest before being received by the remaining three sensors. On training a neural network to analyze time-series data of the material response, which displayed damage-reflective features whenever the plate guided waves interacted with a contact load, we achieved a model that detected with greater than 99% accuracy in addition to a model that localized with $3.14 \pm 0.21$ mm mean distance error and captured more than 60% of test examples within the diffraction limit. For each task, the best-performing model was designed according to the inductive bias that our transducers were both similar and arranged in a square pattern on a nearly uniform plate.
General Cyclical Training of Neural Networks
Feb 17, 2022



This paper describes the principle of "General Cyclical Training" in machine learning, where training starts and ends with "easy training" and the "hard training" happens during the middle epochs. We propose several manifestations for training neural networks, including algorithmic examples (via hyper-parameters and loss functions), data-based examples, and model-based examples. Specifically, we introduce several novel techniques: cyclical weight decay, cyclical batch size, cyclical focal loss, cyclical softmax temperature, cyclical data augmentation, cyclical gradient clipping, and cyclical semi-supervised learning. In addition, we demonstrate that cyclical weight decay, cyclical softmax temperature, and cyclical gradient clipping (as three examples of this principle) are beneficial in the test accuracy performance of a trained model. Furthermore, we discuss model-based examples (such as pretraining and knowledge distillation) from the perspective of general cyclical training and recommend some changes to the typical training methodology. In summary, this paper defines the general cyclical training concept and discusses several specific ways in which this concept can be applied to training neural networks. In the spirit of reproducibility, the code used in our experiments is available at \url{https://github.com/lnsmith54/CFL}.
Cyclical Focal Loss
Feb 16, 2022


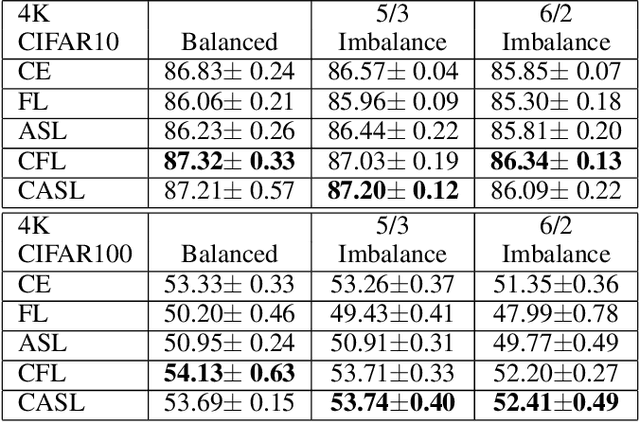
The cross-entropy softmax loss is the primary loss function used to train deep neural networks. On the other hand, the focal loss function has been demonstrated to provide improved performance when there is an imbalance in the number of training samples in each class, such as in long-tailed datasets. In this paper, we introduce a novel cyclical focal loss and demonstrate that it is a more universal loss function than cross-entropy softmax loss or focal loss. We describe the intuition behind the cyclical focal loss and our experiments provide evidence that cyclical focal loss provides superior performance for balanced, imbalanced, or long-tailed datasets. We provide numerous experimental results for CIFAR-10/CIFAR-100, ImageNet, balanced and imbalanced 4,000 training sample versions of CIFAR-10/CIFAR-100, and ImageNet-LT and Places-LT from the Open Long-Tailed Recognition (OLTR) challenge. Implementing the cyclical focal loss function requires only a few lines of code and does not increase training time. In the spirit of reproducibility, our code is available at \url{https://github.com/lnsmith54/CFL}.
FROST: Faster and more Robust One-shot Semi-supervised Training
Dec 04, 2020
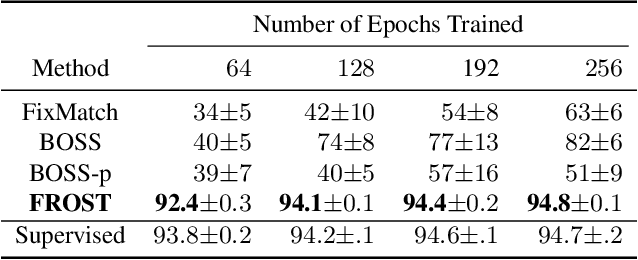
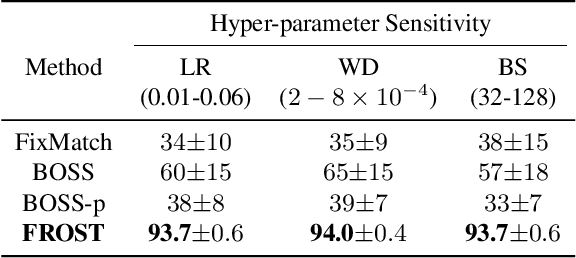

Recent advances in one-shot semi-supervised learning have lowered the barrier for deep learning of new applications. However, the state-of-the-art for semi-supervised learning is slow to train and the performance is sensitive to the choices of the labeled data and hyper-parameter values. In this paper, we present a one-shot semi-supervised learning method that trains up to an order of magnitude faster and is more robust than state-of-the-art methods. Specifically, we show that by combining semi-supervised learning with a one-stage, single network version of self-training, our FROST methodology trains faster and is more robust to choices for the labeled samples and changes in hyper-parameters. Our experiments demonstrate FROST's capability to perform well when the composition of the unlabeled data is unknown; that is when the unlabeled data contain unequal numbers of each class and can contain out-of-distribution examples that don't belong to any of the training classes. High performance, speed of training, and insensitivity to hyper-parameters make FROST the most practical method for one-shot semi-supervised training. Our code is available at https://github.com/HelenaELiu/FROST.
Building One-Shot Semi-supervised Learning up to Fully Supervised Performance
Jun 16, 2020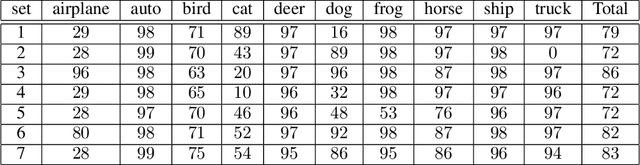
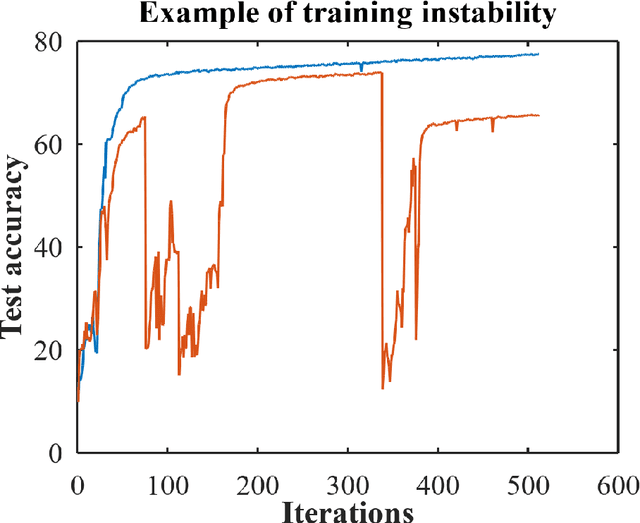


Reaching the performance of fully supervised learning with unlabeled data and only labeling one sample per class might be ideal for deep learning applications. We demonstrate for the first time the potential for building one-shot semi-supervised (BOSS) learning on Cifar-10 and SVHN up to attain test accuracies that are comparable to fully supervised learning. Our method combines class prototype refining, class balancing, and self-training. A good prototype choice is essential and we propose a practical technique for obtaining iconic examples. In addition, we demonstrate that class balancing methods substantially improve accuracy results in semi-supervised learning to levels that allow self-training to reach the level of fully supervised learning performance. Rigorous empirical evaluations provide evidence that labeling large datasets is not necessary for training deep neural networks. We made our code available at \url{https://github.com/lnsmith54/BOSS} to facilitate replication and for use with future real-world applications.
Empirical Perspectives on One-Shot Semi-supervised Learning
Apr 08, 2020
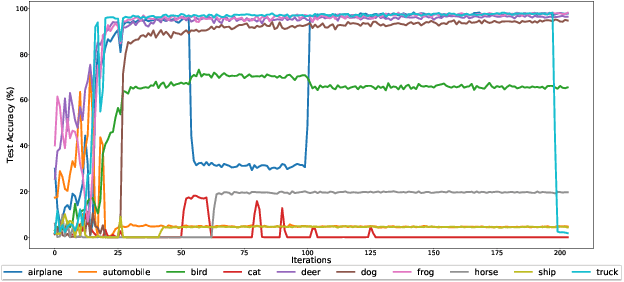

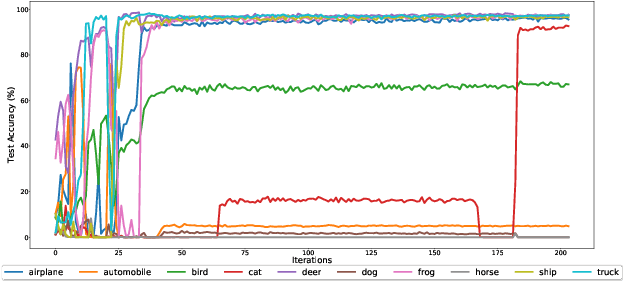
One of the greatest obstacles in the adoption of deep neural networks for new applications is that training the network typically requires a large number of manually labeled training samples. We empirically investigate the scenario where one has access to large amounts of unlabeled data but require labeling only a single prototypical sample per class in order to train a deep network (i.e., one-shot semi-supervised learning). Specifically, we investigate the recent results reported in FixMatch for one-shot semi-supervised learning to understand the factors that affect and impede high accuracies and reliability for one-shot semi-supervised learning of Cifar-10. For example, we discover that one barrier to one-shot semi-supervised learning for high-performance image classification is the unevenness of class accuracy during the training. These results point to solutions that might enable more widespread adoption of one-shot semi-supervised training methods for new applications.
A Useful Taxonomy for Adversarial Robustness of Neural Networks
Oct 23, 2019Adversarial attacks and defenses are currently active areas of research for the deep learning community. A recent review paper divided the defense approaches into three categories; gradient masking, robust optimization, and adversarial example detection. We divide gradient masking and robust optimization differently: (1) increasing intra-class compactness and inter-class separation of the feature vectors improves adversarial robustness, and (2) marginalization or removal of non-robust image features also improves adversarial robustness. By reframing these topics differently, we provide a fresh perspective that provides insight into the underlying factors that enable training more robust networks and can help inspire novel solutions. In addition, there are several papers in the literature of adversarial defenses that claim there is a cost for adversarial robustness, or a trade-off between robustness and accuracy but, under this proposed taxonomy, we hypothesis that this is not universal. We follow up on our taxonomy with several challenges to the deep learning research community that builds on the connections and insights in this paper.
Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates
May 17, 2018In this paper, we describe a phenomenon, which we named "super-convergence", where neural networks can be trained an order of magnitude faster than with standard training methods. The existence of super-convergence is relevant to understanding why deep networks generalize well. One of the key elements of super-convergence is training with one learning rate cycle and a large maximum learning rate. A primary insight that allows super-convergence training is that large learning rates regularize the training, hence requiring a reduction of all other forms of regularization in order to preserve an optimal regularization balance. We also derive a simplification of the Hessian Free optimization method to compute an estimate of the optimal learning rate. Experiments demonstrate super-convergence for Cifar-10/100, MNIST and Imagenet datasets, and resnet, wide-resnet, densenet, and inception architectures. In addition, we show that super-convergence provides a greater boost in performance relative to standard training when the amount of labeled training data is limited. The architectures and code to replicate the figures in this paper are available at github.com/lnsmith54/super-convergence. See http://www.fast.ai/2018/04/30/dawnbench-fastai/ for an application of super-convergence to win the DAWNBench challenge (see https://dawn.cs.stanford.edu/benchmark/).
A disciplined approach to neural network hyper-parameters: Part 1 -- learning rate, batch size, momentum, and weight decay
Apr 24, 2018



Although deep learning has produced dazzling successes for applications of image, speech, and video processing in the past few years, most trainings are with suboptimal hyper-parameters, requiring unnecessarily long training times. Setting the hyper-parameters remains a black art that requires years of experience to acquire. This report proposes several efficient ways to set the hyper-parameters that significantly reduce training time and improves performance. Specifically, this report shows how to examine the training validation/test loss function for subtle clues of underfitting and overfitting and suggests guidelines for moving toward the optimal balance point. Then it discusses how to increase/decrease the learning rate/momentum to speed up training. Our experiments show that it is crucial to balance every manner of regularization for each dataset and architecture. Weight decay is used as a sample regularizer to show how its optimal value is tightly coupled with the learning rates and momentums. Files to help replicate the results reported here are available.