 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Promise for Assurance of Differentiable Neurosymbolic Reasoning Paradigms
Feb 13, 2025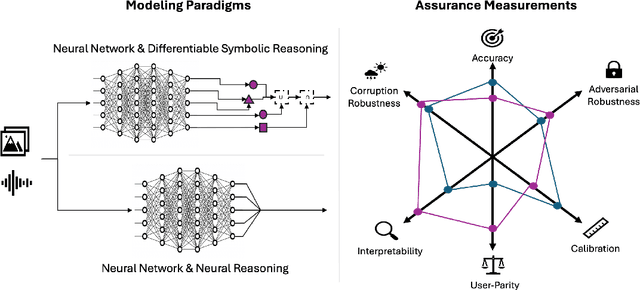
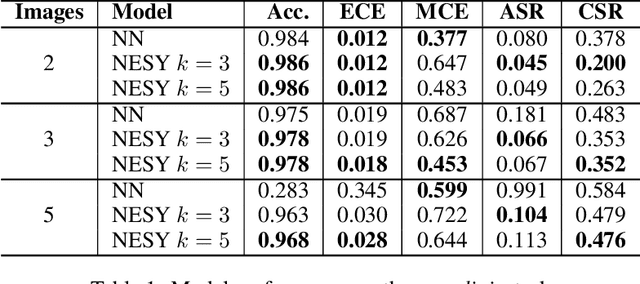
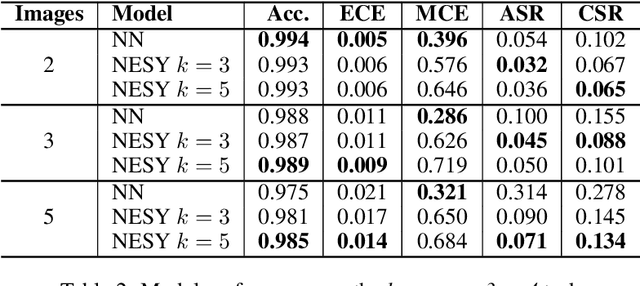
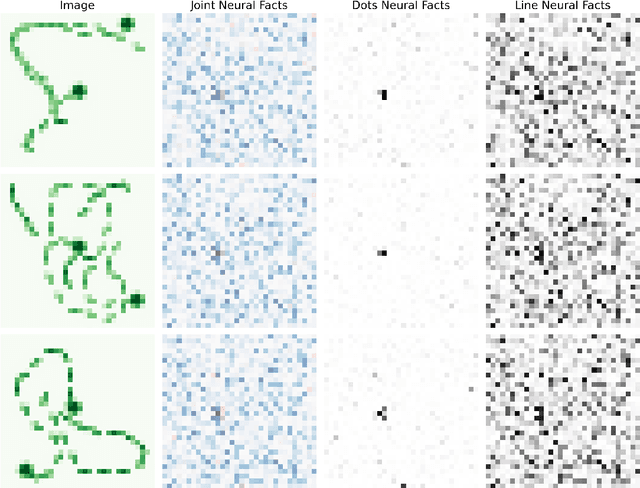
To create usable and deployable Artificial Intelligence (AI) systems, there requires a level of assurance in performance under many different conditions. Many times, deployed machine learning systems will require more classic logic and reasoning performed through neurosymbolic programs jointly with artificial neural network sensing. While many prior works have examined the assurance of a single component of the system solely with either the neural network alone or entire enterprise systems, very few works have examined the assurance of integrated neurosymbolic systems. Within this work, we assess the assurance of end-to-end fully differentiable neurosymbolic systems that are an emerging method to create data-efficient and more interpretable models. We perform this investigation using Scallop, an end-to-end neurosymbolic library, across classification and reasoning tasks in both the image and audio domains. We assess assurance across adversarial robustness, calibration, user performance parity, and interpretability of solutions for catching misaligned solutions. We find end-to-end neurosymbolic methods present unique opportunities for assurance beyond their data efficiency through our empirical results but not across the board. We find that this class of neurosymbolic models has higher assurance in cases where arithmetic operations are defined and where there is high dimensionality to the input space, where fully neural counterparts struggle to learn robust reasoning operations. We identify the relationship between neurosymbolic models' interpretability to catch shortcuts that later result in increased adversarial vulnerability despite performance parity. Finally, we find that the promise of data efficiency is typically only in the case of class imbalanced reasoning problems.
Measuring Equality in Machine Learning Security Defenses
Mar 01, 2023The machine learning security community has developed myriad defenses for evasion attacks over the past decade. An understudied question in that community is: for whom do these defenses defend? In this work, we consider some common approaches to defending learned systems and whether those approaches may offer unexpected performance inequities when used by different sub-populations. We outline simple parity metrics and a framework for analysis that can begin to answer this question through empirical results of the fairness implications of machine learning security methods. Many methods have been proposed that can cause direct harm, which we describe as biased vulnerability and biased rejection. Our framework and metric can be applied to robustly trained models, preprocessing-based methods, and rejection methods to capture behavior over security budgets. We identify a realistic dataset with a reasonable computational cost suitable for measuring the equality of defenses. Through a case study in speech command recognition, we show how such defenses do not offer equal protection for social subgroups and how to perform such analyses for robustness training, and we present a comparison of fairness between two rejection-based defenses: randomized smoothing and neural rejection. We offer further analysis of factors that correlate to equitable defenses to stimulate the future investigation of how to assist in building such defenses. To the best of our knowledge, this is the first work that examines the fairness disparity in the accuracy-robustness trade-off in speech data and addresses fairness evaluation for rejection-based defenses.
Improving Out-of-Distribution Detection via Epistemic Uncertainty Adversarial Training
Sep 09, 2022
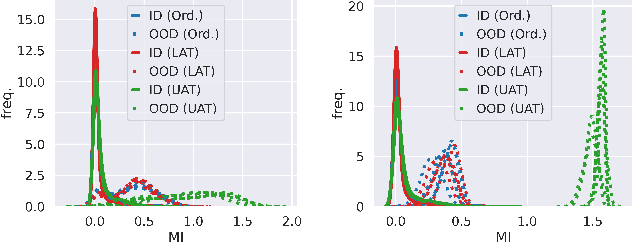
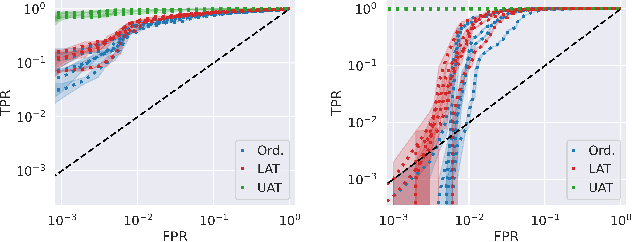
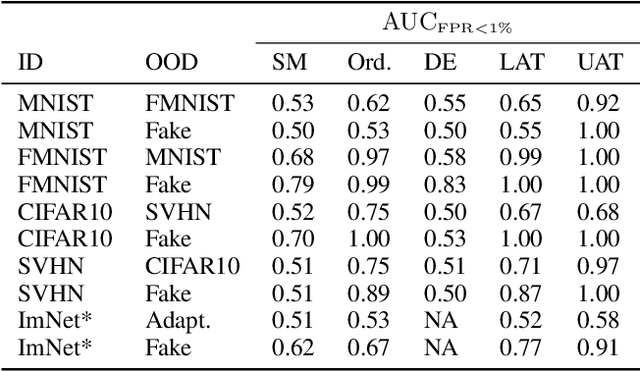
The quantification of uncertainty is important for the adoption of machine learning, especially to reject out-of-distribution (OOD) data back to human experts for review. Yet progress has been slow, as a balance must be struck between computational efficiency and the quality of uncertainty estimates. For this reason many use deep ensembles of neural networks or Monte Carlo dropout for reasonable uncertainty estimates at relatively minimal compute and memory. Surprisingly, when we focus on the real-world applicable constraint of $\leq 1\%$ false positive rate (FPR), prior methods fail to reliably detect OOD samples as such. Notably, even Gaussian random noise fails to trigger these popular OOD techniques. We help to alleviate this problem by devising a simple adversarial training scheme that incorporates an attack of the epistemic uncertainty predicted by the dropout ensemble. We demonstrate this method improves OOD detection performance on standard data (i.e., not adversarially crafted), and improves the standardized partial AUC from near-random guessing performance to $\geq 0.75$.
FedSPLIT: One-Shot Federated Recommendation System Based on Non-negative Joint Matrix Factorization and Knowledge Distillation
May 04, 2022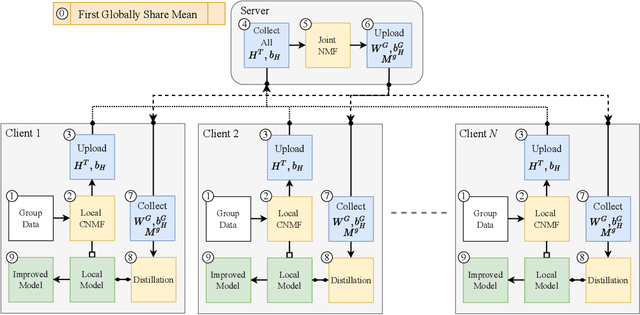


Non-negative matrix factorization (NMF) with missing-value completion is a well-known effective Collaborative Filtering (CF) method used to provide personalized user recommendations. However, traditional CF relies on the privacy-invasive collection of users' explicit and implicit feedback to build a central recommender model. One-shot federated learning has recently emerged as a method to mitigate the privacy problem while addressing the traditional communication bottleneck of federated learning. In this paper, we present the first unsupervised one-shot federated CF implementation, named FedSPLIT, based on NMF joint factorization. In our solution, the clients first apply local CF in-parallel to build distinct client-specific recommenders. Then, the privacy-preserving local item patterns and biases from each client are shared with the processor to perform joint factorization in order to extract the global item patterns. Extracted patterns are then aggregated to each client to build the local models via knowledge distillation. In our experiments, we demonstrate the feasibility of our approach with standard recommendation datasets. FedSPLIT can obtain similar results than the state of the art (and even outperform it in certain situations) with a substantial decrease in the number of communications.
Bridging the Gap: Using Deep Acoustic Representations to Learn Grounded Language from Percepts and Raw Speech
Dec 27, 2021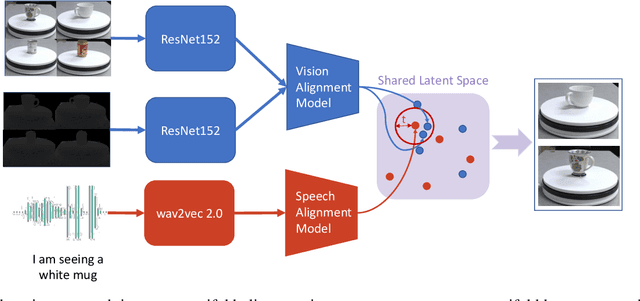
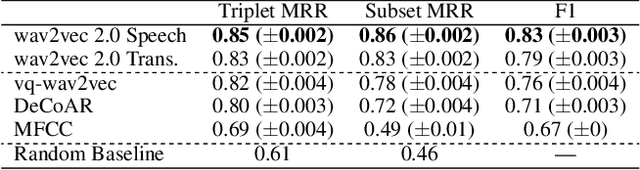
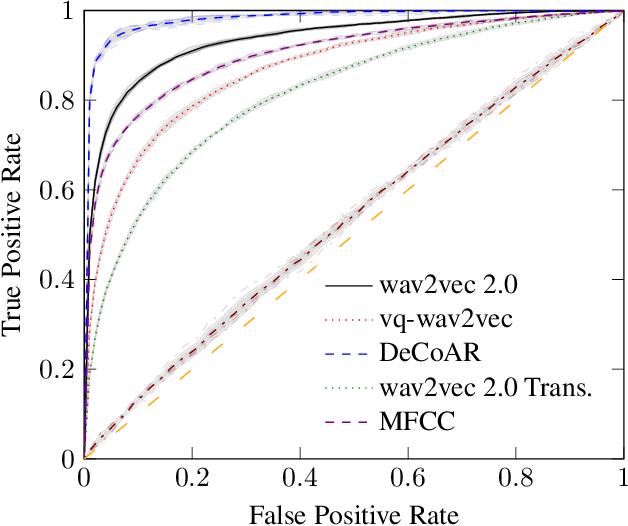

Learning to understand grounded language, which connects natural language to percepts, is a critical research area. Prior work in grounded language acquisition has focused primarily on textual inputs. In this work we demonstrate the feasibility of performing grounded language acquisition on paired visual percepts and raw speech inputs. This will allow interactions in which language about novel tasks and environments is learned from end users, reducing dependence on textual inputs and potentially mitigating the effects of demographic bias found in widely available speech recognition systems. We leverage recent work in self-supervised speech representation models and show that learned representations of speech can make language grounding systems more inclusive towards specific groups while maintaining or even increasing general performance.
Adversarial Transfer Attacks With Unknown Data and Class Overlap
Sep 24, 2021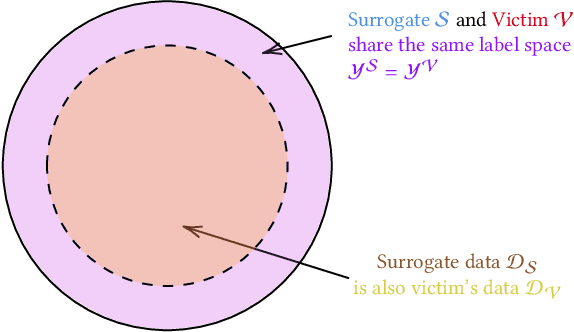
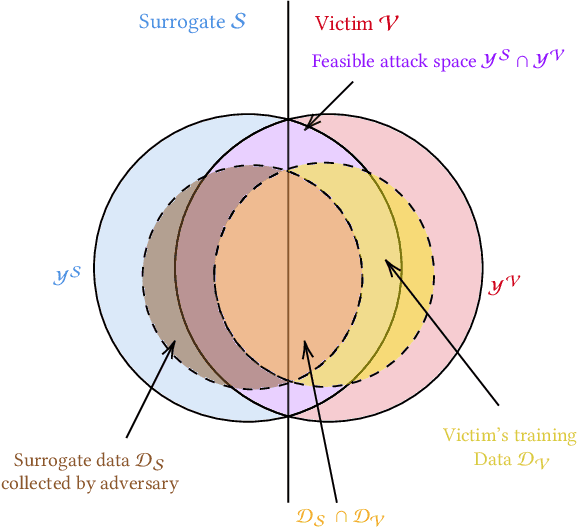
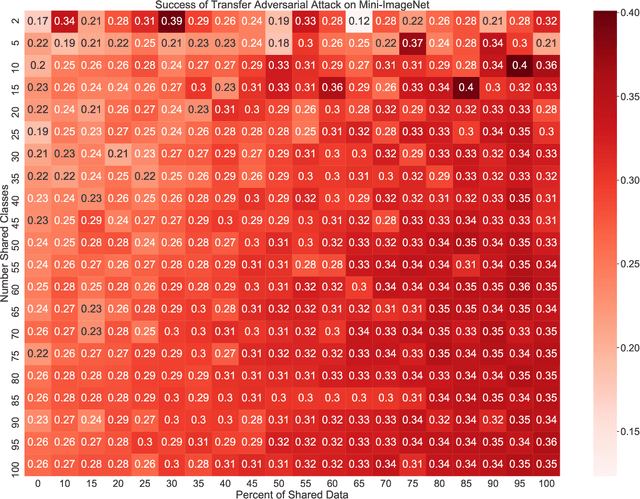
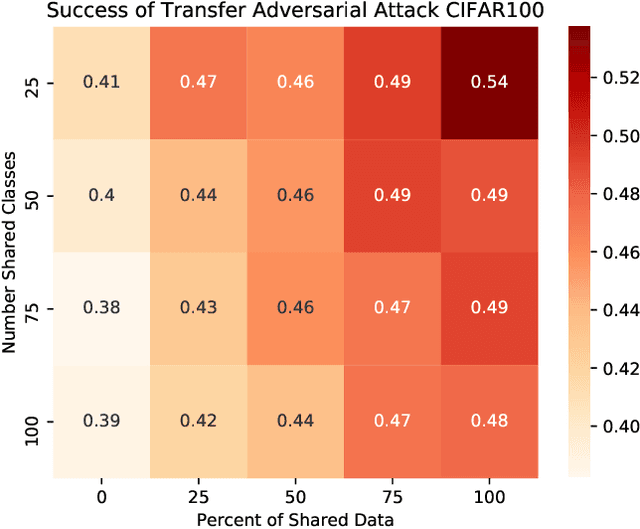
The ability to transfer adversarial attacks from one model (the surrogate) to another model (the victim) has been an issue of concern within the machine learning (ML) community. The ability to successfully evade unseen models represents an uncomfortable level of ease toward implementing attacks. In this work we note that as studied, current transfer attack research has an unrealistic advantage for the attacker: the attacker has the exact same training data as the victim. We present the first study of transferring adversarial attacks focusing on the data available to attacker and victim under imperfect settings without querying the victim, where there is some variable level of overlap in the exact data used or in the classes learned by each model. This threat model is relevant to applications in medicine, malware, and others. Under this new threat model attack success rate is not correlated with data or class overlap in the way one would expect, and varies with dataset. This makes it difficult for attacker and defender to reason about each other and contributes to the broader study of model robustness and security. We remedy this by developing a masked version of Projected Gradient Descent that simulates class disparity, which enables the attacker to reliably estimate a lower-bound on their attack's success.
Practical Cross-modal Manifold Alignment for Grounded Language
Sep 01, 2020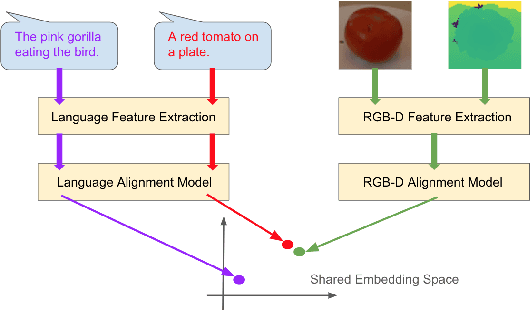
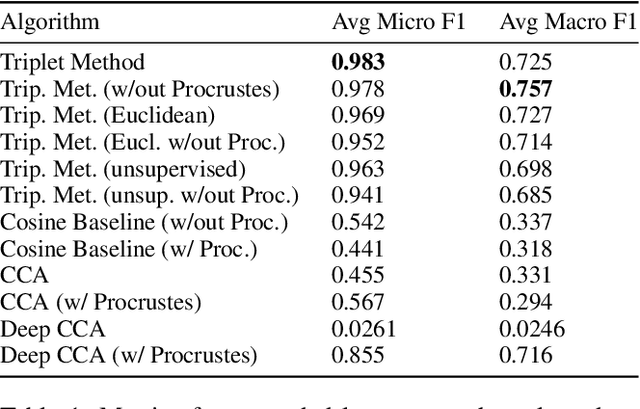

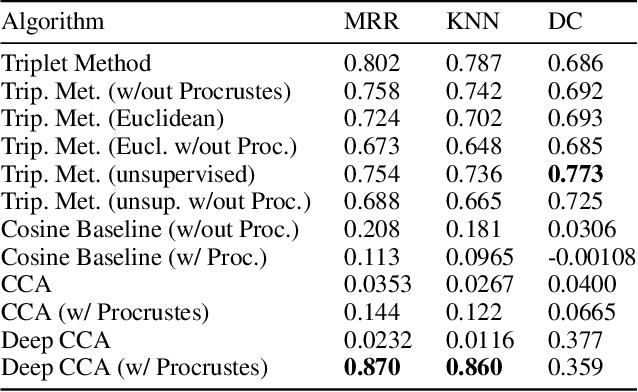
We propose a cross-modality manifold alignment procedure that leverages triplet loss to jointly learn consistent, multi-modal embeddings of language-based concepts of real-world items. Our approach learns these embeddings by sampling triples of anchor, positive, and negative data points from RGB-depth images and their natural language descriptions. We show that our approach can benefit from, but does not require, post-processing steps such as Procrustes analysis, in contrast to some of our baselines which require it for reasonable performance. We demonstrate the effectiveness of our approach on two datasets commonly used to develop robotic-based grounded language learning systems, where our approach outperforms four baselines, including a state-of-the-art approach, across five evaluation metrics.