 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Samples Are Not Created Equal
Jan 02, 2026Over the past decade, numerous theories have been proposed to explain the widespread vulnerability of deep neural networks to adversarial evasion attacks. Among these, the theory of non-robust features proposed by Ilyas et al. has been widely accepted, showing that brittle but predictive features of the data distribution can be directly exploited by attackers. However, this theory overlooks adversarial samples that do not directly utilize these features. In this work, we advocate that these two kinds of samples - those which use use brittle but predictive features and those that do not - comprise two types of adversarial weaknesses and should be differentiated when evaluating adversarial robustness. For this purpose, we propose an ensemble-based metric to measure the manipulation of non-robust features by adversarial perturbations and use this metric to analyze the makeup of adversarial samples generated by attackers. This new perspective also allows us to re-examine multiple phenomena, including the impact of sharpness-aware minimization on adversarial robustness and the robustness gap observed between adversarially training and standard training on robust datasets.
Improving Out-of-Distribution Detection via Epistemic Uncertainty Adversarial Training
Sep 09, 2022
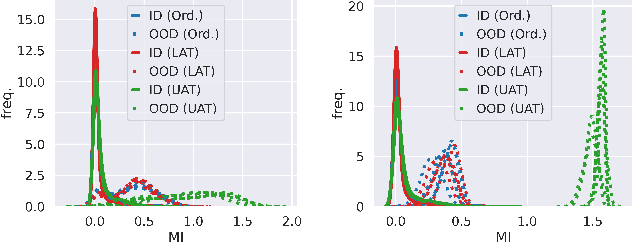
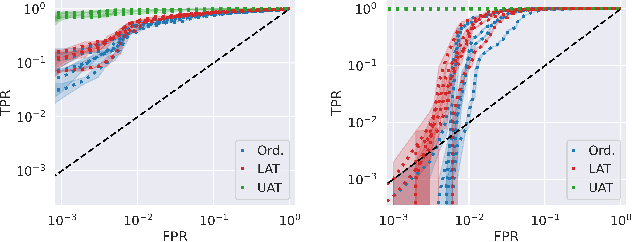
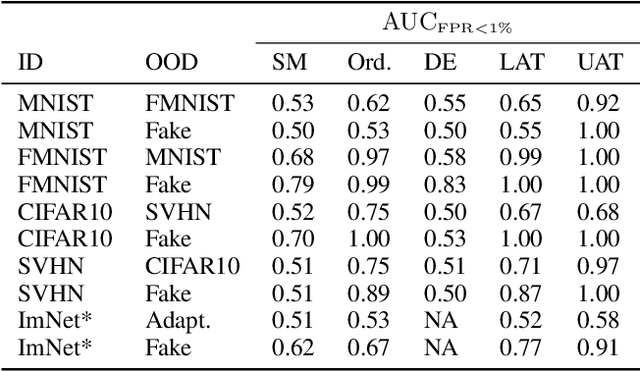
The quantification of uncertainty is important for the adoption of machine learning, especially to reject out-of-distribution (OOD) data back to human experts for review. Yet progress has been slow, as a balance must be struck between computational efficiency and the quality of uncertainty estimates. For this reason many use deep ensembles of neural networks or Monte Carlo dropout for reasonable uncertainty estimates at relatively minimal compute and memory. Surprisingly, when we focus on the real-world applicable constraint of $\leq 1\%$ false positive rate (FPR), prior methods fail to reliably detect OOD samples as such. Notably, even Gaussian random noise fails to trigger these popular OOD techniques. We help to alleviate this problem by devising a simple adversarial training scheme that incorporates an attack of the epistemic uncertainty predicted by the dropout ensemble. We demonstrate this method improves OOD detection performance on standard data (i.e., not adversarially crafted), and improves the standardized partial AUC from near-random guessing performance to $\geq 0.75$.
Out of Distribution Data Detection Using Dropout Bayesian Neural Networks
Feb 18, 2022


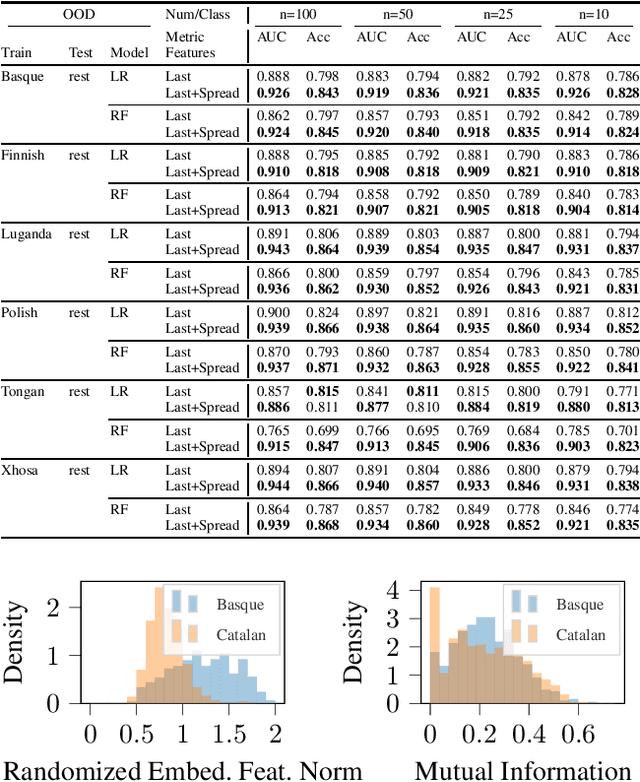
We explore the utility of information contained within a dropout based Bayesian neural network (BNN) for the task of detecting out of distribution (OOD) data. We first show how previous attempts to leverage the randomized embeddings induced by the intermediate layers of a dropout BNN can fail due to the distance metric used. We introduce an alternative approach to measuring embedding uncertainty, justify its use theoretically, and demonstrate how incorporating embedding uncertainty improves OOD data identification across three tasks: image classification, language classification, and malware detection.
Leveraging Uncertainty for Improved Static Malware Detection Under Extreme False Positive Constraints
Aug 09, 2021

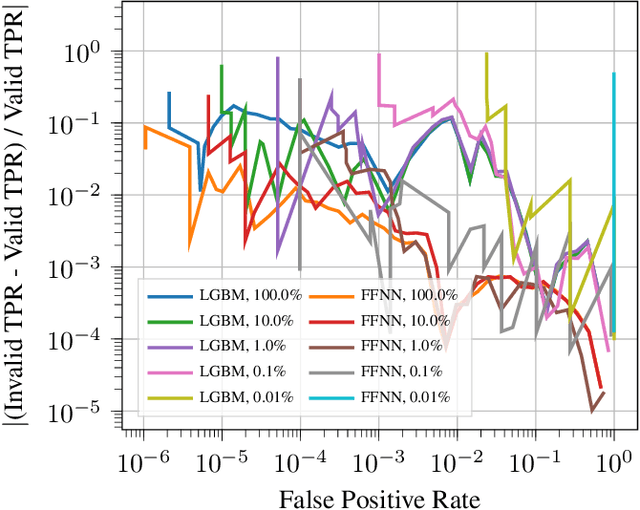
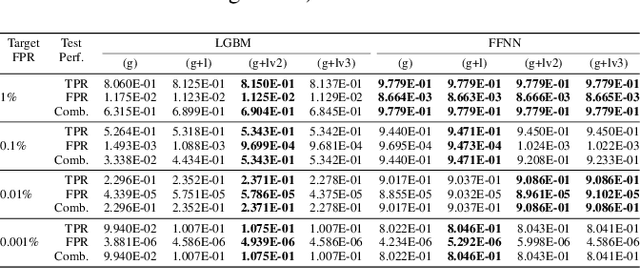
The detection of malware is a critical task for the protection of computing environments. This task often requires extremely low false positive rates (FPR) of 0.01% or even lower, for which modern machine learning has no readily available tools. We introduce the first broad investigation of the use of uncertainty for malware detection across multiple datasets, models, and feature types. We show how ensembling and Bayesian treatments of machine learning methods for static malware detection allow for improved identification of model errors, uncovering of new malware families, and predictive performance under extreme false positive constraints. In particular, we improve the true positive rate (TPR) at an actual realized FPR of 1e-5 from an expected 0.69 for previous methods to 0.80 on the best performing model class on the Sophos industry scale dataset. We additionally demonstrate how previous works have used an evaluation protocol that can lead to misleading results.
Practical Cross-modal Manifold Alignment for Grounded Language
Sep 01, 2020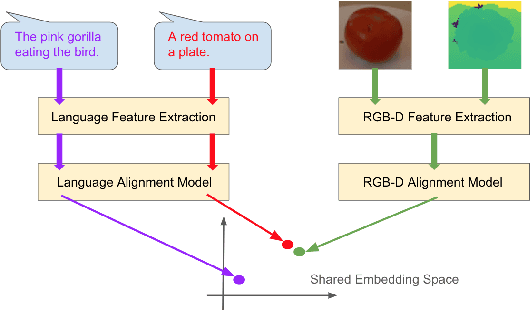
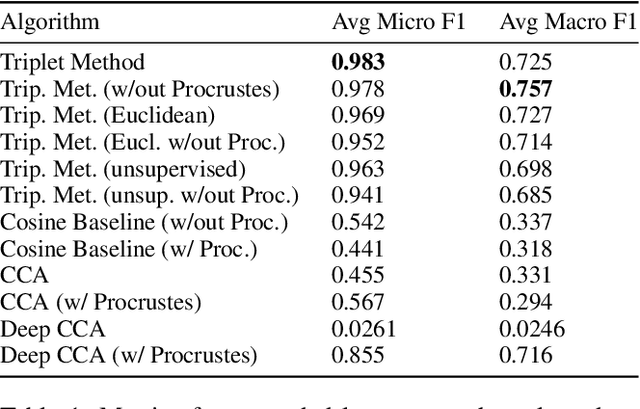

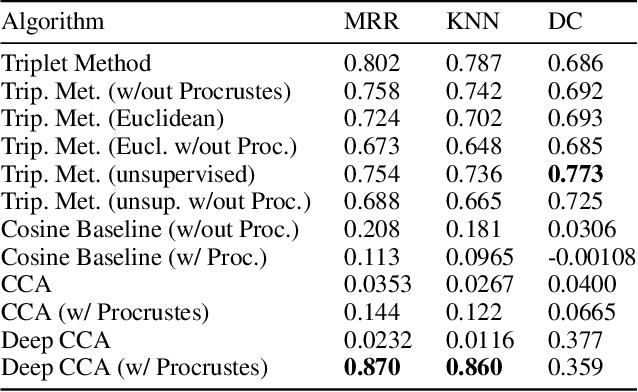
We propose a cross-modality manifold alignment procedure that leverages triplet loss to jointly learn consistent, multi-modal embeddings of language-based concepts of real-world items. Our approach learns these embeddings by sampling triples of anchor, positive, and negative data points from RGB-depth images and their natural language descriptions. We show that our approach can benefit from, but does not require, post-processing steps such as Procrustes analysis, in contrast to some of our baselines which require it for reasonable performance. We demonstrate the effectiveness of our approach on two datasets commonly used to develop robotic-based grounded language learning systems, where our approach outperforms four baselines, including a state-of-the-art approach, across five evaluation metrics.
Towards the Use of Neural Networks for Influenza Prediction at Multiple Spatial Resolutions
Nov 13, 2019

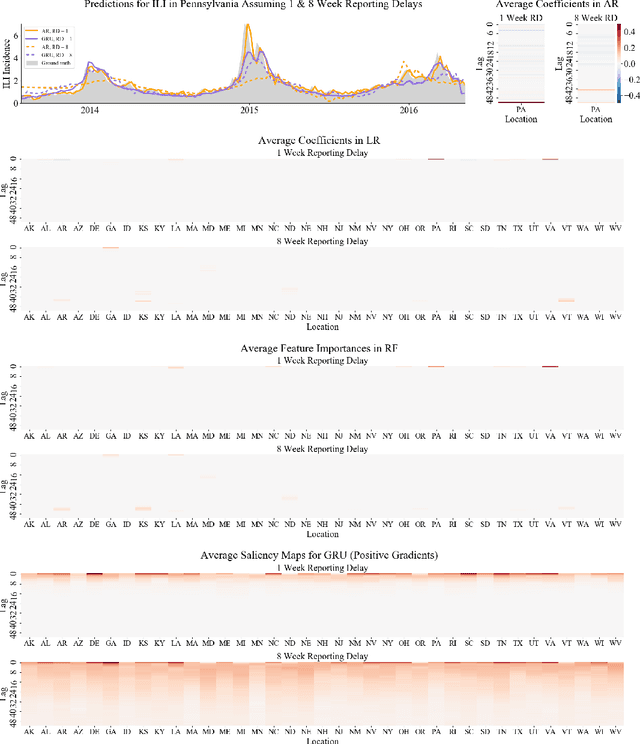
We introduce the use of a Gated Recurrent Unit (GRU) for influenza prediction at the state- and city-level in the US, and experiment with the inclusion of real-time flu-related Internet search data. We find that a GRU has lower prediction error than current state-of-the-art methods for data-driven influenza prediction at time horizons of over two weeks. In contrast with other machine learning approaches, the inclusion of real-time Internet search data does not improve GRU predictions.
Robust Design of Deep Neural Networks against Adversarial Attacks based on Lyapunov Theory
Nov 12, 2019
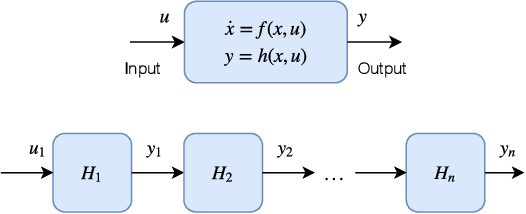
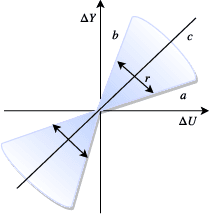
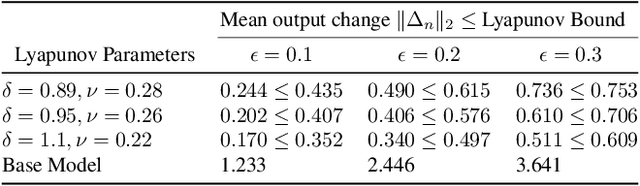
Deep neural networks (DNNs) are vulnerable to subtle adversarial perturbations applied to the input. These adversarial perturbations, though imperceptible, can easily mislead the DNN. In this work, we take a control theoretic approach to the problem of robustness in DNNs. We treat each individual layer of the DNN as a nonlinear dynamical system and use Lyapunov theory to prove stability and robustness locally. We then proceed to prove stability and robustness globally for the entire DNN. We develop empirically tight bounds on the response of the output layer, or any hidden layer, to adversarial perturbations added to the input, or the input of hidden layers. Recent works have proposed spectral norm regularization as a solution for improving robustness against l2 adversarial attacks. Our results give new insights into how spectral norm regularization can mitigate the adversarial effects. Finally, we evaluate the power of our approach on a variety of data sets and network architectures and against some of the well-known adversarial attacks.
Would a File by Any Other Name Seem as Malicious?
Oct 10, 2019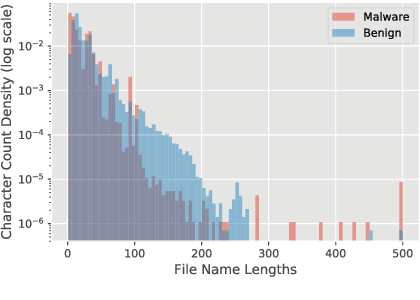

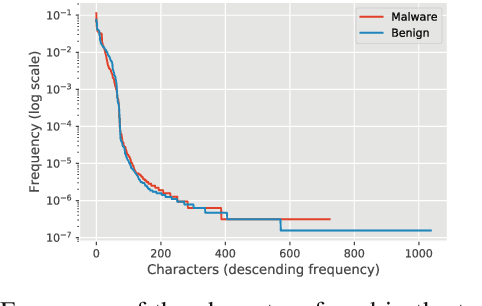
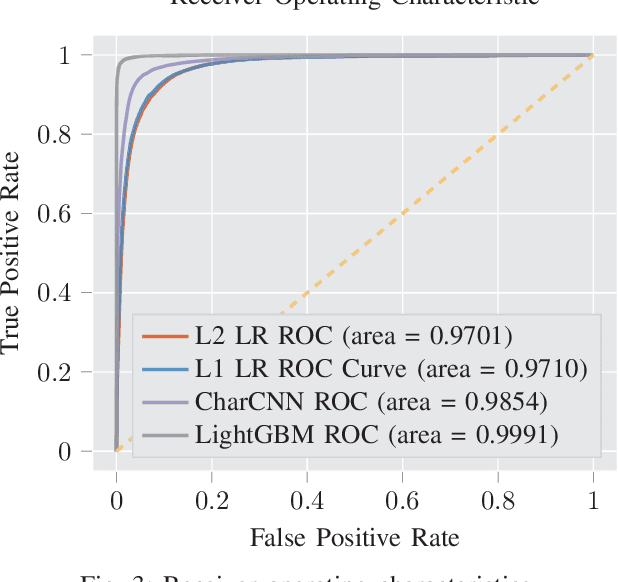
Successful malware attacks on information technology systems can cause millions of dollars in damage, the exposure of sensitive and private information, and the irreversible destruction of data. Anti-virus systems that analyze a file's contents use a combination of static and dynamic analysis to detect and remove/remediate such malware. However, examining a file's entire contents is not always possible in practice, as the volume and velocity of incoming data may be too high, or access to the underlying file contents may be restricted or unavailable. If it were possible to obtain estimates of a file's relative likelihood of being malicious without looking at the file contents, we could better prioritize file processing order and aid analysts in situations where a file is unavailable. In this work, we demonstrate that file names can contain information predictive of the presence of malware in a file. In particular, we show the effectiveness of a character-level convolutional neural network at predicting malware status using file names on Endgame's EMBER malware detection benchmark dataset.
Heterogeneous Relational Kernel Learning
Aug 24, 2019



Recent work has developed Bayesian methods for the automatic statistical analysis and description of single time series as well as of homogeneous sets of time series data. We extend prior work to create an interpretable kernel embedding for heterogeneous time series. Our method adds practically no computational cost compared to prior results by leveraging previously discarded intermediate results. We show the practical utility of our method by leveraging the learned embeddings for clustering, pattern discovery, and anomaly detection. These applications are beyond the ability of prior relational kernel learning approaches.
Connecting Lyapunov Control Theory to Adversarial Attacks
Jul 17, 2019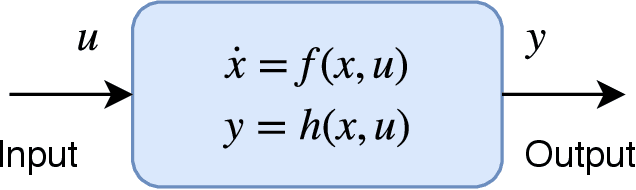
Significant work is being done to develop the math and tools necessary to build provable defenses, or at least bounds, against adversarial attacks of neural networks. In this work, we argue that tools from control theory could be leveraged to aid in defending against such attacks. We do this by example, building a provable defense against a weaker adversary. This is done so we can focus on the mechanisms of control theory, and illuminate its intrinsic value.