 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRP: Distilled Reasoning Pruning with Skill-aware Step Decomposition for Efficient Large Reasoning Models
May 20, 2025While Large Reasoning Models (LRMs) have demonstrated success in complex reasoning tasks through long chain-of-thought (CoT) reasoning, their inference often involves excessively verbose reasoning traces, resulting in substantial inefficiency. To address this, we propose Distilled Reasoning Pruning (DRP), a hybrid framework that combines inference-time pruning with tuning-based distillation, two widely used strategies for efficient reasoning. DRP uses a teacher model to perform skill-aware step decomposition and content pruning, and then distills the pruned reasoning paths into a student model, enabling it to reason both efficiently and accurately. Across several challenging mathematical reasoning datasets, we find that models trained with DRP achieve substantial improvements in token efficiency without sacrificing accuracy. Specifically, DRP reduces average token usage on GSM8K from 917 to 328 while improving accuracy from 91.7% to 94.1%, and achieves a 43% token reduction on AIME with no performance drop. Further analysis shows that aligning the reasoning structure of training CoTs with the student's reasoning capacity is critical for effective knowledge transfer and performance gains.
Practical Cross-modal Manifold Alignment for Grounded Language
Sep 01, 2020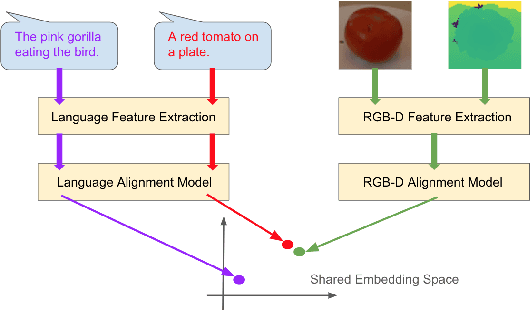
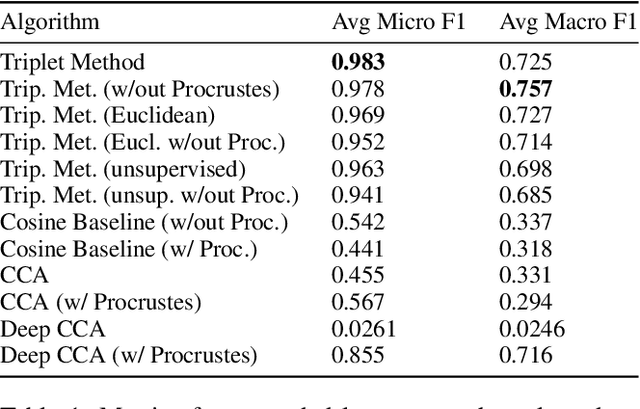

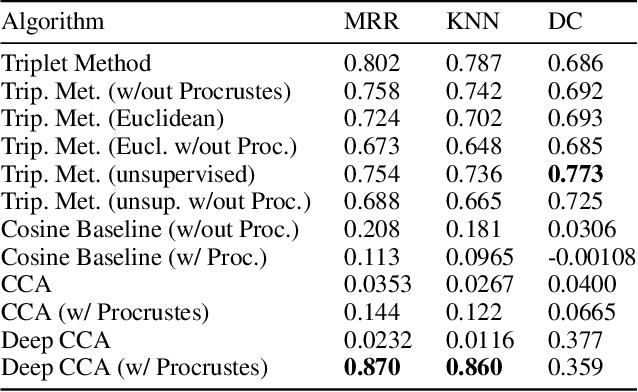
We propose a cross-modality manifold alignment procedure that leverages triplet loss to jointly learn consistent, multi-modal embeddings of language-based concepts of real-world items. Our approach learns these embeddings by sampling triples of anchor, positive, and negative data points from RGB-depth images and their natural language descriptions. We show that our approach can benefit from, but does not require, post-processing steps such as Procrustes analysis, in contrast to some of our baselines which require it for reasonable performance. We demonstrate the effectiveness of our approach on two datasets commonly used to develop robotic-based grounded language learning systems, where our approach outperforms four baselines, including a state-of-the-art approach, across five evaluation metrics.
Locality Preserving Loss to Align Vector Spaces
Apr 07, 2020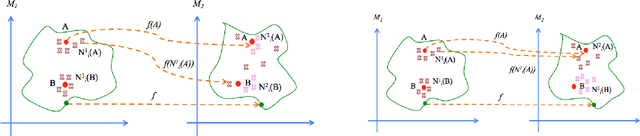
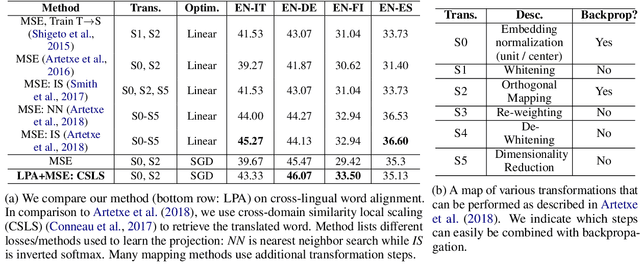
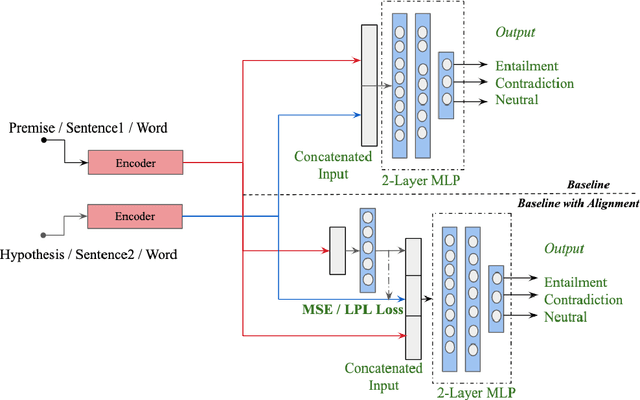

We present a locality preserving loss (LPL)that improves the alignment between vector space representations (i.e., word or sentence embeddings) while separating (increasing distance between) uncorrelated representations as compared to the standard method that minimizes the mean squared error (MSE) only. The locality preserving loss optimizes the projection by maintaining the local neighborhood of embeddings that are found in the source, in the target domain as well. This reduces the overall size of the dataset required to the train model. We argue that vector space alignment (with MSE and LPL losses) acts as a regularizer in certain language-based classification tasks, leading to better accuracy than the base-line, especially when the size of the training set is small. We validate the effectiveness ofLPL on a cross-lingual word alignment task, a natural language inference task, and a multi-lingual inference task.
KGCleaner : Identifying and Correcting Errors Produced by Information Extraction Systems
Aug 15, 2018
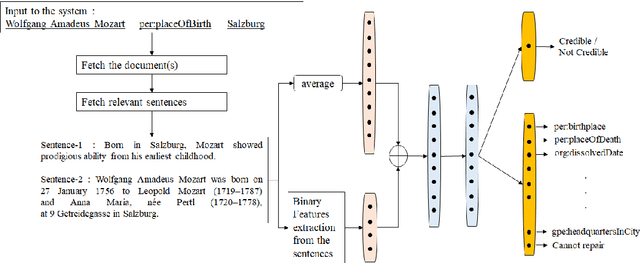

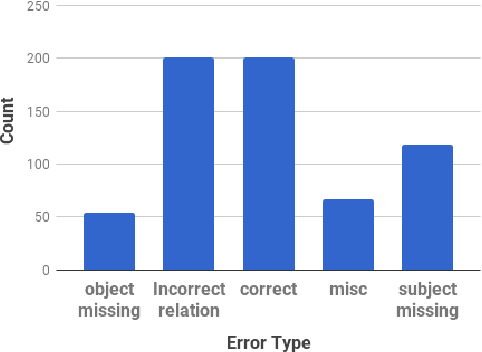
KGCleaner is a framework to identify and correct errors in data produced and delivered by an information extraction system. These tasks have been understudied and KGCleaner is the first to address both. We introduce a multi-task model that jointly learns to predict if an extracted relation is credible and repair it if not. We evaluate our approach and other models as instance of our framework on two collections: a Wikidata corpus of nearly 700K facts and 5M fact-relevant sentences and a collection of 30K facts from the 2015 TAC Knowledge Base Population task. For credibility classification, parameter efficient simple shallow neural network can achieve an absolute performance gain of 30 $F_1$ points on Wikidata and comparable performance on TAC. For the repair task, significant performance (at more than twice) gain can be obtained depending on the nature of the dataset and the models.