 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Holographic Reduced Representations
Sep 05, 2021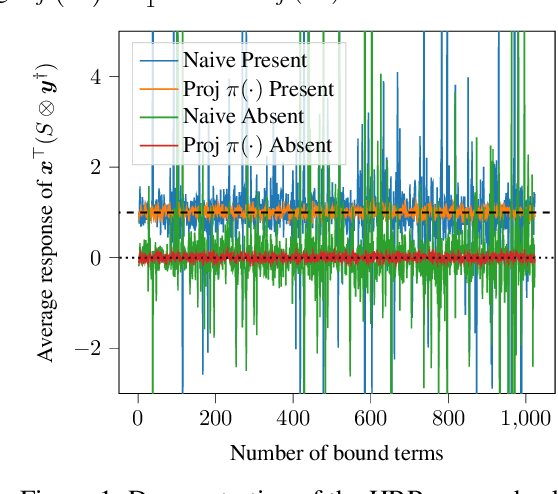
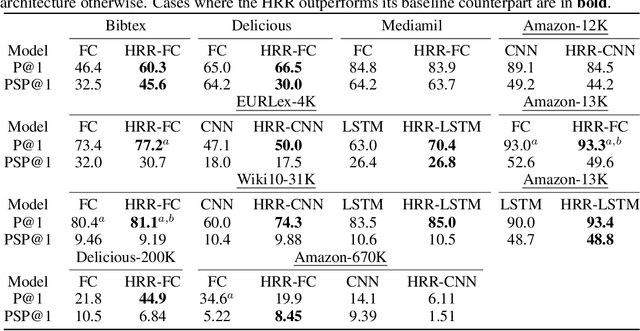

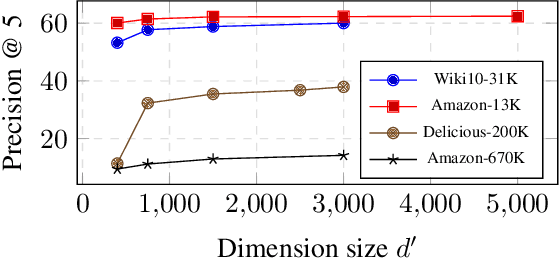
Holographic Reduced Representations (HRR) are a method for performing symbolic AI on top of real-valued vectors \cite{Plate1995} by associating each vector with an abstract concept, and providing mathematical operations to manipulate vectors as if they were classic symbolic objects. This method has seen little use outside of older symbolic AI work and cognitive science. Our goal is to revisit this approach to understand if it is viable for enabling a hybrid neural-symbolic approach to learning as a differentiable component of a deep learning architecture. HRRs today are not effective in a differentiable solution due to numerical instability, a problem we solve by introducing a projection step that forces the vectors to exist in a well behaved point in space. In doing so we improve the concept retrieval efficacy of HRRs by over $100\times$. Using multi-label classification we demonstrate how to leverage the symbolic HRR properties to develop an output layer and loss function that is able to learn effectively, and allows us to investigate some of the pros and cons of an HRR neuro-symbolic learning approach.
Learning a Reversible Embedding Mapping using Bi-Directional Manifold Alignment
Jun 30, 2021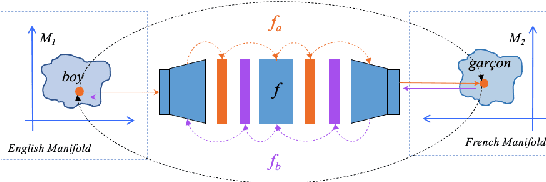
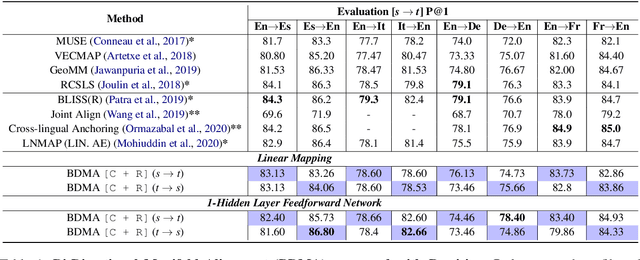
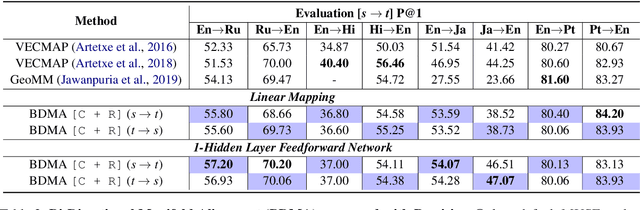
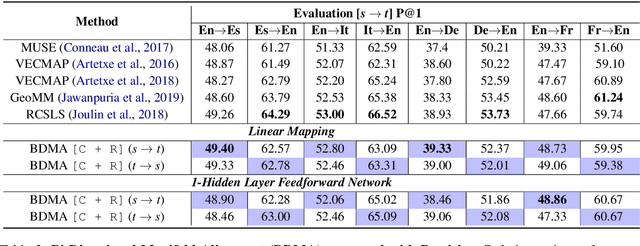
We propose a Bi-Directional Manifold Alignment (BDMA) that learns a non-linear mapping between two manifolds by explicitly training it to be bijective. We demonstrate BDMA by training a model for a pair of languages rather than individual, directed source and target combinations, reducing the number of models by 50%. We show that models trained with BDMA in the "forward" (source to target) direction can successfully map words in the "reverse" (target to source) direction, yielding equivalent (or better) performance to standard unidirectional translation models where the source and target language is flipped. We also show how BDMA reduces the overall size of the model.
Locality Preserving Loss to Align Vector Spaces
Apr 07, 2020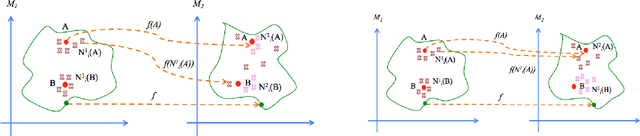
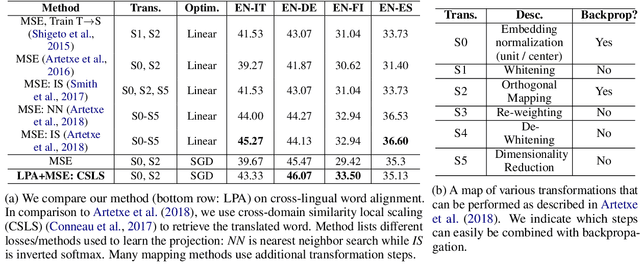
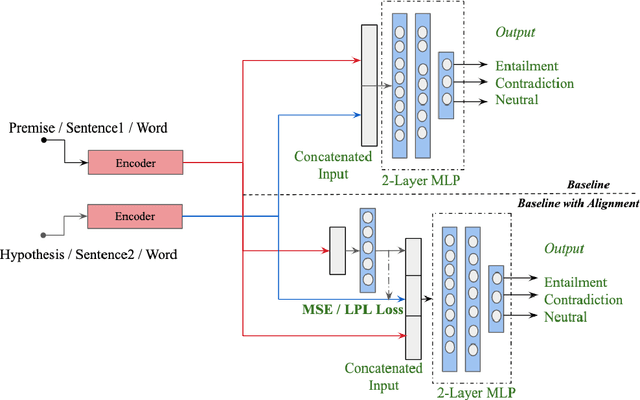

We present a locality preserving loss (LPL)that improves the alignment between vector space representations (i.e., word or sentence embeddings) while separating (increasing distance between) uncorrelated representations as compared to the standard method that minimizes the mean squared error (MSE) only. The locality preserving loss optimizes the projection by maintaining the local neighborhood of embeddings that are found in the source, in the target domain as well. This reduces the overall size of the dataset required to the train model. We argue that vector space alignment (with MSE and LPL losses) acts as a regularizer in certain language-based classification tasks, leading to better accuracy than the base-line, especially when the size of the training set is small. We validate the effectiveness ofLPL on a cross-lingual word alignment task, a natural language inference task, and a multi-lingual inference task.
Determining the Scale of Impact from Denial-of-Service Attacks in Real Time Using Twitter
Sep 12, 2019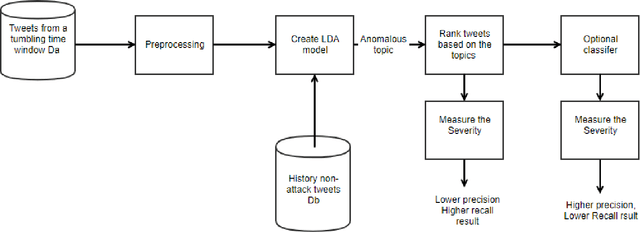
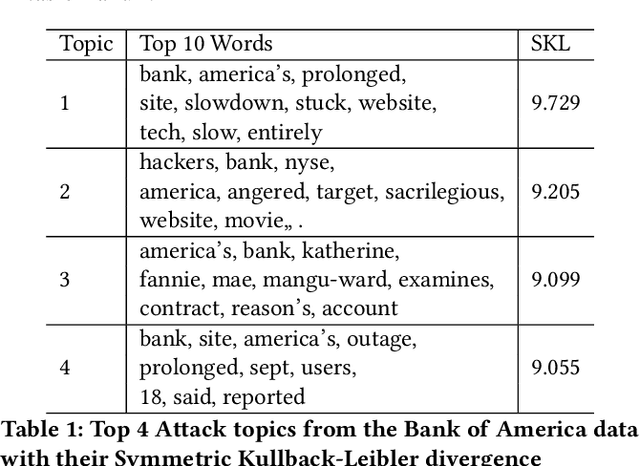
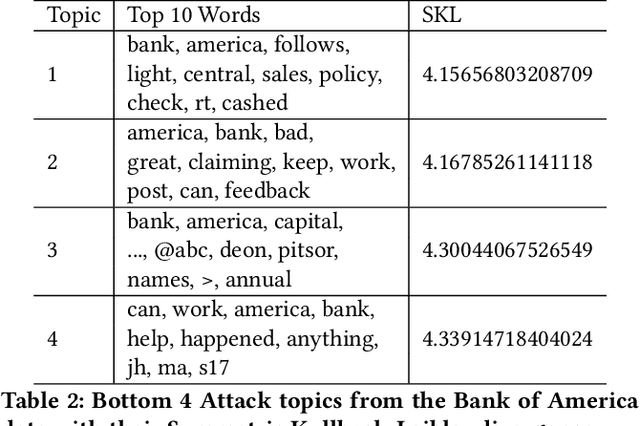
Denial of Service (DoS) attacks are common in on-line and mobile services such as Twitter, Facebook and banking. As the scale and frequency of Distributed Denial of Service (DDoS) attacks increase, there is an urgent need for determining the impact of the attack. Two central challenges of the task are to get feedback from a large number of users and to get it in a timely manner. In this paper, we present a weakly-supervised model that does not need annotated data to measure the impact of DoS issues by applying Latent Dirichlet Allocation and symmetric Kullback-Leibler divergence on tweets. There is a limitation to the weakly-supervised module. It assumes that the event detected in a time window is a DoS attack event. This will become less of a problem, when more non-attack events twitter got collected and become less likely to be identified as a new event. Another way to remove that limitation, an optional classification layer, trained on manually annotated DoS attack tweets, to filter out non-attack tweets can be used to increase precision at the expense of recall. Experimental results show that we can learn weakly-supervised models that can achieve comparable precision to supervised ones and can be generalized across entities in the same industry.
Extending Signature-based Intrusion Detection Systems WithBayesian Abductive Reasoning
Mar 28, 2019
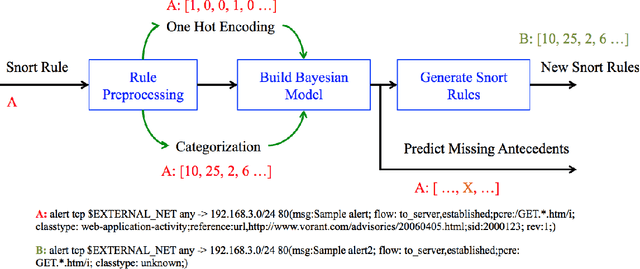

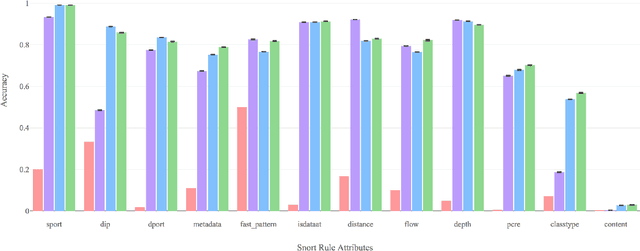
Evolving cybersecurity threats are a persistent challenge for systemadministrators and security experts as new malwares are continu-ally released. Attackers may look for vulnerabilities in commercialproducts or execute sophisticated reconnaissance campaigns tounderstand a targets network and gather information on securityproducts like firewalls and intrusion detection / prevention systems(network or host-based). Many new attacks tend to be modificationsof existing ones. In such a scenario, rule-based systems fail to detectthe attack, even though there are minor differences in conditions /attributes between rules to identify the new and existing attack. Todetect these differences the IDS must be able to isolate the subset ofconditions that are true and predict the likely conditions (differentfrom the original) that must be observed. In this paper, we proposeaprobabilistic abductive reasoningapproach that augments an exist-ing rule-based IDS (snort [29]) to detect these evolved attacks by (a)Predicting rule conditions that are likely to occur (based on existingrules) and (b) able to generate new snort rules when provided withseed rule (i.e. a starting rule) to reduce the burden on experts toconstantly update them. We demonstrate the effectiveness of theapproach by generating new rules from the snort 2012 rules set andtesting it on the MACCDC 2012 dataset [6].
Fashioning with Networks: Neural Style Transfer to Design Clothes
Jul 31, 2017
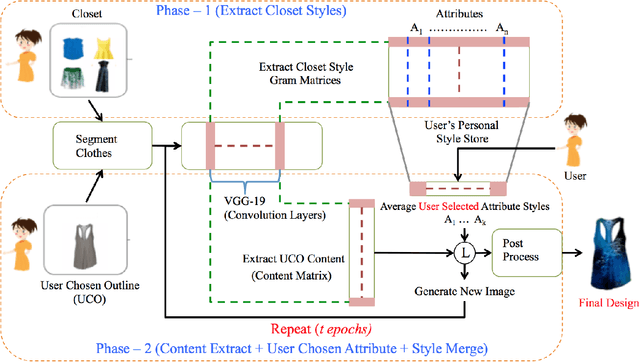
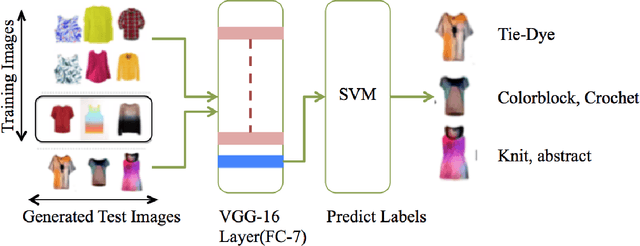

Convolutional Neural Networks have been highly successful in performing a host of computer vision tasks such as object recognition, object detection, image segmentation and texture synthesis. In 2015, Gatys et. al [7] show how the style of a painter can be extracted from an image of the painting and applied to another normal photograph, thus recreating the photo in the style of the painter. The method has been successfully applied to a wide range of images and has since spawned multiple applications and mobile apps. In this paper, the neural style transfer algorithm is applied to fashion so as to synthesize new custom clothes. We construct an approach to personalize and generate new custom clothes based on a users preference and by learning the users fashion choices from a limited set of clothes from their closet. The approach is evaluated by analyzing the generated images of clothes and how well they align with the users fashion style.
Identifying Spatial Relations in Images using Convolutional Neural Networks
Jun 13, 2017

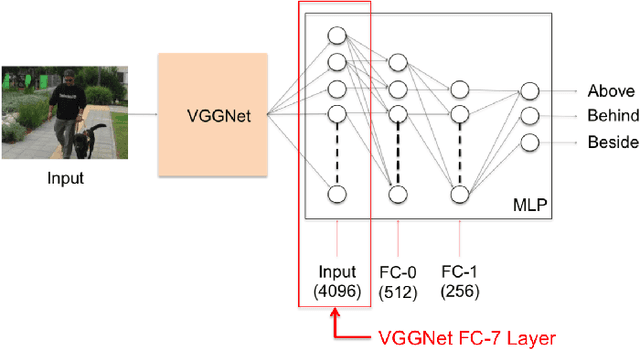
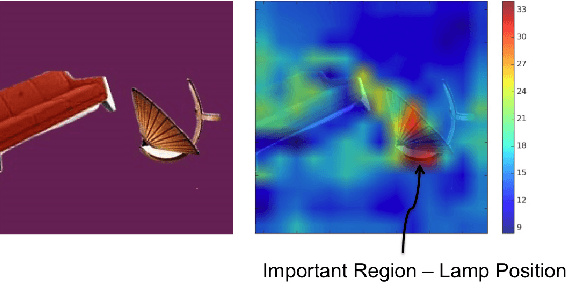
Traditional approaches to building a large scale knowledge graph have usually relied on extracting information (entities, their properties, and relations between them) from unstructured text (e.g. Dbpedia). Recent advances in Convolutional Neural Networks (CNN) allow us to shift our focus to learning entities and relations from images, as they build robust models that require little or no pre-processing of the images. In this paper, we present an approach to identify and extract spatial relations (e.g., The girl is standing behind the table) from images using CNNs. Our research addresses two specific challenges: providing insight into how spatial relations are learned by the network and which parts of the image are used to predict these relations. We use the pre-trained network VGGNet to extract features from an image and train a Multi-layer Perceptron (MLP) on a set of synthetic images and the sun09 dataset to extract spatial relations. The MLP predicts spatial relations without a bounding box around the objects or the space in the image depicting the relation. To understand how the spatial relations are represented in the network, a heatmap is overlayed on the image to show the regions that are deemed important by the network. Also, we analyze the MLP to show the relationship between the activation of consistent groups of nodes and the prediction of a spatial relation. We show how the loss of these groups affects the networks ability to identify relations.