 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Holographic Reduced Representations
Sep 05, 2021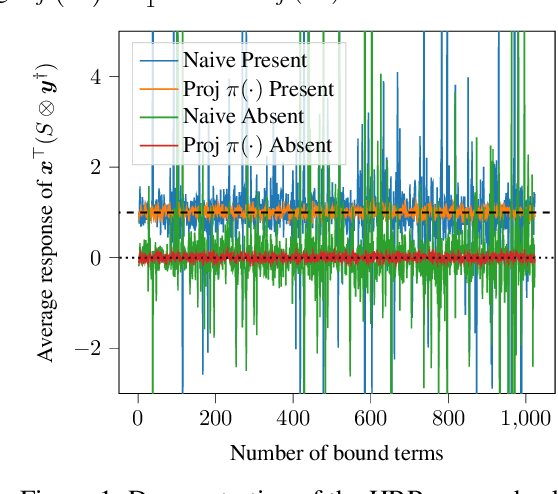
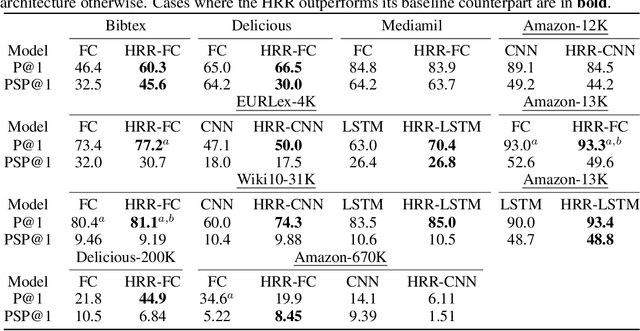

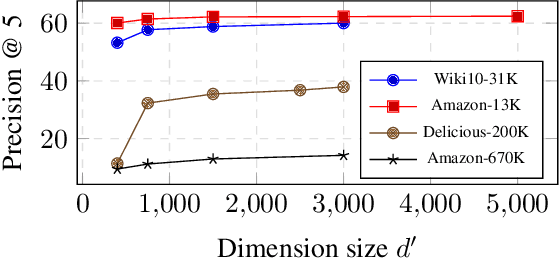
Holographic Reduced Representations (HRR) are a method for performing symbolic AI on top of real-valued vectors \cite{Plate1995} by associating each vector with an abstract concept, and providing mathematical operations to manipulate vectors as if they were classic symbolic objects. This method has seen little use outside of older symbolic AI work and cognitive science. Our goal is to revisit this approach to understand if it is viable for enabling a hybrid neural-symbolic approach to learning as a differentiable component of a deep learning architecture. HRRs today are not effective in a differentiable solution due to numerical instability, a problem we solve by introducing a projection step that forces the vectors to exist in a well behaved point in space. In doing so we improve the concept retrieval efficacy of HRRs by over $100\times$. Using multi-label classification we demonstrate how to leverage the symbolic HRR properties to develop an output layer and loss function that is able to learn effectively, and allows us to investigate some of the pros and cons of an HRR neuro-symbolic learning approach.
Efficient Retrieval Optimized Multi-task Learning
Apr 20, 2021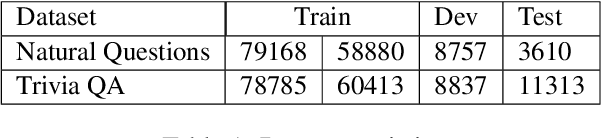
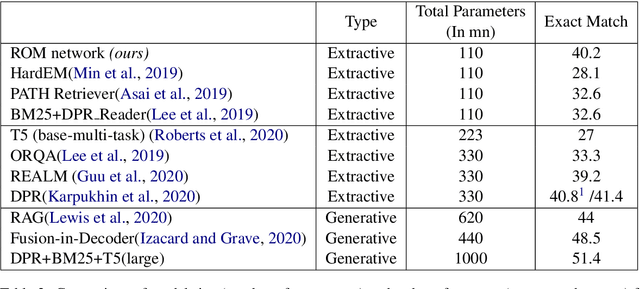
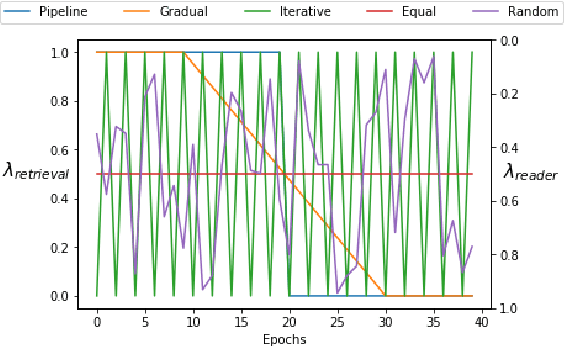
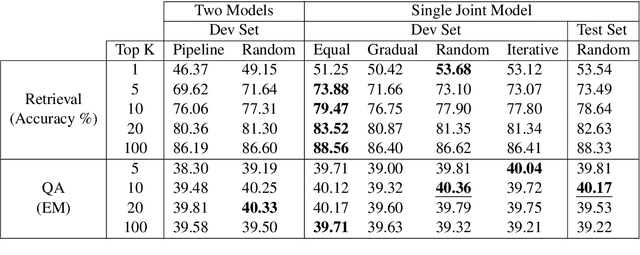
Recently, there have been significant advances in neural methods for tackling knowledge-intensive tasks such as open domain question answering (QA). These advances are fueled by combining large pre-trained language models with learnable retrieval of documents. Majority of these models use separate encoders for learning query representation, passage representation for the retriever and an additional encoder for the downstream task. Using separate encoders for each stage/task occupies a lot of memory and makes it difficult to scale to a large number of tasks. In this paper, we propose a novel Retrieval Optimized Multi-task (ROM) framework for jointly training self-supervised tasks, knowledge retrieval, and extractive question answering. Our ROM approach presents a unified and generalizable framework that enables scaling efficiently to multiple tasks, varying levels of supervision, and optimization choices such as different learning schedules without changing the model architecture. It also provides the flexibility of changing the encoders without changing the architecture of the system. Using our framework, we achieve comparable or better performance than recent methods on QA, while drastically reducing the number of parameters.
Learning from Observations Using a Single Video Demonstration and Human Feedback
Sep 29, 2019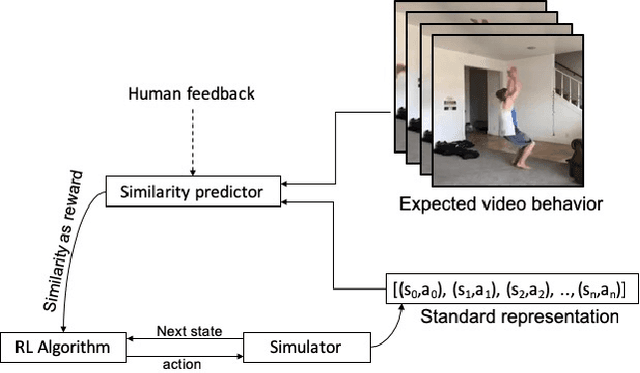
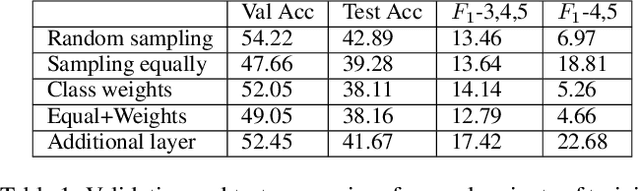
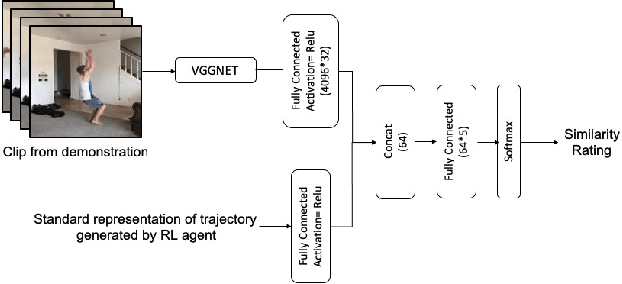
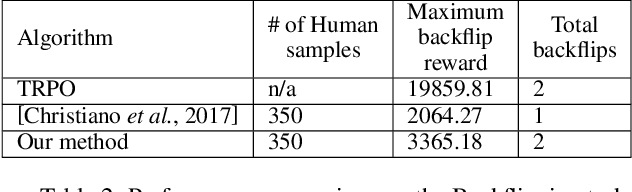
In this paper, we present a method for learning from video demonstrations by using human feedback to construct a mapping between the standard representation of the agent and the visual representation of the demonstration. In this way, we leverage the advantages of both these representations, i.e., we learn the policy using standard state representations, but are able to specify the expected behavior using video demonstration. We train an autonomous agent using a single video demonstration and use human feedback (using numerical similarity rating) to map the standard representation to the visual representation with a neural network. We show the effectiveness of our method by teaching a hopper agent in the MuJoCo to perform a backflip using a single video demonstration generated in MuJoCo as well as from a real-world YouTube video of a person performing a backflip. Additionally, we show that our method can transfer to new tasks, such as hopping, with very little human feedback.