 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIT-Nav: Brain-Inspired Trajectory Memory for Embodied Navigation
Jun 19, 2026Vision-Language Models (VLMs) for embodied navigation rely on selecting a fixed number of frames from a growing trajectory history. As episodes extend, this selection grows increasingly sparse, yet prior work shows no accuracy gain when scaling from 8 to 64 frames, suggesting the bottleneck is not frame quantity but the representation itself. Sparse frame selection cannot capture the structured behavioral signal that long-horizon reasoning requires: turning patterns, cumulative displacement, and path topology. We introduce BIT-Nav (Brain-Inspired Trajectory Memory for Navigation), a framework that augments frozen VLM navigation pipelines with a compact learned trajectory memory. Motivated by hippocampal path integration, where spatial experience is compressed into structured episodic traces rather than stored as raw sensory replay, BIT-Nav trains a Bi-GRU encoder over action and relative pose sequences via a multi-positive InfoNCE contrastive objective on trajectory prefixes sharing the same behavioral intent. The resulting embedding is projected into the VLM token space via a lightweight MLP and injected as a single memory token at each decision step, conditioning the model on structured motion history at constant token cost regardless of episode length
SatReg: Regression-based Neural Architecture Search for Lightweight Satellite Image Segmentation
Apr 11, 2026As Earth-observation workloads move toward onboard and edge processing, remote-sensing segmentation models must operate under tight latency and energy constraints. We present SatReg, a regression-based hardware-aware tuning framework for lightweight remote-sensing segmentation on edge platforms. Using CM-UNet as the teacher architecture, we reduce the search space to two dominant width-related variables, profile a small set of student models on an NVIDIA Jetson Orin Nano, and fit low-order surrogate models for mIoU, latency, and power. Knowledge distillation is used to efficiently train the sampled students. The learned surrogates enable fast selection of near-optimal architecture settings for deployment targets without exhaustive search. Results show that the selected variables affect task accuracy and hardware cost differently, making reduced-space regression a practical strategy for adapting hybrid CNN-Mamba segmentation models to future space-edge systems.
Embodied Foundation Models at the Edge: A Survey of Deployment Constraints and Mitigation Strategies
Mar 19, 2026Deploying foundation models in embodied edge systems is fundamentally a systems problem, not just a problem of model compression. Real-time control must operate within strict size, weight, and power constraints, where memory traffic, compute latency, timing variability, and safety margins interact directly. The Deployment Gauntlet organizes these constraints into eight coupled barriers that determine whether embodied foundation models can run reliably in practice. Across representative edge workloads, autoregressive Vision-Language-Action policies are constrained primarily by memory bandwidth, whereas diffusion-based controllers are limited more by compute latency and sustained execution cost. Reliable deployment therefore depends on system-level co-design across memory, scheduling, communication, and model architecture, including decompositions that separate fast control from slower semantic reasoning.
OA-NBV: Occlusion-Aware Next-Best-View Planning for Human-Centered Active Perception on Mobile Robots
Mar 10, 2026We naturally step sideways or lean to see around the obstacle when our view is blocked, and recover a more informative observation. Enabling robots to make the same kind of viewpoint choice is critical for human-centered operations, including search, triage, and disaster response, where cluttered environments and partial visibility frequently degrade downstream perception. However, many Next-Best-View (NBV) methods primarily optimize generic exploration or long-horizon coverage, and do not explicitly target the immediate goal of obtaining a single usable observation of a partially occluded person under real motion constraints. We present Occlusion-Aware Next-Best-View Planning for Human-Centered Active Perception on Mobile Robots (OA-NBV), an occlusion-aware NBV pipeline that autonomously selects the next traversable viewpoint to obtain a more complete view of an occluded human. OA-NBV integrates perception and motion planning by scoring candidate viewpoints using a target-centric visibility model that accounts for occlusion, target scale, and target completeness, while restricting candidates to feasible robot poses. OA-NBV achieves over 90% success rate in both simulation and real-world trials, while baseline NBV methods degrade sharply under occlusion. Beyond success rate, OA-NBV improves observation quality: compared to the strongest baseline, it increases normalized target area by at least 81% and keypoint visibility by at least 58% across settings, making it a drop-in view-selection module for diverse human-centered downstream tasks.
Mil-SCORE: Benchmarking Long-Context Geospatial Reasoning and Planning in Large Language Models
Jan 29, 2026As large language models (LLMs) are applied to increasingly longer and more complex tasks, there is a growing need for realistic long-context benchmarks that require selective reading and integration of heterogeneous, multi-modal information sources. This need is especially acute for geospatial planning problems, such as those found in planning for large-scale military operations, which demand fast and accurate reasoning over maps, orders, intelligence reports, and other distributed data. To address this gap, we present MilSCORE (Military Scenario Contextual Reasoning), to our knowledge the first scenario-level dataset of expert-authored, multi-hop questions grounded in a complex, simulated military planning scenario used for training. MilSCORE is designed to evaluate high-stakes decision-making and planning, probing LLMs' ability to combine tactical and spatial reasoning across multiple sources and to reason over long-horizon, geospatially rich context. The benchmark includes a diverse set of question types across seven categories targeting both factual recall and multi-step reasoning about constraints, strategy, and spatial analysis. We provide an evaluation protocol and report baseline results for a range of contemporary vision-language models. Our findings highlight substantial headroom on MilSCORE, indicating that current systems struggle with realistic, scenario-level long-context planning, and positioning MilSCORE as a challenging testbed for future work.
MedMambaLite: Hardware-Aware Mamba for Medical Image Classification
Aug 07, 2025AI-powered medical devices have driven the need for real-time, on-device inference such as biomedical image classification. Deployment of deep learning models at the edge is now used for applications such as anomaly detection and classification in medical images. However, achieving this level of performance on edge devices remains challenging due to limitations in model size and computational capacity. To address this, we present MedMambaLite, a hardware-aware Mamba-based model optimized through knowledge distillation for medical image classification. We start with a powerful MedMamba model, integrating a Mamba structure for efficient feature extraction in medical imaging. We make the model lighter and faster in training and inference by modifying and reducing the redundancies in the architecture. We then distill its knowledge into a smaller student model by reducing the embedding dimensions. The optimized model achieves 94.5% overall accuracy on 10 MedMNIST datasets. It also reduces parameters 22.8x compared to MedMamba. Deployment on an NVIDIA Jetson Orin Nano achieves 35.6 GOPS/J energy per inference. This outperforms MedMamba by 63% improvement in energy per inference.
Multi-RAG: A Multimodal Retrieval-Augmented Generation System for Adaptive Video Understanding
May 29, 2025To effectively engage in human society, the ability to adapt, filter information, and make informed decisions in ever-changing situations is critical. As robots and intelligent agents become more integrated into human life, there is a growing opportunity-and need-to offload the cognitive burden on humans to these systems, particularly in dynamic, information-rich scenarios. To fill this critical need, we present Multi-RAG, a multimodal retrieval-augmented generation system designed to provide adaptive assistance to humans in information-intensive circumstances. Our system aims to improve situational understanding and reduce cognitive load by integrating and reasoning over multi-source information streams, including video, audio, and text. As an enabling step toward long-term human-robot partnerships, Multi-RAG explores how multimodal information understanding can serve as a foundation for adaptive robotic assistance in dynamic, human-centered situations. To evaluate its capability in a realistic human-assistance proxy task, we benchmarked Multi-RAG on the MMBench-Video dataset, a challenging multimodal video understanding benchmark. Our system achieves superior performance compared to existing open-source video large language models (Video-LLMs) and large vision-language models (LVLMs), while utilizing fewer resources and less input data. The results demonstrate Multi- RAG's potential as a practical and efficient foundation for future human-robot adaptive assistance systems in dynamic, real-world contexts.
RAFT: Robust Augmentation of FeaTures for Image Segmentation
May 07, 2025Image segmentation is a powerful computer vision technique for scene understanding. However, real-world deployment is stymied by the need for high-quality, meticulously labeled datasets. Synthetic data provides high-quality labels while reducing the need for manual data collection and annotation. However, deep neural networks trained on synthetic data often face the Syn2Real problem, leading to poor performance in real-world deployments. To mitigate the aforementioned gap in image segmentation, we propose RAFT, a novel framework for adapting image segmentation models using minimal labeled real-world data through data and feature augmentations, as well as active learning. To validate RAFT, we perform experiments on the synthetic-to-real "SYNTHIA->Cityscapes" and "GTAV->Cityscapes" benchmarks. We managed to surpass the previous state of the art, HALO. SYNTHIA->Cityscapes experiences an improvement in mIoU* upon domain adaptation of 2.1%/79.9%, and GTAV->Cityscapes experiences a 0.4%/78.2% improvement in mIoU. Furthermore, we test our approach on the real-to-real benchmark of "Cityscapes->ACDC", and again surpass HALO, with a gain in mIoU upon adaptation of 1.3%/73.2%. Finally, we examine the effect of the allocated annotation budget and various components of RAFT upon the final transfer mIoU.
ATLASv2: LLM-Guided Adaptive Landmark Acquisition and Navigation on the Edge
Apr 15, 2025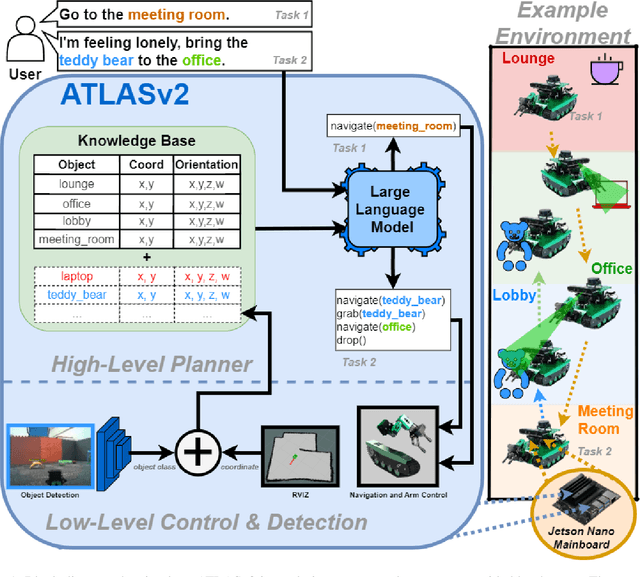
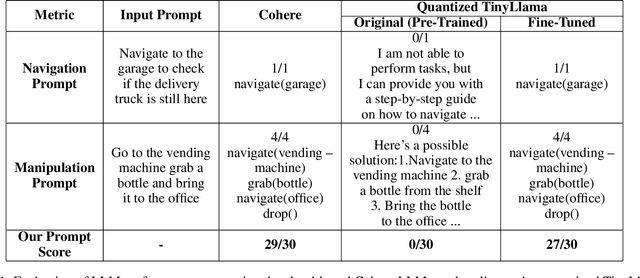

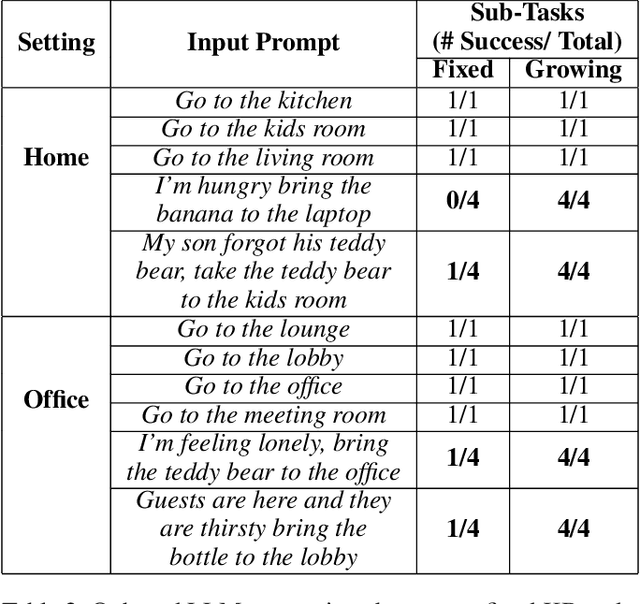
Autonomous systems deployed on edge devices face significant challenges, including resource constraints, real-time processing demands, and adapting to dynamic environments. This work introduces ATLASv2, a novel system that integrates a fine-tuned TinyLLM, real-time object detection, and efficient path planning to enable hierarchical, multi-task navigation and manipulation all on the edge device, Jetson Nano. ATLASv2 dynamically expands its navigable landmarks by detecting and localizing objects in the environment which are saved to its internal knowledge base to be used for future task execution. We evaluate ATLASv2 in real-world environments, including a handcrafted home and office setting constructed with diverse objects and landmarks. Results show that ATLASv2 effectively interprets natural language instructions, decomposes them into low-level actions, and executes tasks with high success rates. By leveraging generative AI in a fully on-board framework, ATLASv2 achieves optimized resource utilization with minimal prompting latency and power consumption, bridging the gap between simulated environments and real-world applications.
MambaLiteSR: Image Super-Resolution with Low-Rank Mamba using Knowledge Distillation
Feb 19, 2025


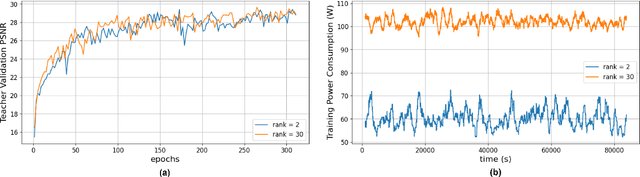
Generative Artificial Intelligence (AI) has gained significant attention in recent years, revolutionizing various applications across industries. Among these, advanced vision models for image super-resolution are in high demand, particularly for deployment on edge devices where real-time processing is crucial. However, deploying such models on edge devices is challenging due to limited computing power and memory. In this paper, we present MambaLiteSR, a novel lightweight image Super-Resolution (SR) model that utilizes the architecture of Vision Mamba. It integrates State Space Blocks and a reconstruction module for efficient feature extraction. To optimize efficiency without affecting performance, MambaLiteSR employs knowledge distillation to transfer key insights from a larger Mamba-based teacher model to a smaller student model via hyperparameter tuning. Through mathematical analysis of model parameters and their impact on PSNR, we identify key factors and adjust them accordingly. Our comprehensive evaluation shows that MambaLiteSR outperforms state-of-the-art edge SR methods by reducing power consumption while maintaining competitive PSNR and SSIM scores across benchmark datasets. It also reduces power usage during training via low-rank approximation. Moreover, MambaLiteSR reduces parameters with minimal performance loss, enabling efficient deployment of generative AI models on resource-constrained devices. Deployment on the embedded NVIDIA Jetson Orin Nano confirms the superior balance of MambaLiteSR size, latency, and efficiency. Experiments show that MambaLiteSR achieves performance comparable to both the baseline and other edge models while using 15% fewer parameters. It also improves power consumption by up to 58% compared to state-of-the-art SR edge models, all while maintaining low energy use during training.