 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinyVQA: Compact Multimodal Deep Neural Network for Visual Question Answering on Resource-Constrained Devices
Apr 04, 2024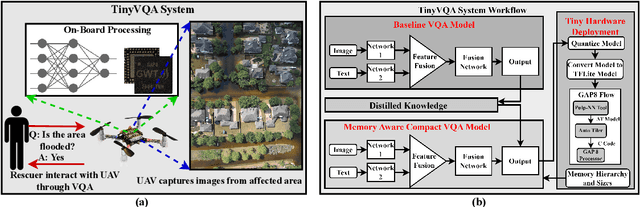
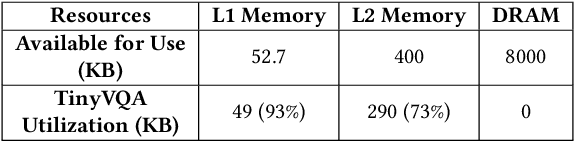
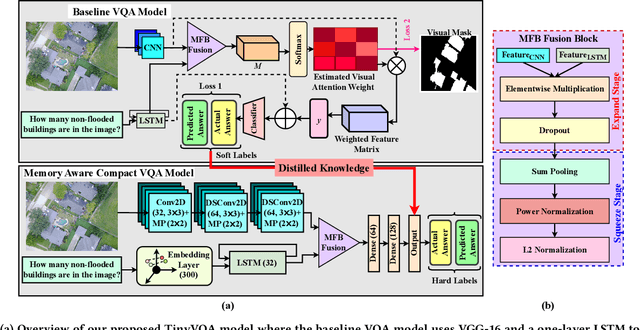
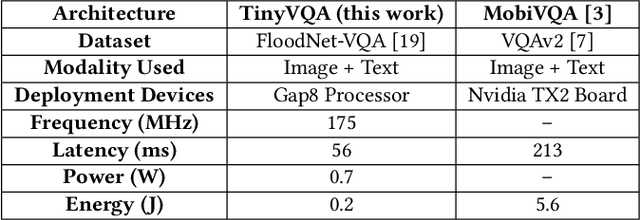
Traditional machine learning models often require powerful hardware, making them unsuitable for deployment on resource-limited devices. Tiny Machine Learning (tinyML) has emerged as a promising approach for running machine learning models on these devices, but integrating multiple data modalities into tinyML models still remains a challenge due to increased complexity, latency, and power consumption. This paper proposes TinyVQA, a novel multimodal deep neural network for visual question answering tasks that can be deployed on resource-constrained tinyML hardware. TinyVQA leverages a supervised attention-based model to learn how to answer questions about images using both vision and language modalities. Distilled knowledge from the supervised attention-based VQA model trains the memory aware compact TinyVQA model and low bit-width quantization technique is employed to further compress the model for deployment on tinyML devices. The TinyVQA model was evaluated on the FloodNet dataset, which is used for post-disaster damage assessment. The compact model achieved an accuracy of 79.5%, demonstrating the effectiveness of TinyVQA for real-world applications. Additionally, the model was deployed on a Crazyflie 2.0 drone, equipped with an AI deck and GAP8 microprocessor. The TinyVQA model achieved low latencies of 56 ms and consumes 693 mW power while deployed on the tiny drone, showcasing its suitability for resource-constrained embedded systems.
Polar-VQA: Visual Question Answering on Remote Sensed Ice sheet Imagery from Polar Region
Mar 13, 2023For glaciologists, studying ice sheets from the polar regions is critical. With the advancement of deep learning techniques, we can now extract high-level information from the ice sheet data (e.g., estimating the ice layer thickness, predicting the ice accumulation for upcoming years, etc.). However, a vision-based conversational deep learning approach has not been explored yet, where scientists can get information by asking questions about images. In this paper, we have introduced the task of Visual Question Answering (VQA) on remote-sensed ice sheet imagery. To study, we have presented a unique VQA dataset, Polar-VQA, in this study. All the images in this dataset were collected using four types of airborne radars. The main objective of this research is to highlight the importance of VQA in the context of ice sheet research and conduct a baseline study of existing VQA approaches on Polar-VQA dataset.
VQA-Aid: Visual Question Answering for Post-Disaster Damage Assessment and Analysis
Jun 19, 2021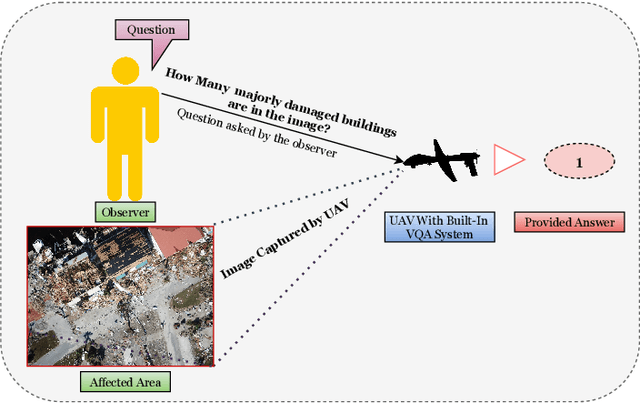
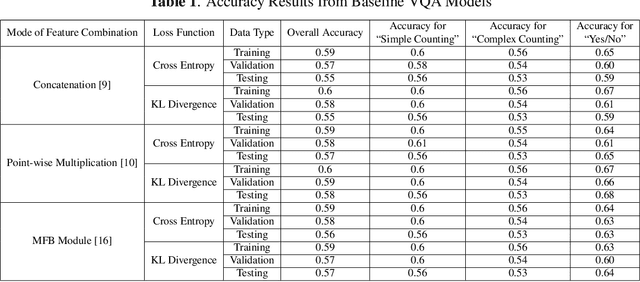

Visual Question Answering system integrated with Unmanned Aerial Vehicle (UAV) has a lot of potentials to advance the post-disaster damage assessment purpose. Providing assistance to affected areas is highly dependent on real-time data assessment and analysis. Scope of the Visual Question Answering is to understand the scene and provide query related answer which certainly faster the recovery process after any disaster. In this work, we address the importance of \textit{visual question answering (VQA)} task for post-disaster damage assessment by presenting our recently developed VQA dataset called \textit{HurMic-VQA} collected during hurricane Michael, and comparing the performances of baseline VQA models.
FloodNet: A High Resolution Aerial Imagery Dataset for Post Flood Scene Understanding
Dec 05, 2020
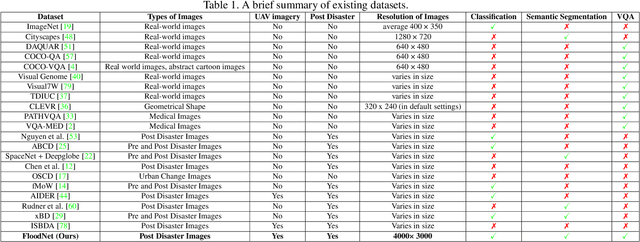
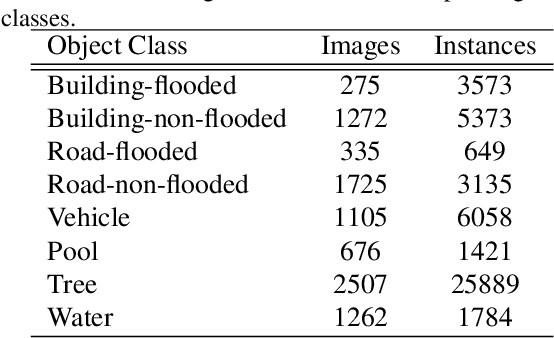
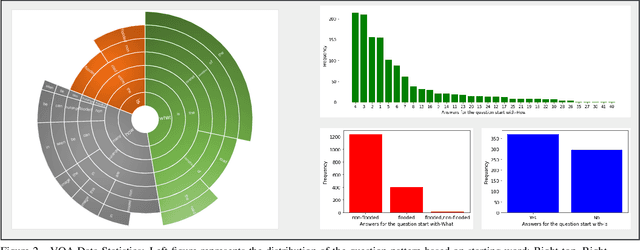
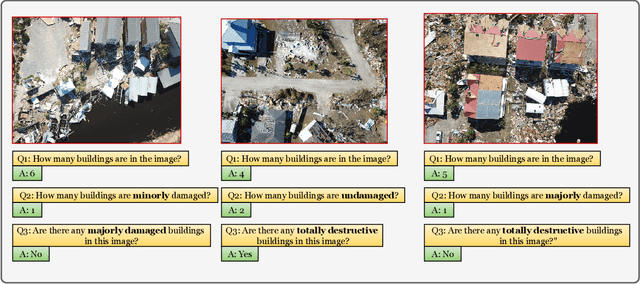
Visual scene understanding is the core task in making any crucial decision in any computer vision system. Although popular computer vision datasets like Cityscapes, MS-COCO, PASCAL provide good benchmarks for several tasks (e.g. image classification, segmentation, object detection), these datasets are hardly suitable for post disaster damage assessments. On the other hand, existing natural disaster datasets include mainly satellite imagery which have low spatial resolution and a high revisit period. Therefore, they do not have a scope to provide quick and efficient damage assessment tasks. Unmanned Aerial Vehicle(UAV) can effortlessly access difficult places during any disaster and collect high resolution imagery that is required for aforementioned tasks of computer vision. To address these issues we present a high resolution UAV imagery, FloodNet, captured after the hurricane Harvey. This dataset demonstrates the post flooded damages of the affected areas. The images are labeled pixel-wise for semantic segmentation task and questions are produced for the task of visual question answering. FloodNet poses several challenges including detection of flooded roads and buildings and distinguishing between natural water and flooded water. With the advancement of deep learning algorithms, we can analyze the impact of any disaster which can make a precise understanding of the affected areas. In this paper, we compare and contrast the performances of baseline methods for image classification, semantic segmentation, and visual question answering on our dataset.