 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHonest Lying: Understanding Memory Confabulation in Reflexive Agents
May 28, 2026Reflexion-style agents rely on self-generated reflections as memory, implicitly assuming that agents can accurately diagnose their own failures.We show that this assumption can fail systematically: across ALFWorld and HumanEval, agents store confident but incorrect interpretations of the task and continue acting on them across trials,even though the environment resets to the correct task each time. We call this failure mode memory confabulation and introduce the Reflection Repetition Rate (RRR), a log-based metric that detects repeated reliance on incorrect reflective content.Using RRR, we identify 16 frozen environments in ALFWorld, where 0 of 121 reflections mention the correct target object, and 4 analogous cases in HumanEval. Our mitigation replaces open-ended self-diagnosis with programmatic extraction of trajectory-level failure signals, increasing correct object mention from 0% to 86%, reducing RRR from 0.64 to 0.10, and solving 3 of 16 frozen ALFWorld environments, suggesting that reflective memory can reinforce false beliefs rather than correct them.
Learning to Segment using Summary Statistics and Weak Supervision
May 04, 2026Medical experts often manually segment images to obtain diagnostic statistics and discard the resulting annotations. We aim to train segmentation models to alleviate this burden, but constrained to the retained summary statistics (e.g., the area of the annotated region). Empirical results suggest that statistics alone are insufficient for this task, but adding weak information in the form of a few pixels within the area of interest significantly improves performance. We use a novel loss function that combines terms for image reconstruction quality, matching to summary statistics, and overlap between the predicted foreground and the weak supervisory signal. Experiments on standard image, ultrasound (breast cancer), and Computed Tomography (CT) scan (kidney tumors) data demonstrate the utility and potential of the approach.
LLM-Guided Agentic Floor Plan Parsing for Accessible Indoor Navigation of Blind and Low-Vision People
Apr 27, 2026Indoor navigation remains a critical accessibility challenge for the blind and low-vision (BLV) individuals, as existing solutions rely on costly per-building infrastructure. We present an agentic framework that converts a single floor plan image into a structured, retrievable knowledge base to generate safe, accessible navigation instructions with lightweight infrastructure. The system has two phases: a multi-agent module that parses the floor plan into a spatial knowledge graph through a self-correcting pipeline with iterative retry loops and corrective feedback; and a Path Planner that generates accessible navigation instructions, with a Safety Evaluator agent assessing potential hazards along each route. We evaluate the system on the real-world UMBC Math and Psychology building (floors MP-1 and MP-3) and on the CVC-FP benchmark. On MP-1, we achieve success rates of 92.31%, 76.92%, and 61.54% for short, medium, and long routes, outperforming the strongest single-call baseline (Claude 3.7 Sonnet) at 84.62%, 69.23%, and 53.85%. On MP-3, we reach 76.92%, 61.54%, and 38.46%, compared to the best baseline at 61.54%, 46.15%, and 23.08%. These results show consistent gains over single-call LLM baselines and demonstrate that our workflow is a scalable solution for accessible indoor navigation for BLV individuals.
Care-Conditioned Neuromodulation for Autonomy-Preserving Supportive Dialogue Agents
Apr 02, 2026Large language models deployed in supportive or advisory roles must balance helpfulness with preservation of user autonomy, yet standard alignment methods primarily optimize for helpfulness and harmlessness without explicitly modeling relational risks such as dependency reinforcement, overprotection, or coercive guidance. We introduce Care-Conditioned Neuromodulation (CCN), a state-dependent control framework in which a learned scalar signal derived from structured user state and dialogue context conditions response generation and candidate selection. We formalize this setting as an autonomy-preserving alignment problem and define a utility function that rewards autonomy support and helpfulness while penalizing dependency and coercion. We also construct a benchmark of relational failure modes in multi-turn dialogue, including reassurance dependence, manipulative care, overprotection, and boundary inconsistency. On this benchmark, care-conditioned candidate generation combined with utility-based reranking improves autonomy-preserving utility by +0.25 over supervised fine-tuning and +0.07 over preference optimization baselines while maintaining comparable supportiveness. Pilot human evaluation and zero-shot transfer to real emotional-support conversations show directional agreement with automated metrics. These results suggest that state-dependent control combined with utility-based selection is a practical approach to multi-objective alignment in autonomy-sensitive dialogue.
ASEHybrid: When Geometry Matters Beyond Homophily in Graph Neural Networks
Jan 26, 2026Standard message-passing graph neural networks (GNNs) often struggle on graphs with low homophily, yet homophily alone does not explain this behavior, as graphs with similar homophily levels can exhibit markedly different performance and some heterophilous graphs remain easy for vanilla GCNs. Recent work suggests that label informativeness (LI), the mutual information between labels of adjacent nodes, provides a more faithful characterization of when graph structure is useful. In this work, we develop a unified theoretical framework that connects curvature-guided rewiring and positional geometry through the lens of label informativeness, and instantiate it in a practical geometry-aware architecture, ASEHybrid. Our analysis provides a necessary-and-sufficient characterization of when geometry-aware GNNs can improve over feature-only baselines: such gains are possible if and only if graph structure carries label-relevant information beyond node features. Theoretically, we relate adjusted homophily and label informativeness to the spectral behavior of label signals under Laplacian smoothing, show that degree-based Forman curvature does not increase expressivity beyond the one-dimensional Weisfeiler--Lehman test but instead reshapes information flow, and establish convergence and Lipschitz stability guarantees for a curvature-guided rewiring process. Empirically, we instantiate ASEHybrid using Forman curvature and Laplacian positional encodings and conduct controlled ablations on Chameleon, Squirrel, Texas, Tolokers, and Minesweeper, observing gains precisely on label-informative heterophilous benchmarks where graph structure provides label-relevant information beyond node features, and no meaningful improvement in high-baseline regimes.
MDToC: Metacognitive Dynamic Tree of Concepts for Boosting Mathematical Problem-Solving of Large Language Models
Dec 21, 2025Despite advances in mathematical reasoning capabilities, Large Language Models (LLMs) still struggle with calculation verification when using established prompting techniques. We present MDToC (Metacognitive Dynamic Tree of Concepts), a three-phase approach that constructs a concept tree, develops accuracy-verified calculations for each concept, and employs majority voting to evaluate competing solutions. Evaluations across CHAMP, MATH, and Game-of-24 benchmarks demonstrate our MDToC's effectiveness, with GPT-4-Turbo achieving 58.1\% on CHAMP, 86.6\% on MATH, and 85\% on Game-of-24 - outperforming GoT by 5\%, 5.4\%, and 4\% on all these tasks, respectively, without hand-engineered hints. MDToC consistently surpasses existing prompting methods across all backbone models, yielding improvements of up to 7.6\% over ToT and 6.2\% over GoT, establishing metacognitive calculation verification as a promising direction for enhanced mathematical reasoning.
Floorplan2Guide: LLM-Guided Floorplan Parsing for BLV Indoor Navigation
Dec 13, 2025Indoor navigation remains a critical challenge for people with visual impairments. The current solutions mainly rely on infrastructure-based systems, which limit their ability to navigate safely in dynamic environments. We propose a novel navigation approach that utilizes a foundation model to transform floor plans into navigable knowledge graphs and generate human-readable navigation instructions. Floorplan2Guide integrates a large language model (LLM) to extract spatial information from architectural layouts, reducing the manual preprocessing required by earlier floorplan parsing methods. Experimental results indicate that few-shot learning improves navigation accuracy in comparison to zero-shot learning on simulated and real-world evaluations. Claude 3.7 Sonnet achieves the highest accuracy among the evaluated models, with 92.31%, 76.92%, and 61.54% on the short, medium, and long routes, respectively, under 5-shot prompting of the MP-1 floor plan. The success rate of graph-based spatial structure is 15.4% higher than that of direct visual reasoning among all models, which confirms that graphical representation and in-context learning enhance navigation performance and make our solution more precise for indoor navigation of Blind and Low Vision (BLV) users.
Hierarchical Learning for Maze Navigation: Emergence of Mental Representations via Second-Order Learning
Sep 17, 2025Mental representation, characterized by structured internal models mirroring external environments, is fundamental to advanced cognition but remains challenging to investigate empirically. Existing theory hypothesizes that second-order learning -- learning mechanisms that adapt first-order learning (i.e., learning about the task/domain) -- promotes the emergence of such environment-cognition isomorphism. In this paper, we empirically validate this hypothesis by proposing a hierarchical architecture comprising a Graph Convolutional Network (GCN) as a first-order learner and an MLP controller as a second-order learner. The GCN directly maps node-level features to predictions of optimal navigation paths, while the MLP dynamically adapts the GCN's parameters when confronting structurally novel maze environments. We demonstrate that second-order learning is particularly effective when the cognitive system develops an internal mental map structurally isomorphic to the environment. Quantitative and qualitative results highlight significant performance improvements and robust generalization on unseen maze tasks, providing empirical support for the pivotal role of structured mental representations in maximizing the effectiveness of second-order learning.
One Model, Two Minds: A Context-Gated Graph Learner that Recreates Human Biases
Sep 10, 2025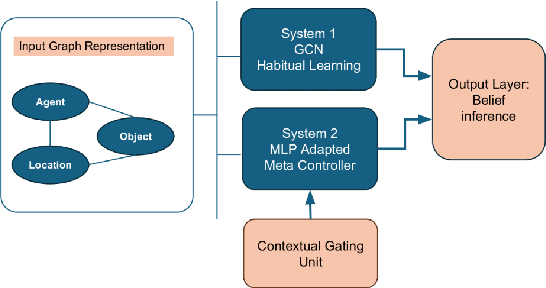

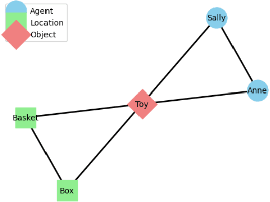

We introduce a novel Theory of Mind (ToM) framework inspired by dual-process theories from cognitive science, integrating a fast, habitual graph-based reasoning system (System 1), implemented via graph convolutional networks (GCNs), and a slower, context-sensitive meta-adaptive learning system (System 2), driven by meta-learning techniques. Our model dynamically balances intuitive and deliberative reasoning through a learned context gate mechanism. We validate our architecture on canonical false-belief tasks and systematically explore its capacity to replicate hallmark cognitive biases associated with dual-process theory, including anchoring, cognitive-load fatigue, framing effects, and priming effects. Experimental results demonstrate that our dual-process approach closely mirrors human adaptive behavior, achieves robust generalization to unseen contexts, and elucidates cognitive mechanisms underlying reasoning biases. This work bridges artificial intelligence and cognitive theory, paving the way for AI systems exhibiting nuanced, human-like social cognition and adaptive decision-making capabilities.
Skin-SOAP: A Weakly Supervised Framework for Generating Structured SOAP Notes
Aug 07, 2025Skin carcinoma is the most prevalent form of cancer globally, accounting for over $8 billion in annual healthcare expenditures. Early diagnosis, accurate and timely treatment are critical to improving patient survival rates. In clinical settings, physicians document patient visits using detailed SOAP (Subjective, Objective, Assessment, and Plan) notes. However, manually generating these notes is labor-intensive and contributes to clinician burnout. In this work, we propose skin-SOAP, a weakly supervised multimodal framework to generate clinically structured SOAP notes from limited inputs, including lesion images and sparse clinical text. Our approach reduces reliance on manual annotations, enabling scalable, clinically grounded documentation while alleviating clinician burden and reducing the need for large annotated data. Our method achieves performance comparable to GPT-4o, Claude, and DeepSeek Janus Pro across key clinical relevance metrics. To evaluate this clinical relevance, we introduce two novel metrics MedConceptEval and Clinical Coherence Score (CCS) which assess semantic alignment with expert medical concepts and input features, respectively.