 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildfireVLM: AI-powered Analysis for Early Wildfire Detection and Risk Assessment Using Satellite Imagery
Feb 09, 2026Wildfires are a growing threat to ecosystems, human lives, and infrastructure, with their frequency and intensity rising due to climate change and human activities. Early detection is critical, yet satellite-based monitoring remains challenging due to faint smoke signals, dynamic weather conditions, and the need for real-time analysis over large areas. We introduce WildfireVLM, an AI framework that combines satellite imagery wildfire detection with language-driven risk assessment. We construct a labeled wildfire and smoke dataset using imagery from Landsat-8/9, GOES-16, and other publicly available Earth observation sources, including harmonized products with aligned spectral bands. WildfireVLM employs YOLOv12 to detect fire zones and smoke plumes, leveraging its ability to detect small, complex patterns in satellite imagery. We integrate Multimodal Large Language Models (MLLMs) that convert detection outputs into contextualized risk assessments and prioritized response recommendations for disaster management. We validate the quality of risk reasoning using an LLM-as-judge evaluation with a shared rubric. The system is deployed using a service-oriented architecture that supports real-time processing, visual risk dashboards, and long-term wildfire tracking, demonstrating the value of combining computer vision with language-based reasoning for scalable wildfire monitoring.
Skin-SOAP: A Weakly Supervised Framework for Generating Structured SOAP Notes
Aug 07, 2025Skin carcinoma is the most prevalent form of cancer globally, accounting for over $8 billion in annual healthcare expenditures. Early diagnosis, accurate and timely treatment are critical to improving patient survival rates. In clinical settings, physicians document patient visits using detailed SOAP (Subjective, Objective, Assessment, and Plan) notes. However, manually generating these notes is labor-intensive and contributes to clinician burnout. In this work, we propose skin-SOAP, a weakly supervised multimodal framework to generate clinically structured SOAP notes from limited inputs, including lesion images and sparse clinical text. Our approach reduces reliance on manual annotations, enabling scalable, clinically grounded documentation while alleviating clinician burden and reducing the need for large annotated data. Our method achieves performance comparable to GPT-4o, Claude, and DeepSeek Janus Pro across key clinical relevance metrics. To evaluate this clinical relevance, we introduce two novel metrics MedConceptEval and Clinical Coherence Score (CCS) which assess semantic alignment with expert medical concepts and input features, respectively.
Towards Scalable SOAP Note Generation: A Weakly Supervised Multimodal Framework
Jun 12, 2025



Skin carcinoma is the most prevalent form of cancer globally, accounting for over $8 billion in annual healthcare expenditures. In clinical settings, physicians document patient visits using detailed SOAP (Subjective, Objective, Assessment, and Plan) notes. However, manually generating these notes is labor-intensive and contributes to clinician burnout. In this work, we propose a weakly supervised multimodal framework to generate clinically structured SOAP notes from limited inputs, including lesion images and sparse clinical text. Our approach reduces reliance on manual annotations, enabling scalable, clinically grounded documentation while alleviating clinician burden and reducing the need for large annotated data. Our method achieves performance comparable to GPT-4o, Claude, and DeepSeek Janus Pro across key clinical relevance metrics. To evaluate clinical quality, we introduce two novel metrics MedConceptEval and Clinical Coherence Score (CCS) which assess semantic alignment with expert medical concepts and input features, respectively.
MedGrad E-CLIP: Enhancing Trust and Transparency in AI-Driven Skin Lesion Diagnosis
Jan 12, 2025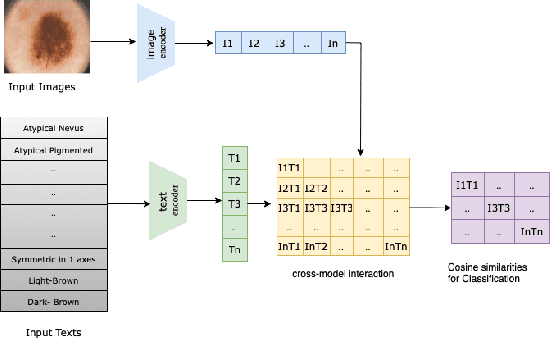
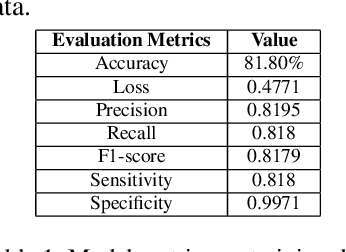
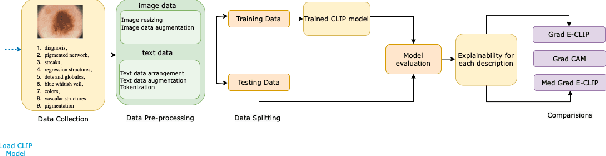
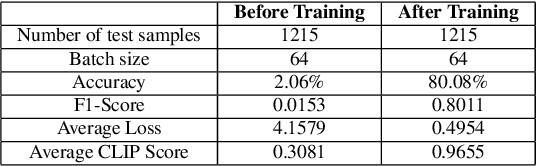
As deep learning models gain attraction in medical data, ensuring transparent and trustworthy decision-making is essential. In skin cancer diagnosis, while advancements in lesion detection and classification have improved accuracy, the black-box nature of these methods poses challenges in understanding their decision processes, leading to trust issues among physicians. This study leverages the CLIP (Contrastive Language-Image Pretraining) model, trained on different skin lesion datasets, to capture meaningful relationships between visual features and diagnostic criteria terms. To further enhance transparency, we propose a method called MedGrad E-CLIP, which builds on gradient-based E-CLIP by incorporating a weighted entropy mechanism designed for complex medical imaging like skin lesions. This approach highlights critical image regions linked to specific diagnostic descriptions. The developed integrated pipeline not only classifies skin lesions by matching corresponding descriptions but also adds an essential layer of explainability developed especially for medical data. By visually explaining how different features in an image relates to diagnostic criteria, this approach demonstrates the potential of advanced vision-language models in medical image analysis, ultimately improving transparency, robustness, and trust in AI-driven diagnostic systems.
Exploiting Adaptive Contextual Masking for Aspect-Based Sentiment Analysis
Feb 21, 2024



Aspect-Based Sentiment Analysis (ABSA) is a fine-grained linguistics problem that entails the extraction of multifaceted aspects, opinions, and sentiments from the given text. Both standalone and compound ABSA tasks have been extensively used in the literature to examine the nuanced information present in online reviews and social media posts. Current ABSA methods often rely on static hyperparameters for attention-masking mechanisms, which can struggle with context adaptation and may overlook the unique relevance of words in varied situations. This leads to challenges in accurately analyzing complex sentences containing multiple aspects with differing sentiments. In this work, we present adaptive masking methods that remove irrelevant tokens based on context to assist in Aspect Term Extraction and Aspect Sentiment Classification subtasks of ABSA. We show with our experiments that the proposed methods outperform the baseline methods in terms of accuracy and F1 scores on four benchmark online review datasets. Further, we show that the proposed methods can be extended with multiple adaptations and demonstrate a qualitative analysis of the proposed approach using sample text for aspect term extraction.
Modeling Political Orientation of Social Media Posts: An Extended Analysis
Nov 21, 2023



Developing machine learning models to characterize political polarization on online social media presents significant challenges. These challenges mainly stem from various factors such as the lack of annotated data, presence of noise in social media datasets, and the sheer volume of data. The common research practice typically examines the biased structure of online user communities for a given topic or qualitatively measuring the impacts of polarized topics on social media. However, there is limited work focusing on analyzing polarization at the ground-level, specifically in the social media posts themselves. Such existing analysis heavily relies on annotated data, which often requires laborious human labeling, offers labels only to specific problems, and lacks the ability to determine the near-future bias state of a social media conversations. Understanding the degree of political orientation conveyed in social media posts is crucial for quantifying the bias of online user communities and investigating the spread of polarized content. In this work, we first introduce two heuristic methods that leverage on news media bias and post content to label social media posts. Next, we compare the efficacy and quality of heuristically labeled dataset with a randomly sampled human-annotated dataset. Additionally, we demonstrate that current machine learning models can exhibit improved performance in predicting political orientation of social media posts, employing both traditional supervised learning and few-shot learning setups. We conduct experiments using the proposed heuristic methods and machine learning approaches to predict the political orientation of posts collected from two social media forums with diverse political ideologies: Gab and Twitter.
Quantitative Analysis of Forecasting Models:In the Aspect of Online Political Bias
Sep 19, 2023
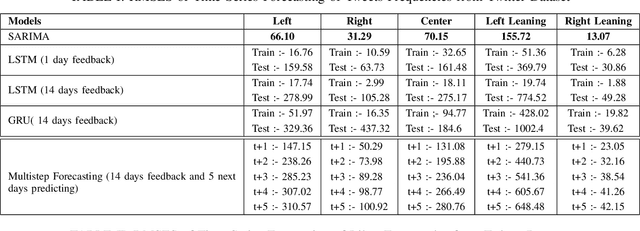
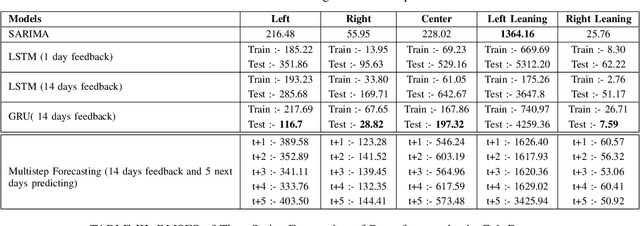
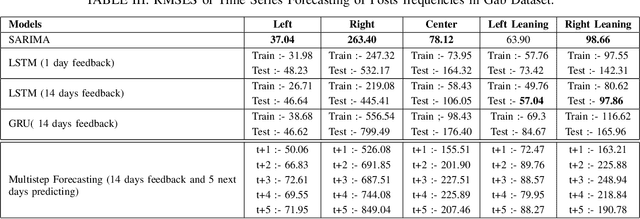
Understanding and mitigating political bias in online social media platforms are crucial tasks to combat misinformation and echo chamber effects. However, characterizing political bias temporally using computational methods presents challenges due to the high frequency of noise in social media datasets. While existing research has explored various approaches to political bias characterization, the ability to forecast political bias and anticipate how political conversations might evolve in the near future has not been extensively studied. In this paper, we propose a heuristic approach to classify social media posts into five distinct political leaning categories. Since there is a lack of prior work on forecasting political bias, we conduct an in-depth analysis of existing baseline models to identify which model best fits to forecast political leaning time series. Our approach involves utilizing existing time series forecasting models on two social media datasets with different political ideologies, specifically Twitter and Gab. Through our experiments and analyses, we seek to shed light on the challenges and opportunities in forecasting political bias in social media platforms. Ultimately, our work aims to pave the way for developing more effective strategies to mitigate the negative impact of political bias in the digital realm.
Learning Unbiased News Article Representations: A Knowledge-Infused Approach
Sep 12, 2023



Quantification of the political leaning of online news articles can aid in understanding the dynamics of political ideology in social groups and measures to mitigating them. However, predicting the accurate political leaning of a news article with machine learning models is a challenging task. This is due to (i) the political ideology of a news article is defined by several factors, and (ii) the innate nature of existing learning models to be biased with the political bias of the news publisher during the model training. There is only a limited number of methods to study the political leaning of news articles which also do not consider the algorithmic political bias which lowers the generalization of machine learning models to predict the political leaning of news articles published by any new news publishers. In this work, we propose a knowledge-infused deep learning model that utilizes relatively reliable external data resources to learn unbiased representations of news articles using their global and local contexts. We evaluate the proposed model by setting the data in such a way that news domains or news publishers in the test set are completely unseen during the training phase. With this setup we show that the proposed model mitigates algorithmic political bias and outperforms baseline methods to predict the political leaning of news articles with up to 73% accuracy.
A Machine Learning Pipeline to Examine Political Bias with Congressional Speeches
Sep 18, 2021
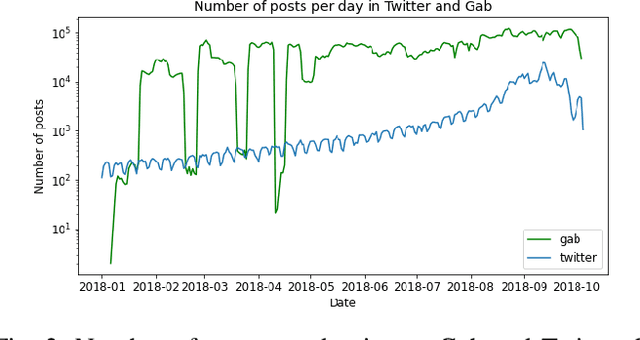
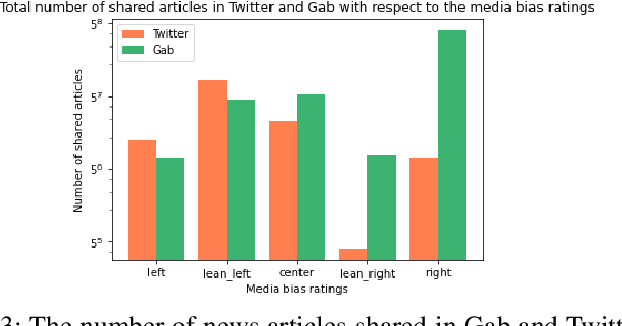
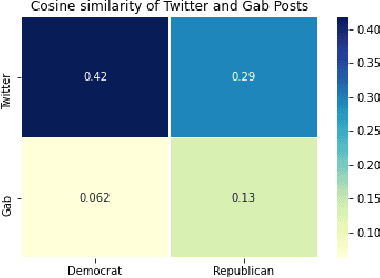
Computational methods to model political bias in social media involve several challenges due to heterogeneity, high-dimensional, multiple modalities, and the scale of the data. Political bias in social media has been studied in multiple viewpoints like media bias, political ideology, echo chambers, and controversies using machine learning pipelines. Most of the current methods rely heavily on the manually-labeled ground-truth data for the underlying political bias prediction tasks. Limitations of such methods include human-intensive labeling, labels related to only a specific problem, and the inability to determine the near future bias state of a social media conversation. In this work, we address such problems and give machine learning approaches to study political bias in two ideologically diverse social media forums: Gab and Twitter without the availability of human-annotated data. Our proposed methods exploit the use of transcripts collected from political speeches in US congress to label the data and achieve the highest accuracy of 70.5% and 65.1% in Twitter and Gab data respectively to predict political bias. We also present a machine learning approach that combines features from cascades and text to forecast cascade's political bias with an accuracy of about 85%.