 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyGHT: Physics-Guided HyperGraph Transformer for Signal Purification at the HL-LHC
Feb 24, 2026The High-Luminosity Large Hadron Collider (HL-LHC) at CERN will produce unprecedented datasets capable of revealing fundamental properties of the universe. However, realizing its discovery potential faces a significant challenge: extracting small signal fractions from overwhelming backgrounds dominated by approximately 200 simultaneous pileup collisions. This extreme noise severely distorts the physical observables required for accurate reconstruction. To address this, we introduce the Physics-Guided Hypergraph Transformer (PhyGHT), a hybrid architecture that combines distance-aware local graph attention with global self-attention to mirror the physical topology of particle showers formed in proton-proton collisions. Crucially, we integrate a Pileup Suppression Gate (PSG), an interpretable, physics-constrained mechanism that explicitly learns to filter soft noise prior to hypergraph aggregation. To validate our approach, we release a novel simulated dataset of top-quark pair production to model extreme pileup conditions. PhyGHT outperforms state-of-the-art baselines from the ATLAS and CMS experiments in predicting the signal's energy and mass correction factors. By accurately reconstructing the top quark's invariant mass, we demonstrate how machine learning innovation and interdisciplinary collaboration can directly advance scientific discovery at the frontiers of experimental physics and enhance the HL-LHC's discovery potential. The dataset and code are available at https://github.com/rAIson-Lab/PhyGHT
G$^{2}$D: Boosting Multimodal Learning with Gradient-Guided Distillation
Jun 26, 2025Multimodal learning aims to leverage information from diverse data modalities to achieve more comprehensive performance. However, conventional multimodal models often suffer from modality imbalance, where one or a few modalities dominate model optimization, leading to suboptimal feature representation and underutilization of weak modalities. To address this challenge, we introduce Gradient-Guided Distillation (G$^{2}$D), a knowledge distillation framework that optimizes the multimodal model with a custom-built loss function that fuses both unimodal and multimodal objectives. G$^{2}$D further incorporates a dynamic sequential modality prioritization (SMP) technique in the learning process to ensure each modality leads the learning process, avoiding the pitfall of stronger modalities overshadowing weaker ones. We validate G$^{2}$D on multiple real-world datasets and show that G$^{2}$D amplifies the significance of weak modalities while training and outperforms state-of-the-art methods in classification and regression tasks. Our code is available at https://github.com/rAIson-Lab/G2D.
MIS-ME: A Multi-modal Framework for Soil Moisture Estimation
Aug 02, 2024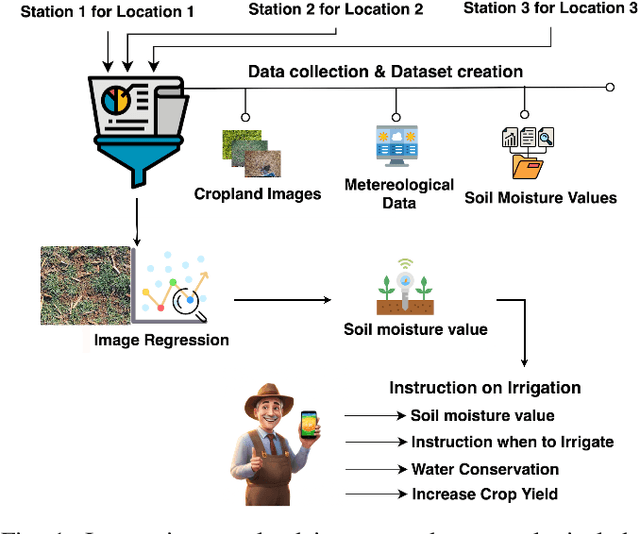
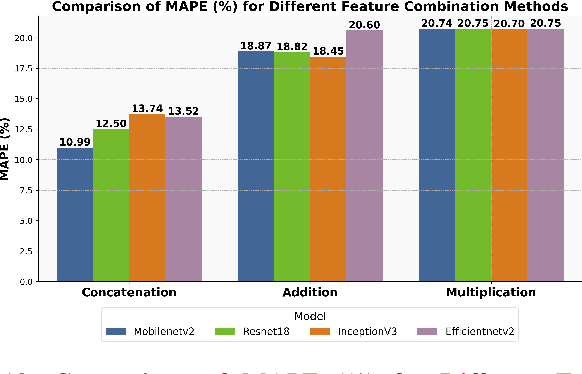
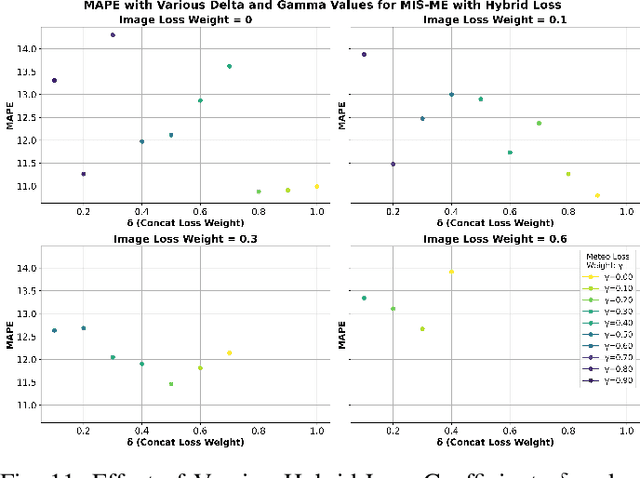
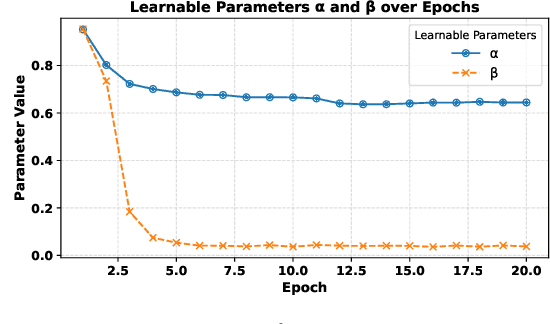
Soil moisture estimation is an important task to enable precision agriculture in creating optimal plans for irrigation, fertilization, and harvest. It is common to utilize statistical and machine learning models to estimate soil moisture from traditional data sources such as weather forecasts, soil properties, and crop properties. However, there is a growing interest in utilizing aerial and geospatial imagery to estimate soil moisture. Although these images capture high-resolution crop details, they are expensive to curate and challenging to interpret. Imagine, an AI-enhanced software tool that predicts soil moisture using visual cues captured by smartphones and statistical data given by weather forecasts. This work is a first step towards that goal of developing a multi-modal approach for soil moisture estimation. In particular, we curate a dataset consisting of real-world images taken from ground stations and their corresponding weather data. We also propose MIS-ME - Meteorological & Image based Soil Moisture Estimator, a multi-modal framework for soil moisture estimation. Our extensive analysis shows that MIS-ME achieves a MAPE of 10.79%, outperforming traditional unimodal approaches with a reduction of 2.6% in MAPE for meteorological data and 1.5% in MAPE for image data, highlighting the effectiveness of tailored multi-modal approaches.
Exploiting Adaptive Contextual Masking for Aspect-Based Sentiment Analysis
Feb 21, 2024



Aspect-Based Sentiment Analysis (ABSA) is a fine-grained linguistics problem that entails the extraction of multifaceted aspects, opinions, and sentiments from the given text. Both standalone and compound ABSA tasks have been extensively used in the literature to examine the nuanced information present in online reviews and social media posts. Current ABSA methods often rely on static hyperparameters for attention-masking mechanisms, which can struggle with context adaptation and may overlook the unique relevance of words in varied situations. This leads to challenges in accurately analyzing complex sentences containing multiple aspects with differing sentiments. In this work, we present adaptive masking methods that remove irrelevant tokens based on context to assist in Aspect Term Extraction and Aspect Sentiment Classification subtasks of ABSA. We show with our experiments that the proposed methods outperform the baseline methods in terms of accuracy and F1 scores on four benchmark online review datasets. Further, we show that the proposed methods can be extended with multiple adaptations and demonstrate a qualitative analysis of the proposed approach using sample text for aspect term extraction.
COLT: Cyclic Overlapping Lottery Tickets for Faster Pruning of Convolutional Neural Networks
Dec 24, 2022



Pruning refers to the elimination of trivial weights from neural networks. The sub-networks within an overparameterized model produced after pruning are often called Lottery tickets. This research aims to generate winning lottery tickets from a set of lottery tickets that can achieve similar accuracy to the original unpruned network. We introduce a novel winning ticket called Cyclic Overlapping Lottery Ticket (COLT) by data splitting and cyclic retraining of the pruned network from scratch. We apply a cyclic pruning algorithm that keeps only the overlapping weights of different pruned models trained on different data segments. Our results demonstrate that COLT can achieve similar accuracies (obtained by the unpruned model) while maintaining high sparsities. We show that the accuracy of COLT is on par with the winning tickets of Lottery Ticket Hypothesis (LTH) and, at times, is better. Moreover, COLTs can be generated using fewer iterations than tickets generated by the popular Iterative Magnitude Pruning (IMP) method. In addition, we also notice COLTs generated on large datasets can be transferred to small ones without compromising performance, demonstrating its generalizing capability. We conduct all our experiments on Cifar-10, Cifar-100 & TinyImageNet datasets and report superior performance than the state-of-the-art methods.
Bangla-Wave: Improving Bangla Automatic Speech Recognition Utilizing N-gram Language Models
Sep 13, 2022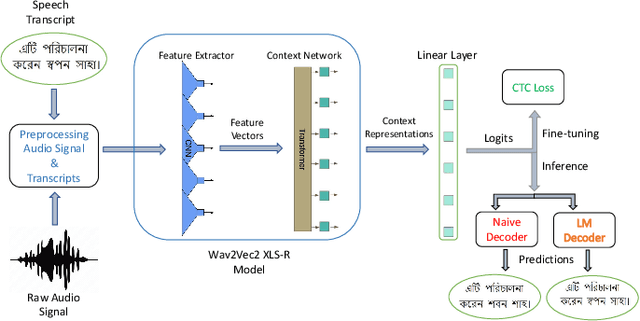
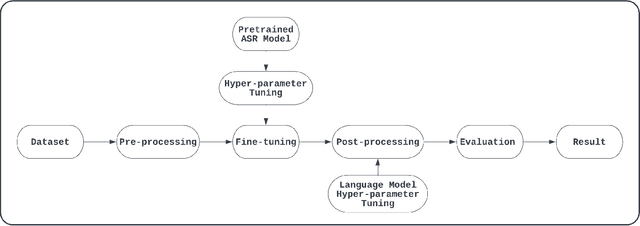
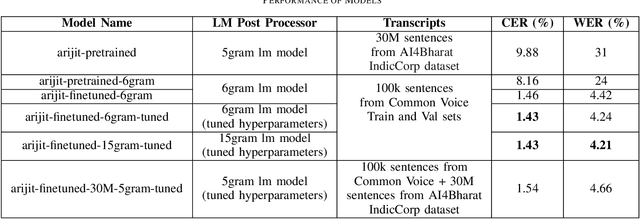
Although over 300M around the world speak Bangla, scant work has been done in improving Bangla voice-to-text transcription due to Bangla being a low-resource language. However, with the introduction of the Bengali Common Voice 9.0 speech dataset, Automatic Speech Recognition (ASR) models can now be significantly improved. With 399hrs of speech recordings, Bengali Common Voice is the largest and most diversified open-source Bengali speech corpus in the world. In this paper, we outperform the SOTA pretrained Bengali ASR models by finetuning a pretrained wav2vec2 model on the common voice dataset. We also demonstrate how to significantly improve the performance of an ASR model by adding an n-gram language model as a post-processor. Finally, we do some experiments and hyperparameter tuning to generate a robust Bangla ASR model that is better than the existing ASR models.
LILA-BOTI : Leveraging Isolated Letter Accumulations By Ordering Teacher Insights for Bangla Handwriting Recognition
May 23, 2022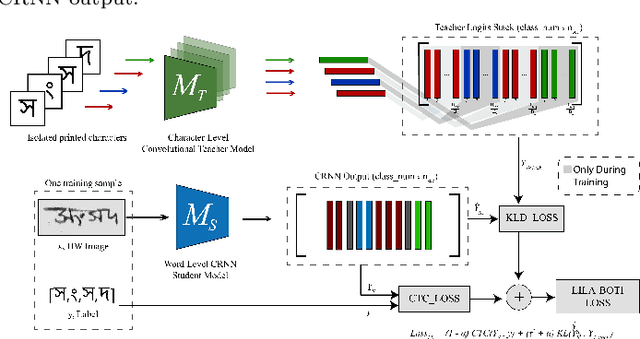
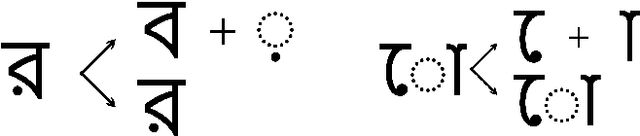
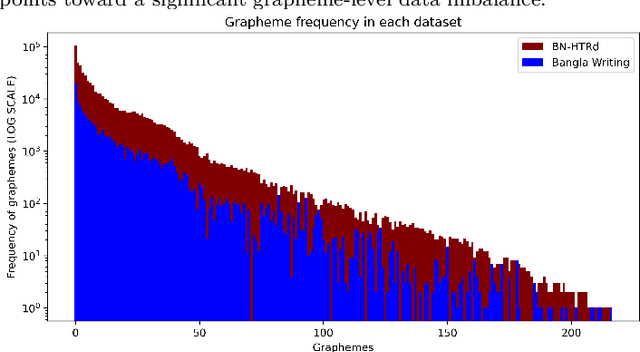
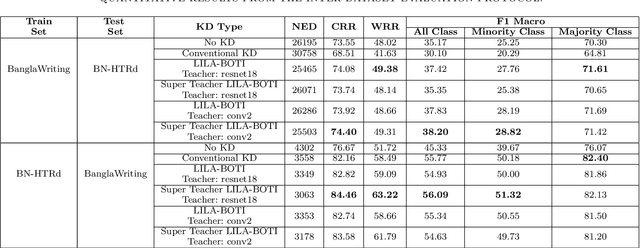
Word-level handwritten optical character recognition (OCR) remains a challenge for morphologically rich languages like Bangla. The complexity arises from the existence of a large number of alphabets, the presence of several diacritic forms, and the appearance of complex conjuncts. The difficulty is exacerbated by the fact that some graphemes occur infrequently but remain indispensable, so addressing the class imbalance is required for satisfactory results. This paper addresses this issue by introducing two knowledge distillation methods: Leveraging Isolated Letter Accumulations By Ordering Teacher Insights (LILA-BOTI) and Super Teacher LILA-BOTI. In both cases, a Convolutional Recurrent Neural Network (CRNN) student model is trained with the dark knowledge gained from a printed isolated character recognition teacher model. We conducted inter-dataset testing on \emph{BN-HTRd} and \emph{BanglaWriting} as our evaluation protocol, thus setting up a challenging problem where the results would better reflect the performance on unseen data. Our evaluations achieved up to a 3.5% increase in the F1-Macro score for the minor classes and up to 4.5% increase in our overall word recognition rate when compared with the base model (No KD) and conventional KD.