 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOLT: Cyclic Overlapping Lottery Tickets for Faster Pruning of Convolutional Neural Networks
Dec 24, 2022



Pruning refers to the elimination of trivial weights from neural networks. The sub-networks within an overparameterized model produced after pruning are often called Lottery tickets. This research aims to generate winning lottery tickets from a set of lottery tickets that can achieve similar accuracy to the original unpruned network. We introduce a novel winning ticket called Cyclic Overlapping Lottery Ticket (COLT) by data splitting and cyclic retraining of the pruned network from scratch. We apply a cyclic pruning algorithm that keeps only the overlapping weights of different pruned models trained on different data segments. Our results demonstrate that COLT can achieve similar accuracies (obtained by the unpruned model) while maintaining high sparsities. We show that the accuracy of COLT is on par with the winning tickets of Lottery Ticket Hypothesis (LTH) and, at times, is better. Moreover, COLTs can be generated using fewer iterations than tickets generated by the popular Iterative Magnitude Pruning (IMP) method. In addition, we also notice COLTs generated on large datasets can be transferred to small ones without compromising performance, demonstrating its generalizing capability. We conduct all our experiments on Cifar-10, Cifar-100 & TinyImageNet datasets and report superior performance than the state-of-the-art methods.
Dynamic Rectification Knowledge Distillation
Jan 27, 2022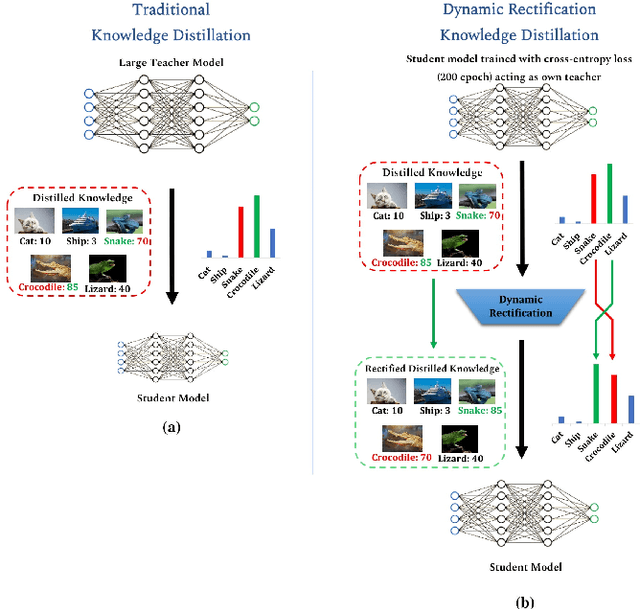



Knowledge Distillation is a technique which aims to utilize dark knowledge to compress and transfer information from a vast, well-trained neural network (teacher model) to a smaller, less capable neural network (student model) with improved inference efficiency. This approach of distilling knowledge has gained popularity as a result of the prohibitively complicated nature of such cumbersome models for deployment on edge computing devices. Generally, the teacher models used to teach smaller student models are cumbersome in nature and expensive to train. To eliminate the necessity for a cumbersome teacher model completely, we propose a simple yet effective knowledge distillation framework that we termed Dynamic Rectification Knowledge Distillation (DR-KD). Our method transforms the student into its own teacher, and if the self-teacher makes wrong predictions while distilling information, the error is rectified prior to the knowledge being distilled. Specifically, the teacher targets are dynamically tweaked by the agency of ground-truth while distilling the knowledge gained from traditional training. Our proposed DR-KD performs remarkably well in the absence of a sophisticated cumbersome teacher model and achieves comparable performance to existing state-of-the-art teacher-free knowledge distillation frameworks when implemented by a low-cost dynamic mannered teacher. Our approach is all-encompassing and can be utilized for any deep neural network training that requires categorization or object recognition. DR-KD enhances the test accuracy on Tiny ImageNet by 2.65% over prominent baseline models, which is significantly better than any other knowledge distillation approach while requiring no additional training costs.