 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG$^{2}$D: Boosting Multimodal Learning with Gradient-Guided Distillation
Jun 26, 2025Multimodal learning aims to leverage information from diverse data modalities to achieve more comprehensive performance. However, conventional multimodal models often suffer from modality imbalance, where one or a few modalities dominate model optimization, leading to suboptimal feature representation and underutilization of weak modalities. To address this challenge, we introduce Gradient-Guided Distillation (G$^{2}$D), a knowledge distillation framework that optimizes the multimodal model with a custom-built loss function that fuses both unimodal and multimodal objectives. G$^{2}$D further incorporates a dynamic sequential modality prioritization (SMP) technique in the learning process to ensure each modality leads the learning process, avoiding the pitfall of stronger modalities overshadowing weaker ones. We validate G$^{2}$D on multiple real-world datasets and show that G$^{2}$D amplifies the significance of weak modalities while training and outperforms state-of-the-art methods in classification and regression tasks. Our code is available at https://github.com/rAIson-Lab/G2D.
Exploiting Adaptive Contextual Masking for Aspect-Based Sentiment Analysis
Feb 21, 2024



Aspect-Based Sentiment Analysis (ABSA) is a fine-grained linguistics problem that entails the extraction of multifaceted aspects, opinions, and sentiments from the given text. Both standalone and compound ABSA tasks have been extensively used in the literature to examine the nuanced information present in online reviews and social media posts. Current ABSA methods often rely on static hyperparameters for attention-masking mechanisms, which can struggle with context adaptation and may overlook the unique relevance of words in varied situations. This leads to challenges in accurately analyzing complex sentences containing multiple aspects with differing sentiments. In this work, we present adaptive masking methods that remove irrelevant tokens based on context to assist in Aspect Term Extraction and Aspect Sentiment Classification subtasks of ABSA. We show with our experiments that the proposed methods outperform the baseline methods in terms of accuracy and F1 scores on four benchmark online review datasets. Further, we show that the proposed methods can be extended with multiple adaptations and demonstrate a qualitative analysis of the proposed approach using sample text for aspect term extraction.
HeTriNet: Heterogeneous Graph Triplet Attention Network for Drug-Target-Disease Interaction
Nov 30, 2023
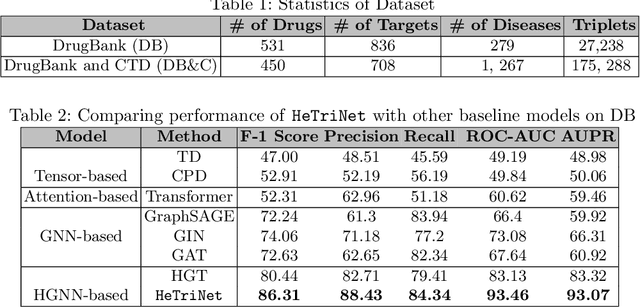
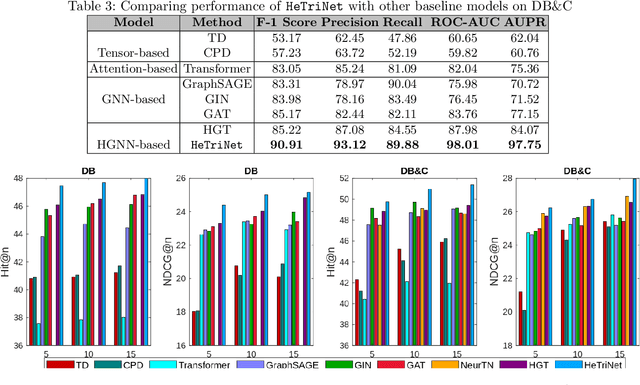

Modeling the interactions between drugs, targets, and diseases is paramount in drug discovery and has significant implications for precision medicine and personalized treatments. Current approaches frequently consider drug-target or drug-disease interactions individually, ignoring the interdependencies among all three entities. Within human metabolic systems, drugs interact with protein targets in cells, influencing target activities and subsequently impacting biological pathways to promote healthy functions and treat diseases. Moving beyond binary relationships and exploring tighter triple relationships is essential to understanding drugs' mechanism of action (MoAs). Moreover, identifying the heterogeneity of drugs, targets, and diseases, along with their distinct characteristics, is critical to model these complex interactions appropriately. To address these challenges, we effectively model the interconnectedness of all entities in a heterogeneous graph and develop a novel Heterogeneous Graph Triplet Attention Network (\texttt{HeTriNet}). \texttt{HeTriNet} introduces a novel triplet attention mechanism within this heterogeneous graph structure. Beyond pairwise attention as the importance of an entity for the other one, we define triplet attention to model the importance of pairs for entities in the drug-target-disease triplet prediction problem. Experimental results on real-world datasets show that \texttt{HeTriNet} outperforms several baselines, demonstrating its remarkable proficiency in uncovering novel drug-target-disease relationships.
Modeling Political Orientation of Social Media Posts: An Extended Analysis
Nov 21, 2023Developing machine learning models to characterize political polarization on online social media presents significant challenges. These challenges mainly stem from various factors such as the lack of annotated data, presence of noise in social media datasets, and the sheer volume of data. The common research practice typically examines the biased structure of online user communities for a given topic or qualitatively measuring the impacts of polarized topics on social media. However, there is limited work focusing on analyzing polarization at the ground-level, specifically in the social media posts themselves. Such existing analysis heavily relies on annotated data, which often requires laborious human labeling, offers labels only to specific problems, and lacks the ability to determine the near-future bias state of a social media conversations. Understanding the degree of political orientation conveyed in social media posts is crucial for quantifying the bias of online user communities and investigating the spread of polarized content. In this work, we first introduce two heuristic methods that leverage on news media bias and post content to label social media posts. Next, we compare the efficacy and quality of heuristically labeled dataset with a randomly sampled human-annotated dataset. Additionally, we demonstrate that current machine learning models can exhibit improved performance in predicting political orientation of social media posts, employing both traditional supervised learning and few-shot learning setups. We conduct experiments using the proposed heuristic methods and machine learning approaches to predict the political orientation of posts collected from two social media forums with diverse political ideologies: Gab and Twitter.
Quantitative Analysis of Forecasting Models:In the Aspect of Online Political Bias
Sep 19, 2023
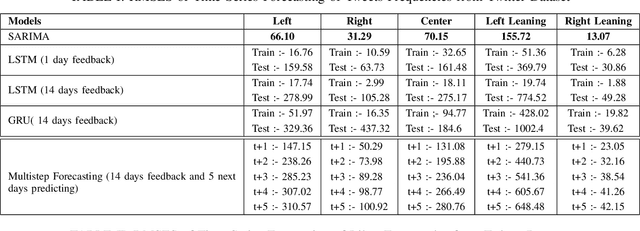
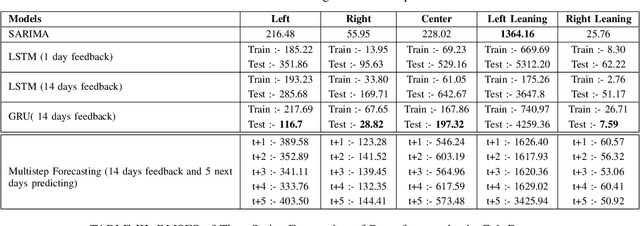
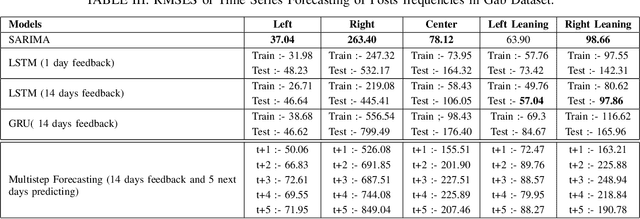
Understanding and mitigating political bias in online social media platforms are crucial tasks to combat misinformation and echo chamber effects. However, characterizing political bias temporally using computational methods presents challenges due to the high frequency of noise in social media datasets. While existing research has explored various approaches to political bias characterization, the ability to forecast political bias and anticipate how political conversations might evolve in the near future has not been extensively studied. In this paper, we propose a heuristic approach to classify social media posts into five distinct political leaning categories. Since there is a lack of prior work on forecasting political bias, we conduct an in-depth analysis of existing baseline models to identify which model best fits to forecast political leaning time series. Our approach involves utilizing existing time series forecasting models on two social media datasets with different political ideologies, specifically Twitter and Gab. Through our experiments and analyses, we seek to shed light on the challenges and opportunities in forecasting political bias in social media platforms. Ultimately, our work aims to pave the way for developing more effective strategies to mitigate the negative impact of political bias in the digital realm.
Learning Unbiased News Article Representations: A Knowledge-Infused Approach
Sep 12, 2023



Quantification of the political leaning of online news articles can aid in understanding the dynamics of political ideology in social groups and measures to mitigating them. However, predicting the accurate political leaning of a news article with machine learning models is a challenging task. This is due to (i) the political ideology of a news article is defined by several factors, and (ii) the innate nature of existing learning models to be biased with the political bias of the news publisher during the model training. There is only a limited number of methods to study the political leaning of news articles which also do not consider the algorithmic political bias which lowers the generalization of machine learning models to predict the political leaning of news articles published by any new news publishers. In this work, we propose a knowledge-infused deep learning model that utilizes relatively reliable external data resources to learn unbiased representations of news articles using their global and local contexts. We evaluate the proposed model by setting the data in such a way that news domains or news publishers in the test set are completely unseen during the training phase. With this setup we show that the proposed model mitigates algorithmic political bias and outperforms baseline methods to predict the political leaning of news articles with up to 73% accuracy.
Scalable Pathogen Detection from Next Generation DNA Sequencing with Deep Learning
Nov 30, 2022Next-generation sequencing technologies have enhanced the scope of Internet-of-Things (IoT) to include genomics for personalized medicine through the increased availability of an abundance of genome data collected from heterogeneous sources at a reduced cost. Given the sheer magnitude of the collected data and the significant challenges offered by the presence of highly similar genomic structure across species, there is a need for robust, scalable analysis platforms to extract actionable knowledge such as the presence of potentially zoonotic pathogens. The emergence of zoonotic diseases from novel pathogens, such as the influenza virus in 1918 and SARS-CoV-2 in 2019 that can jump species barriers and lead to pandemic underscores the need for scalable metagenome analysis. In this work, we propose MG2Vec, a deep learning-based solution that uses the transformer network as its backbone, to learn robust features from raw metagenome sequences for downstream biomedical tasks such as targeted and generalized pathogen detection. Extensive experiments on four increasingly challenging, yet realistic diagnostic settings, show that the proposed approach can help detect pathogens from uncurated, real-world clinical samples with minimal human supervision in the form of labels. Further, we demonstrate that the learned representations can generalize to completely unrelated pathogens across diseases and species for large-scale metagenome analysis. We provide a comprehensive evaluation of a novel representation learning framework for metagenome-based disease diagnostics with deep learning and provide a way forward for extracting and using robust vector representations from low-cost next generation sequencing to develop generalizable diagnostic tools.
Metagenome2Vec: Building Contextualized Representations for Scalable Metagenome Analysis
Nov 09, 2021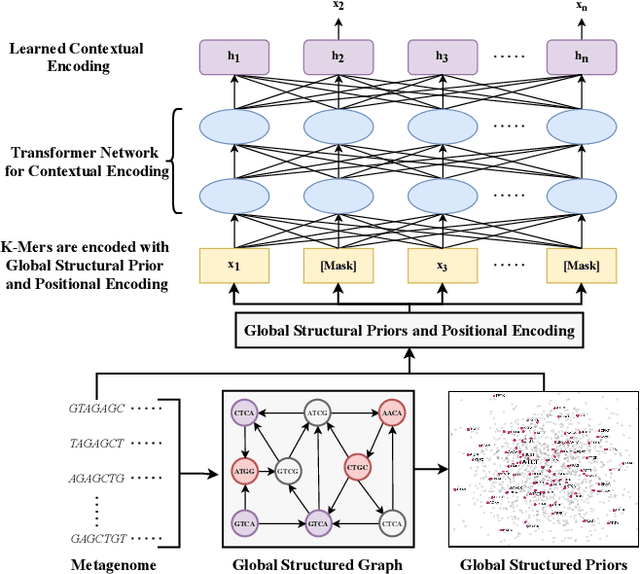
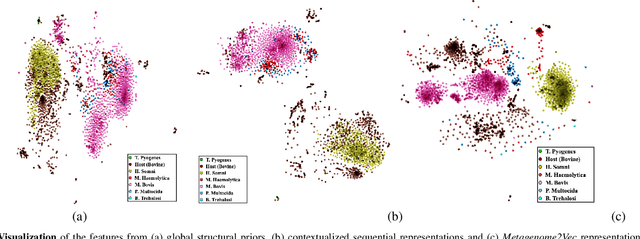
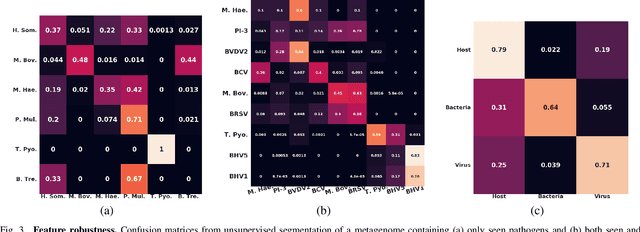
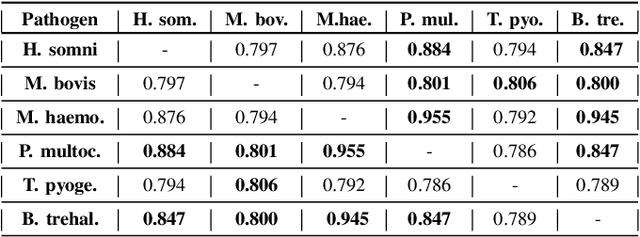
Advances in next-generation metagenome sequencing have the potential to revolutionize the point-of-care diagnosis of novel pathogen infections, which could help prevent potential widespread transmission of diseases. Given the high volume of metagenome sequences, there is a need for scalable frameworks to analyze and segment metagenome sequences from clinical samples, which can be highly imbalanced. There is an increased need for learning robust representations from metagenome reads since pathogens within a family can have highly similar genome structures (some more than 90%) and hence enable the segmentation and identification of novel pathogen sequences with limited labeled data. In this work, we propose Metagenome2Vec - a contextualized representation that captures the global structural properties inherent in metagenome data and local contextualized properties through self-supervised representation learning. We show that the learned representations can help detect six (6) related pathogens from clinical samples with less than 100 labeled sequences. Extensive experiments on simulated and clinical metagenome data show that the proposed representation encodes compositional properties that can generalize beyond annotations to segment novel pathogens in an unsupervised setting.
A Machine Learning Pipeline to Examine Political Bias with Congressional Speeches
Sep 18, 2021
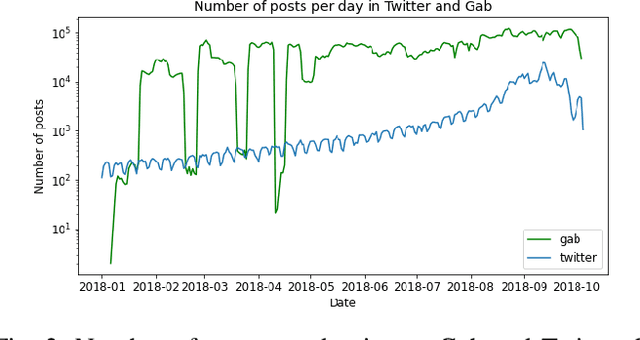
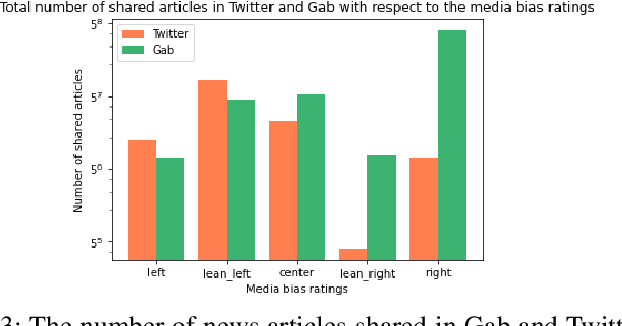
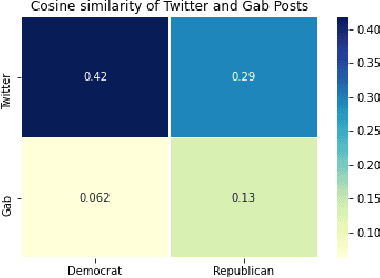
Computational methods to model political bias in social media involve several challenges due to heterogeneity, high-dimensional, multiple modalities, and the scale of the data. Political bias in social media has been studied in multiple viewpoints like media bias, political ideology, echo chambers, and controversies using machine learning pipelines. Most of the current methods rely heavily on the manually-labeled ground-truth data for the underlying political bias prediction tasks. Limitations of such methods include human-intensive labeling, labels related to only a specific problem, and the inability to determine the near future bias state of a social media conversation. In this work, we address such problems and give machine learning approaches to study political bias in two ideologically diverse social media forums: Gab and Twitter without the availability of human-annotated data. Our proposed methods exploit the use of transcripts collected from political speeches in US congress to label the data and achieve the highest accuracy of 70.5% and 65.1% in Twitter and Gab data respectively to predict political bias. We also present a machine learning approach that combines features from cascades and text to forecast cascade's political bias with an accuracy of about 85%.
MG-NET: Leveraging Pseudo-Imaging for Multi-Modal Metagenome Analysis
Jul 21, 2021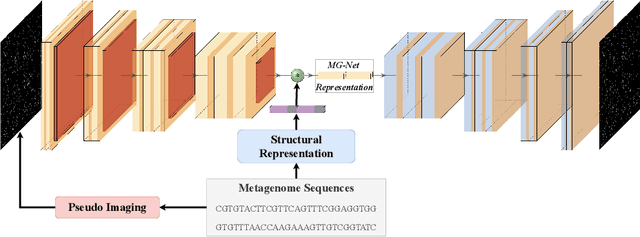
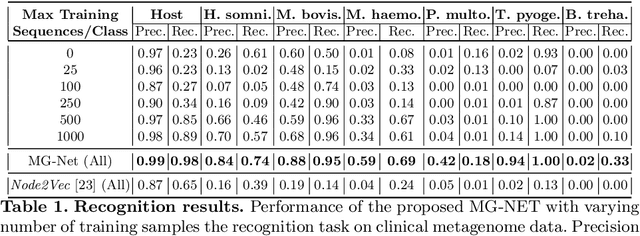
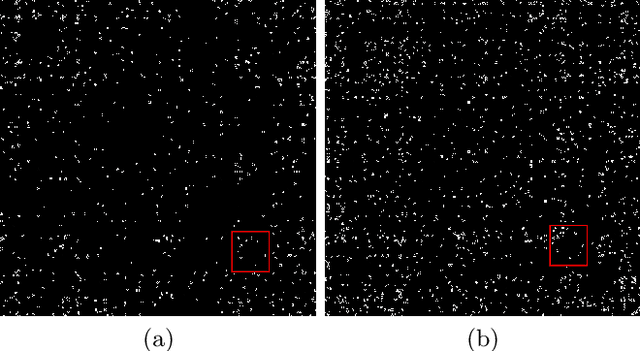
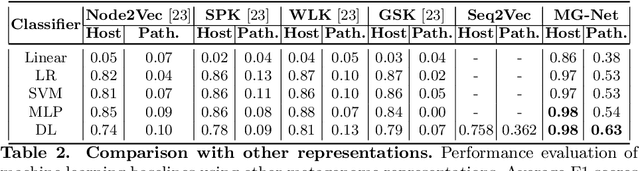
The emergence of novel pathogens and zoonotic diseases like the SARS-CoV-2 have underlined the need for developing novel diagnosis and intervention pipelines that can learn rapidly from small amounts of labeled data. Combined with technological advances in next-generation sequencing, metagenome-based diagnostic tools hold much promise to revolutionize rapid point-of-care diagnosis. However, there are significant challenges in developing such an approach, the chief among which is to learn self-supervised representations that can help detect novel pathogen signatures with very low amounts of labeled data. This is particularly a difficult task given that closely related pathogens can share more than 90% of their genome structure. In this work, we address these challenges by proposing MG-Net, a self-supervised representation learning framework that leverages multi-modal context using pseudo-imaging data derived from clinical metagenome sequences. We show that the proposed framework can learn robust representations from unlabeled data that can be used for downstream tasks such as metagenome sequence classification with limited access to labeled data. Extensive experiments show that the learned features outperform current baseline metagenome representations, given only 1000 samples per class.