 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-attentive Cohesive Subgraph Embedding to Mitigate Oversquashing in GNNs
Apr 02, 2026Graph neural networks (GNNs) have achieved strong performance across various real-world domains. Nevertheless, they suffer from oversquashing, where long-range information is distorted as it is compressed through limited message-passing pathways. This bottleneck limits their ability to capture essential global context and decreases their performance, particularly in dense and heterophilic regions of graphs. To address this issue, we propose a novel graph learning framework that enriches node embeddings via cross-attentive cohesive subgraph representations to mitigate the impact of excessive long-range dependencies. This framework enhances the node representation by emphasizing cohesive structure in long-range information but removing noisy or irrelevant connections. It preserves essential global context without overloading the narrow bottlenecked channels, which further mitigates oversquashing. Extensive experiments on multiple benchmark datasets demonstrate that our model achieves consistent improvements in classification accuracy over standard baseline methods.
HyperGCL: Multi-Modal Graph Contrastive Learning via Learnable Hypergraph Views
Feb 18, 2025Recent advancements in Graph Contrastive Learning (GCL) have demonstrated remarkable effectiveness in improving graph representations. However, relying on predefined augmentations (e.g., node dropping, edge perturbation, attribute masking) may result in the loss of task-relevant information and a lack of adaptability to diverse input data. Furthermore, the selection of negative samples remains rarely explored. In this paper, we introduce HyperGCL, a novel multimodal GCL framework from a hypergraph perspective. HyperGCL constructs three distinct hypergraph views by jointly utilizing the input graph's structure and attributes, enabling a comprehensive integration of multiple modalities in contrastive learning. A learnable adaptive topology augmentation technique enhances these views by preserving important relations and filtering out noise. View-specific encoders capture essential characteristics from each view, while a network-aware contrastive loss leverages the underlying topology to define positive and negative samples effectively. Extensive experiments on benchmark datasets demonstrate that HyperGCL achieves state-of-the-art node classification performance.
Tackling Oversmoothing in GNN via Graph Sparsification: A Truss-based Approach
Jul 16, 2024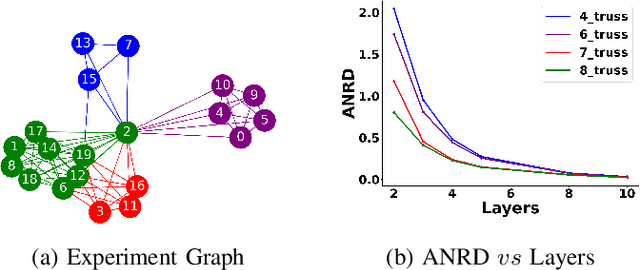
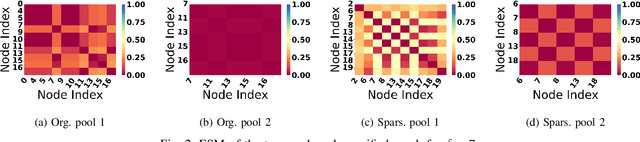
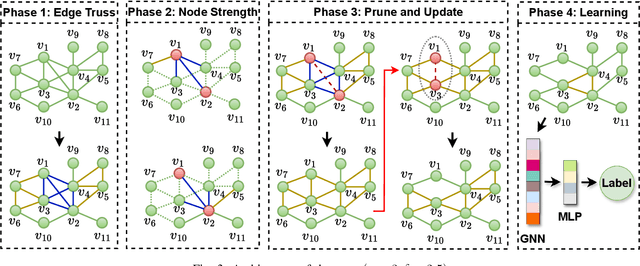
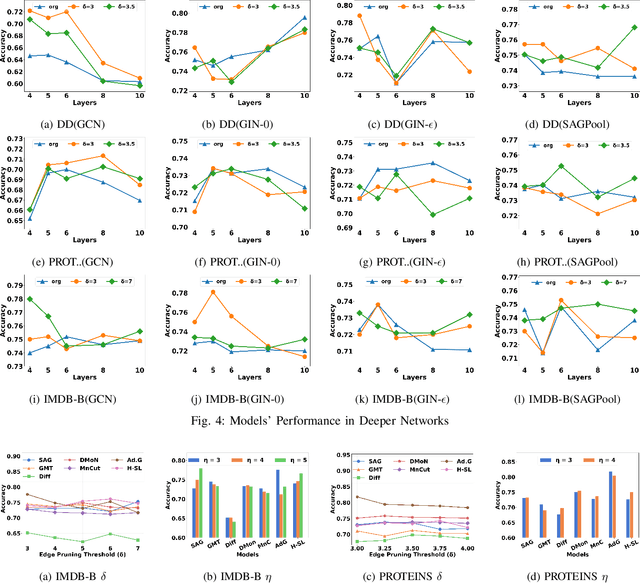
Graph Neural Network (GNN) achieves great success for node-level and graph-level tasks via encoding meaningful topological structures of networks in various domains, ranging from social to biological networks. However, repeated aggregation operations lead to excessive mixing of node representations, particularly in dense regions with multiple GNN layers, resulting in nearly indistinguishable embeddings. This phenomenon leads to the oversmoothing problem that hampers downstream graph analytics tasks. To overcome this issue, we propose a novel and flexible truss-based graph sparsification model that prunes edges from dense regions of the graph. Pruning redundant edges in dense regions helps to prevent the aggregation of excessive neighborhood information during hierarchical message passing and pooling in GNN models. We then utilize our sparsification model in the state-of-the-art baseline GNNs and pooling models, such as GIN, SAGPool, GMT, DiffPool, MinCutPool, HGP-SL, DMonPool, and AdamGNN. Extensive experiments on different real-world datasets show that our model significantly improves the performance of the baseline GNN models in the graph classification task.
HeTriNet: Heterogeneous Graph Triplet Attention Network for Drug-Target-Disease Interaction
Nov 30, 2023
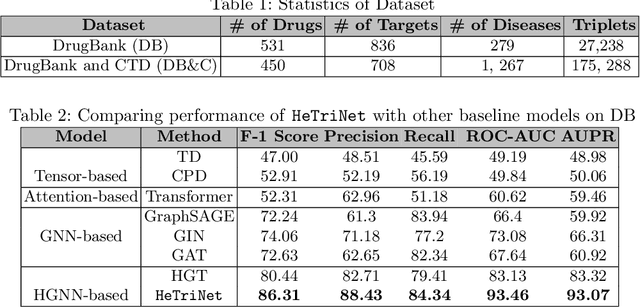
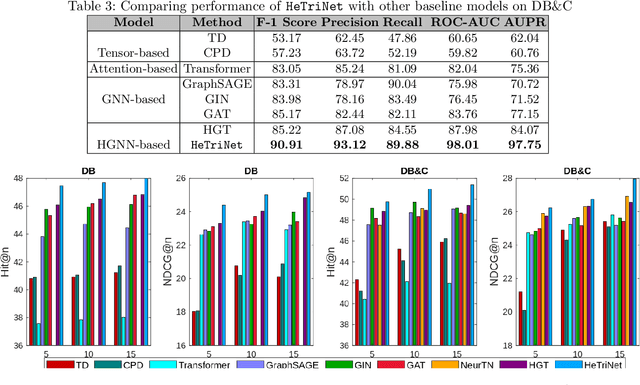

Modeling the interactions between drugs, targets, and diseases is paramount in drug discovery and has significant implications for precision medicine and personalized treatments. Current approaches frequently consider drug-target or drug-disease interactions individually, ignoring the interdependencies among all three entities. Within human metabolic systems, drugs interact with protein targets in cells, influencing target activities and subsequently impacting biological pathways to promote healthy functions and treat diseases. Moving beyond binary relationships and exploring tighter triple relationships is essential to understanding drugs' mechanism of action (MoAs). Moreover, identifying the heterogeneity of drugs, targets, and diseases, along with their distinct characteristics, is critical to model these complex interactions appropriately. To address these challenges, we effectively model the interconnectedness of all entities in a heterogeneous graph and develop a novel Heterogeneous Graph Triplet Attention Network (\texttt{HeTriNet}). \texttt{HeTriNet} introduces a novel triplet attention mechanism within this heterogeneous graph structure. Beyond pairwise attention as the importance of an entity for the other one, we define triplet attention to model the importance of pairs for entities in the drug-target-disease triplet prediction problem. Experimental results on real-world datasets show that \texttt{HeTriNet} outperforms several baselines, demonstrating its remarkable proficiency in uncovering novel drug-target-disease relationships.
Brain Networks and Intelligence: A Graph Neural Network Based Approach to Resting State fMRI Data
Nov 06, 2023Resting-state functional magnetic resonance imaging (rsfMRI) is a powerful tool for investigating the relationship between brain function and cognitive processes as it allows for the functional organization of the brain to be captured without relying on a specific task or stimuli. In this paper, we present a novel modeling architecture called BrainRGIN for predicting intelligence (fluid, crystallized, and total intelligence) using graph neural networks on rsfMRI derived static functional network connectivity matrices. Extending from the existing graph convolution networks, our approach incorporates a clustering-based embedding and graph isomorphism network in the graph convolutional layer to reflect the nature of the brain sub-network organization and efficient network expression, in combination with TopK pooling and attention-based readout functions. We evaluated our proposed architecture on a large dataset, specifically the Adolescent Brain Cognitive Development Dataset, and demonstrated its effectiveness in predicting individual differences in intelligence. Our model achieved lower mean squared errors and higher correlation scores than existing relevant graph architectures and other traditional machine learning models for all of the intelligence prediction tasks. The middle frontal gyrus exhibited a significant contribution to both fluid and crystallized intelligence, suggesting their pivotal role in these cognitive processes. Total composite scores identified a diverse set of brain regions to be relevant which underscores the complex nature of total intelligence.
Topology-guided Hypergraph Transformer Network: Unveiling Structural Insights for Improved Representation
Oct 14, 2023
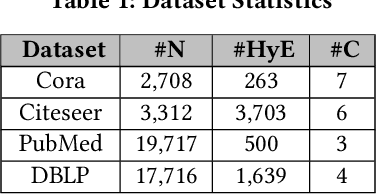

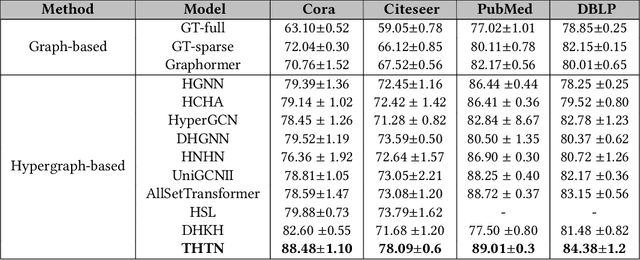
Hypergraphs, with their capacity to depict high-order relationships, have emerged as a significant extension of traditional graphs. Although Graph Neural Networks (GNNs) have remarkable performance in graph representation learning, their extension to hypergraphs encounters challenges due to their intricate structures. Furthermore, current hypergraph transformers, a special variant of GNN, utilize semantic feature-based self-attention, ignoring topological attributes of nodes and hyperedges. To address these challenges, we propose a Topology-guided Hypergraph Transformer Network (THTN). In this model, we first formulate a hypergraph from a graph while retaining its structural essence to learn higher-order relations within the graph. Then, we design a simple yet effective structural and spatial encoding module to incorporate the topological and spatial information of the nodes into their representation. Further, we present a structure-aware self-attention mechanism that discovers the important nodes and hyperedges from both semantic and structural viewpoints. By leveraging these two modules, THTN crafts an improved node representation, capturing both local and global topological expressions. Extensive experiments conducted on node classification tasks demonstrate that the performance of the proposed model consistently exceeds that of the existing approaches.
Seq-HyGAN: Sequence Classification via Hypergraph Attention Network
Mar 19, 2023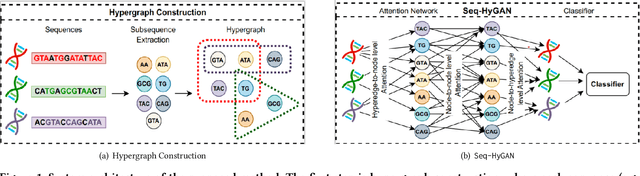
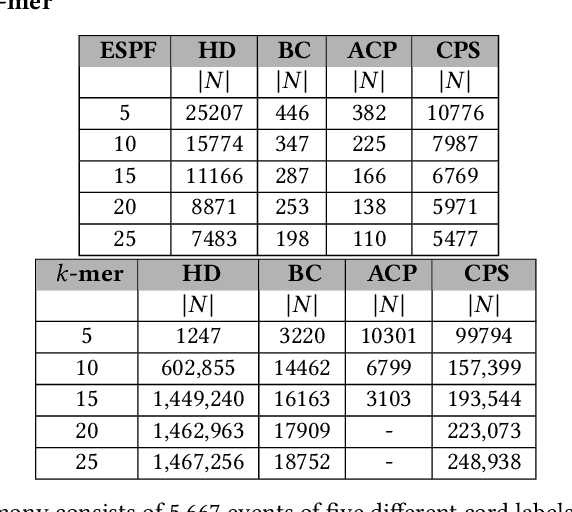
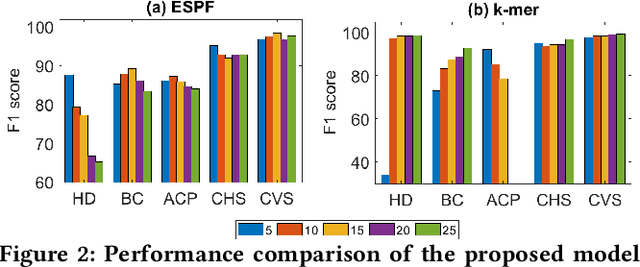
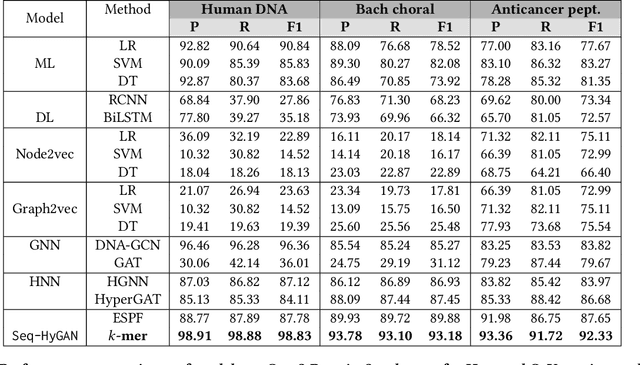
Sequence classification has a wide range of real-world applications in different domains, such as genome classification in health and anomaly detection in business. However, the lack of explicit features in sequence data makes it difficult for machine learning models. While Neural Network (NN) models address this with learning features automatically, they are limited to capturing adjacent structural connections and ignore global, higher-order information between the sequences. To address these challenges in the sequence classification problems, we propose a novel Hypergraph Attention Network model, namely Seq-HyGAN. To capture the complex structural similarity between sequence data, we first create a hypergraph where the sequences are depicted as hyperedges and subsequences extracted from sequences are depicted as nodes. Additionally, we introduce an attention-based Hypergraph Neural Network model that utilizes a two-level attention mechanism. This model generates a sequence representation as a hyperedge while simultaneously learning the crucial subsequences for each sequence. We conduct extensive experiments on four data sets to assess and compare our model with several state-of-the-art methods. Experimental results demonstrate that our proposed Seq-HyGAN model can effectively classify sequence data and significantly outperform the baselines. We also conduct case studies to investigate the contribution of each module in Seq-HyGAN.
MPool: Motif-Based Graph Pooling
Mar 07, 2023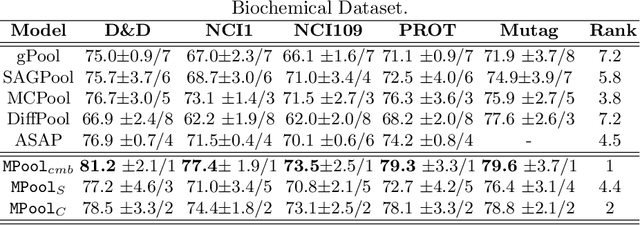


Graph Neural networks (GNNs) have recently become a powerful technique for many graph-related tasks including graph classification. Current GNN models apply different graph pooling methods that reduce the number of nodes and edges to learn the higher-order structure of the graph in a hierarchical way. All these methods primarily rely on the one-hop neighborhood. However, they do not consider the higher- order structure of the graph. In this work, we propose a multi-channel Motif-based Graph Pooling method named (MPool) captures the higher-order graph structure with motif and local and global graph structure with a combination of selection and clustering-based pooling operations. As the first channel, we develop node selection-based graph pooling by designing a node ranking model considering the motif adjacency of nodes. As the second channel, we develop cluster-based graph pooling by designing a spectral clustering model using motif adjacency. As the final layer, the result of each channel is aggregated into the final graph representation. We perform extensive experiments on eight benchmark datasets and show that our proposed method shows better accuracy than the baseline methods for graph classification tasks.
DDI Prediction via Heterogeneous Graph Attention Networks
Jul 12, 2022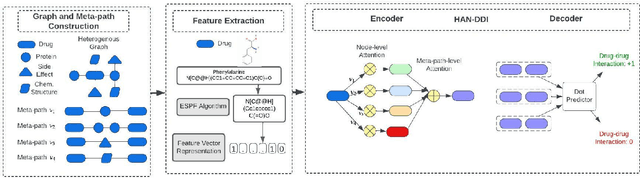


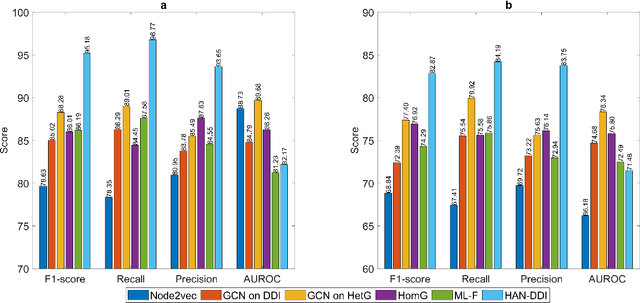
Polypharmacy, defined as the use of multiple drugs together, is a standard treatment method, especially for severe and chronic diseases. However, using multiple drugs together may cause interactions between drugs. Drug-drug interaction (DDI) is the activity that occurs when the impact of one drug changes when combined with another. DDIs may obstruct, increase, or decrease the intended effect of either drug or, in the worst-case scenario, create adverse side effects. While it is critical to detect DDIs on time, it is timeconsuming and expensive to identify them in clinical trials due to their short duration and many possible drug pairs to be considered for testing. As a result, computational methods are needed for predicting DDIs. In this paper, we present a novel heterogeneous graph attention model, HAN-DDI to predict drug-drug interactions. We create a heterogeneous network of drugs with different biological entities. Then, we develop a heterogeneous graph attention network to learn DDIs using relations of drugs with other entities. It consists of an attention-based heterogeneous graph node encoder for obtaining drug node representations and a decoder for predicting drug-drug interactions. Further, we utilize comprehensive experiments to evaluate of our model and to compare it with state-of-the-art models. Experimental results show that our proposed method, HAN-DDI, outperforms the baselines significantly and accurately predicts DDIs, even for new drugs.
HyGNN: Drug-Drug Interaction Prediction via Hypergraph Neural Network
Jun 25, 2022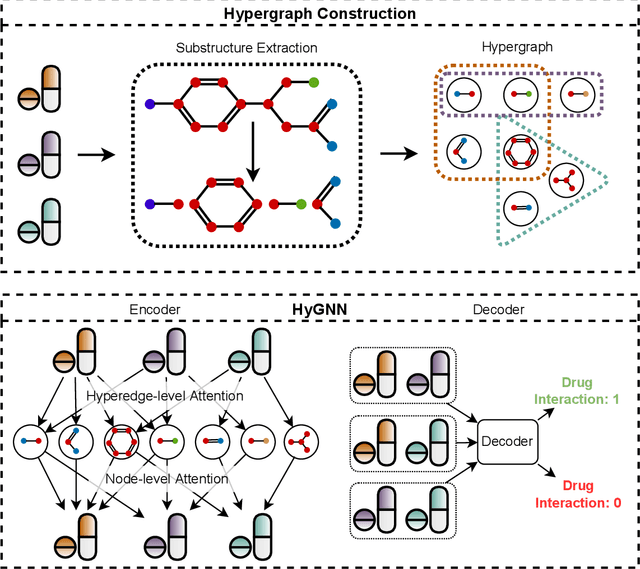
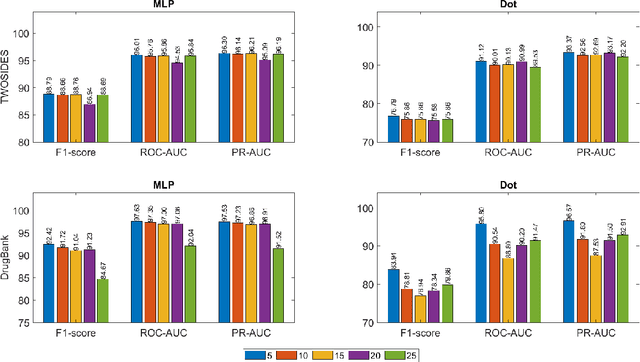
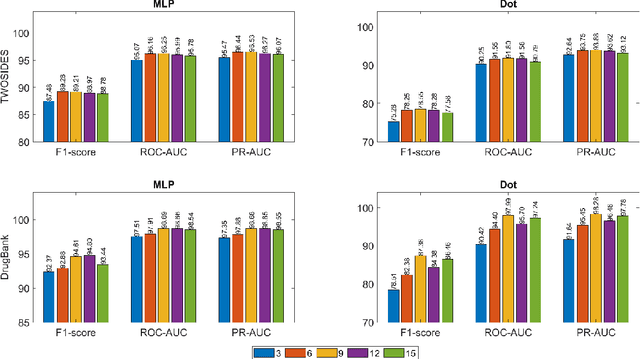
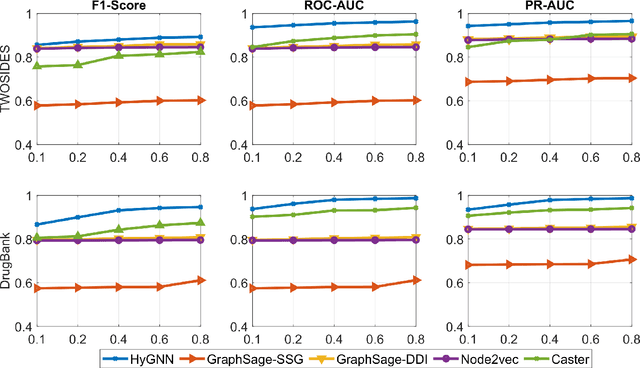
Drug-Drug Interactions (DDIs) may hamper the functionalities of drugs, and in the worst scenario, they may lead to adverse drug reactions (ADRs). Predicting all DDIs is a challenging and critical problem. Most existing computational models integrate drug-centric information from different sources and leverage them as features in machine learning classifiers to predict DDIs. However, these models have a high chance of failure, especially for the new drugs when all the information is not available. This paper proposes a novel Hypergraph Neural Network (HyGNN) model based on only the SMILES string of drugs, available for any drug, for the DDI prediction problem. To capture the drug similarities, we create a hypergraph from drugs' chemical substructures extracted from the SMILES strings. Then, we develop HyGNN consisting of a novel attention-based hypergraph edge encoder to get the representation of drugs as hyperedges and a decoder to predict the interactions between drug pairs. Furthermore, we conduct extensive experiments to evaluate our model and compare it with several state-of-the-art methods. Experimental results demonstrate that our proposed HyGNN model effectively predicts DDIs and impressively outperforms the baselines with a maximum ROC-AUC and PR-AUC of 97.9% and 98.1%, respectively.