 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopological Conditioning for Mammography Models via a Stable Wavelet-Persistence Vectorization
Dec 10, 2025Breast cancer is the most commonly diagnosed cancer in women and a leading cause of cancer death worldwide. Screening mammography reduces mortality, yet interpretation still suffers from substantial false negatives and false positives, and model accuracy often degrades when deployed across scanners, modalities, and patient populations. We propose a simple conditioning signal aimed at improving external performance based on a wavelet based vectorization of persistent homology. Using topological data analysis, we summarize image structure that persists across intensity thresholds and convert this information into spatial, multi scale maps that are provably stable to small intensity perturbations. These maps are integrated into a two stage detection pipeline through input level channel concatenation. The model is trained and validated on the CBIS DDSM digitized film mammography cohort from the United States and evaluated on two independent full field digital mammography cohorts from Portugal (INbreast) and China (CMMD), with performance reported at the patient level. On INbreast, augmenting ConvNeXt Tiny with wavelet persistence channels increases patient level AUC from 0.55 to 0.75 under a limited training budget.
Playing Devil's Advocate: Unmasking Toxicity and Vulnerabilities in Large Vision-Language Models
Jan 14, 2025



The rapid advancement of Large Vision-Language Models (LVLMs) has enhanced capabilities offering potential applications from content creation to productivity enhancement. Despite their innovative potential, LVLMs exhibit vulnerabilities, especially in generating potentially toxic or unsafe responses. Malicious actors can exploit these vulnerabilities to propagate toxic content in an automated (or semi-) manner, leveraging the susceptibility of LVLMs to deception via strategically crafted prompts without fine-tuning or compute-intensive procedures. Despite the red-teaming efforts and inherent potential risks associated with the LVLMs, exploring vulnerabilities of LVLMs remains nascent and yet to be fully addressed in a systematic manner. This study systematically examines the vulnerabilities of open-source LVLMs, including LLaVA, InstructBLIP, Fuyu, and Qwen, using adversarial prompt strategies that simulate real-world social manipulation tactics informed by social theories. Our findings show that (i) toxicity and insulting are the most prevalent behaviors, with the mean rates of 16.13% and 9.75%, respectively; (ii) Qwen-VL-Chat, LLaVA-v1.6-Vicuna-7b, and InstructBLIP-Vicuna-7b are the most vulnerable models, exhibiting toxic response rates of 21.50%, 18.30% and 17.90%, and insulting responses of 13.40%, 11.70% and 10.10%, respectively; (iii) prompting strategies incorporating dark humor and multimodal toxic prompt completion significantly elevated these vulnerabilities. Despite being fine-tuned for safety, these models still generate content with varying degrees of toxicity when prompted with adversarial inputs, highlighting the urgent need for enhanced safety mechanisms and robust guardrails in LVLM development.
Topology-guided Hypergraph Transformer Network: Unveiling Structural Insights for Improved Representation
Oct 14, 2023

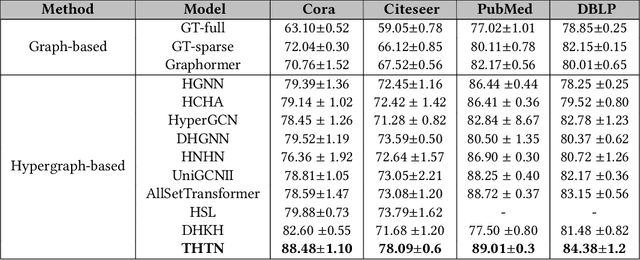
Hypergraphs, with their capacity to depict high-order relationships, have emerged as a significant extension of traditional graphs. Although Graph Neural Networks (GNNs) have remarkable performance in graph representation learning, their extension to hypergraphs encounters challenges due to their intricate structures. Furthermore, current hypergraph transformers, a special variant of GNN, utilize semantic feature-based self-attention, ignoring topological attributes of nodes and hyperedges. To address these challenges, we propose a Topology-guided Hypergraph Transformer Network (THTN). In this model, we first formulate a hypergraph from a graph while retaining its structural essence to learn higher-order relations within the graph. Then, we design a simple yet effective structural and spatial encoding module to incorporate the topological and spatial information of the nodes into their representation. Further, we present a structure-aware self-attention mechanism that discovers the important nodes and hyperedges from both semantic and structural viewpoints. By leveraging these two modules, THTN crafts an improved node representation, capturing both local and global topological expressions. Extensive experiments conducted on node classification tasks demonstrate that the performance of the proposed model consistently exceeds that of the existing approaches.