 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Machine Learning Pipeline to Examine Political Bias with Congressional Speeches
Sep 18, 2021
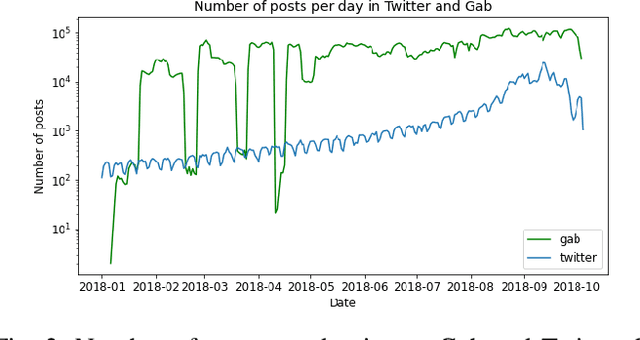
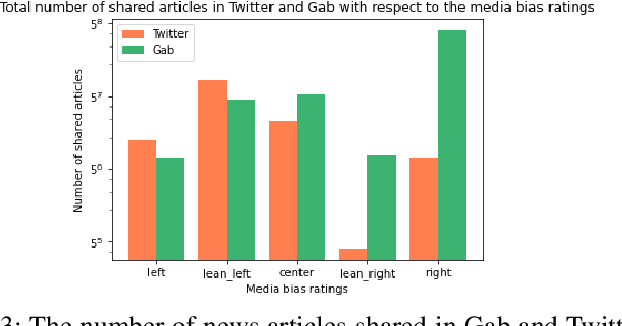
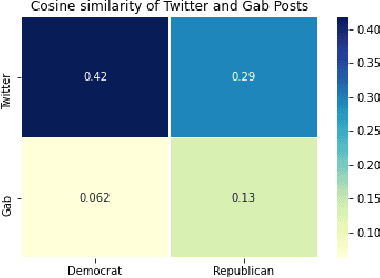
Computational methods to model political bias in social media involve several challenges due to heterogeneity, high-dimensional, multiple modalities, and the scale of the data. Political bias in social media has been studied in multiple viewpoints like media bias, political ideology, echo chambers, and controversies using machine learning pipelines. Most of the current methods rely heavily on the manually-labeled ground-truth data for the underlying political bias prediction tasks. Limitations of such methods include human-intensive labeling, labels related to only a specific problem, and the inability to determine the near future bias state of a social media conversation. In this work, we address such problems and give machine learning approaches to study political bias in two ideologically diverse social media forums: Gab and Twitter without the availability of human-annotated data. Our proposed methods exploit the use of transcripts collected from political speeches in US congress to label the data and achieve the highest accuracy of 70.5% and 65.1% in Twitter and Gab data respectively to predict political bias. We also present a machine learning approach that combines features from cascades and text to forecast cascade's political bias with an accuracy of about 85%.