 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBangla-Wave: Improving Bangla Automatic Speech Recognition Utilizing N-gram Language Models
Paper and Code
Sep 13, 2022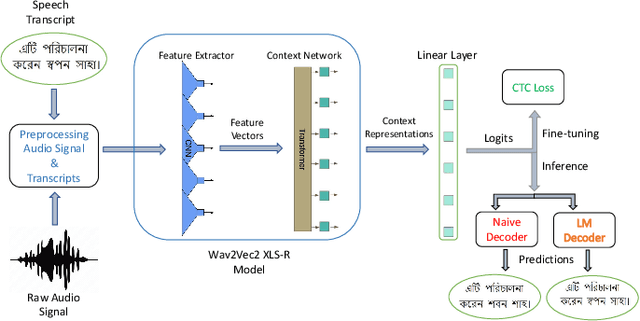
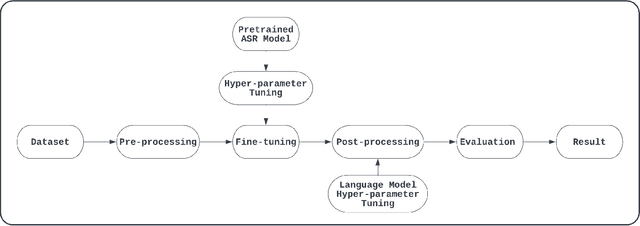
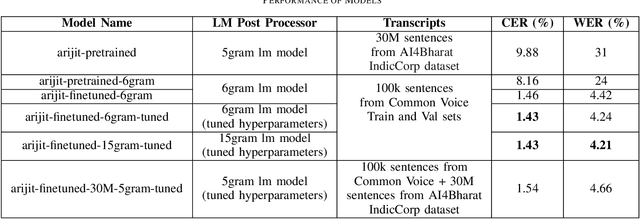
Although over 300M around the world speak Bangla, scant work has been done in improving Bangla voice-to-text transcription due to Bangla being a low-resource language. However, with the introduction of the Bengali Common Voice 9.0 speech dataset, Automatic Speech Recognition (ASR) models can now be significantly improved. With 399hrs of speech recordings, Bengali Common Voice is the largest and most diversified open-source Bengali speech corpus in the world. In this paper, we outperform the SOTA pretrained Bengali ASR models by finetuning a pretrained wav2vec2 model on the common voice dataset. We also demonstrate how to significantly improve the performance of an ASR model by adding an n-gram language model as a post-processor. Finally, we do some experiments and hyperparameter tuning to generate a robust Bangla ASR model that is better than the existing ASR models.