 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Temperature Scheduler for Knowledge Distillation
Nov 14, 2025Knowledge Distillation (KD) trains a smaller student model using a large, pre-trained teacher model, with temperature as a key hyperparameter controlling the softness of output probabilities. Traditional methods use a fixed temperature throughout training, which is suboptimal. Moreover, architectural differences between teacher and student often result in mismatched logit magnitudes. We demonstrate that students benefit from softer probabilities early in training but require sharper probabilities in later stages. We introduce Dynamic Temperature Scheduler (DTS), which adjusts temperature dynamically based on the cross-entropy loss gap between teacher and student. To our knowledge, this is the first temperature scheduling method that adapts based on the divergence between teacher and student distributions. Our method integrates seamlessly with existing KD frameworks. We validate DTS across multiple KD strategies on vision (CIFAR-100, Tiny-ImageNet) and NLP tasks (GLUE, Dolly, SelfIns, UnNI, S-NI), consistently outperforming static-temperature baselines. Code is available at https://github.com/Sibgat-Ul/DTS.
LegalRAG: A Hybrid RAG System for Multilingual Legal Information Retrieval
Apr 19, 2025Natural Language Processing (NLP) and computational linguistic techniques are increasingly being applied across various domains, yet their use in legal and regulatory tasks remains limited. To address this gap, we develop an efficient bilingual question-answering framework for regulatory documents, specifically the Bangladesh Police Gazettes, which contain both English and Bangla text. Our approach employs modern Retrieval Augmented Generation (RAG) pipelines to enhance information retrieval and response generation. In addition to conventional RAG pipelines, we propose an advanced RAG-based approach that improves retrieval performance, leading to more precise answers. This system enables efficient searching for specific government legal notices, making legal information more accessible. We evaluate both our proposed and conventional RAG systems on a diverse test set on Bangladesh Police Gazettes, demonstrating that our approach consistently outperforms existing methods across all evaluation metrics.
Empowering Meta-Analysis: Leveraging Large Language Models for Scientific Synthesis
Nov 16, 2024This study investigates the automation of meta-analysis in scientific documents using large language models (LLMs). Meta-analysis is a robust statistical method that synthesizes the findings of multiple studies support articles to provide a comprehensive understanding. We know that a meta-article provides a structured analysis of several articles. However, conducting meta-analysis by hand is labor-intensive, time-consuming, and susceptible to human error, highlighting the need for automated pipelines to streamline the process. Our research introduces a novel approach that fine-tunes the LLM on extensive scientific datasets to address challenges in big data handling and structured data extraction. We automate and optimize the meta-analysis process by integrating Retrieval Augmented Generation (RAG). Tailored through prompt engineering and a new loss metric, Inverse Cosine Distance (ICD), designed for fine-tuning on large contextual datasets, LLMs efficiently generate structured meta-analysis content. Human evaluation then assesses relevance and provides information on model performance in key metrics. This research demonstrates that fine-tuned models outperform non-fine-tuned models, with fine-tuned LLMs generating 87.6% relevant meta-analysis abstracts. The relevance of the context, based on human evaluation, shows a reduction in irrelevancy from 4.56% to 1.9%. These experiments were conducted in a low-resource environment, highlighting the study's contribution to enhancing the efficiency and reliability of meta-analysis automation.
BanglaDialecto: An End-to-End AI-Powered Regional Speech Standardization
Nov 16, 2024



This study focuses on recognizing Bangladeshi dialects and converting diverse Bengali accents into standardized formal Bengali speech. Dialects, often referred to as regional languages, are distinctive variations of a language spoken in a particular location and are identified by their phonetics, pronunciations, and lexicon. Subtle changes in pronunciation and intonation are also influenced by geographic location, educational attainment, and socioeconomic status. Dialect standardization is needed to ensure effective communication, educational consistency, access to technology, economic opportunities, and the preservation of linguistic resources while respecting cultural diversity. Being the fifth most spoken language with around 55 distinct dialects spoken by 160 million people, addressing Bangla dialects is crucial for developing inclusive communication tools. However, limited research exists due to a lack of comprehensive datasets and the challenges of handling diverse dialects. With the advancement in multilingual Large Language Models (mLLMs), emerging possibilities have been created to address the challenges of dialectal Automated Speech Recognition (ASR) and Machine Translation (MT). This study presents an end-to-end pipeline for converting dialectal Noakhali speech to standard Bangla speech. This investigation includes constructing a large-scale diverse dataset with dialectal speech signals that tailored the fine-tuning process in ASR and LLM for transcribing the dialect speech to dialect text and translating the dialect text to standard Bangla text. Our experiments demonstrated that fine-tuning the Whisper ASR model achieved a CER of 0.8% and WER of 1.5%, while the BanglaT5 model attained a BLEU score of 41.6% for dialect-to-standard text translation.
3D Point Cloud Network Pruning: When Some Weights Do not Matter
Aug 26, 2024A point cloud is a crucial geometric data structure utilized in numerous applications. The adoption of deep neural networks referred to as Point Cloud Neural Networks (PC- NNs), for processing 3D point clouds, has significantly advanced fields that rely on 3D geometric data to enhance the efficiency of tasks. Expanding the size of both neural network models and 3D point clouds introduces significant challenges in minimizing computational and memory requirements. This is essential for meeting the demanding requirements of real-world applications, which prioritize minimal energy consumption and low latency. Therefore, investigating redundancy in PCNNs is crucial yet challenging due to their sensitivity to parameters. Additionally, traditional pruning methods face difficulties as these networks rely heavily on weights and points. Nonetheless, our research reveals a promising phenomenon that could refine standard PCNN pruning techniques. Our findings suggest that preserving only the top p% of the highest magnitude weights is crucial for accuracy preservation. For example, pruning 99% of the weights from the PointNet model still results in accuracy close to the base level. Specifically, in the ModelNet40 dataset, where the base accuracy with the PointNet model was 87. 5%, preserving only 1% of the weights still achieves an accuracy of 86.8%. Codes are available in: https://github.com/apurba-nsu-rnd-lab/PCNN_Pruning
Beyond Labels: Aligning Large Language Models with Human-like Reasoning
Aug 20, 2024



Aligning large language models (LLMs) with a human reasoning approach ensures that LLMs produce morally correct and human-like decisions. Ethical concerns are raised because current models are prone to generating false positives and providing malicious responses. To contribute to this issue, we have curated an ethics dataset named Dataset for Aligning Reasons (DFAR), designed to aid in aligning language models to generate human-like reasons. The dataset comprises statements with ethical-unethical labels and their corresponding reasons. In this study, we employed a unique and novel fine-tuning approach that utilizes ethics labels and their corresponding reasons (L+R), in contrast to the existing fine-tuning approach that only uses labels (L). The original pre-trained versions, the existing fine-tuned versions, and our proposed fine-tuned versions of LLMs were then evaluated on an ethical-unethical classification task and a reason-generation task. Our proposed fine-tuning strategy notably outperforms the others in both tasks, achieving significantly higher accuracy scores in the classification task and lower misalignment rates in the reason-generation task. The increase in classification accuracies and decrease in misalignment rates indicate that the L+R fine-tuned models align more with human ethics. Hence, this study illustrates that injecting reasons has substantially improved the alignment of LLMs, resulting in more human-like responses. We have made the DFAR dataset and corresponding codes publicly available at https://github.com/apurba-nsu-rnd-lab/DFAR.
Enhancement of Bengali OCR by Specialized Models and Advanced Techniques for Diverse Document Types
Feb 07, 2024
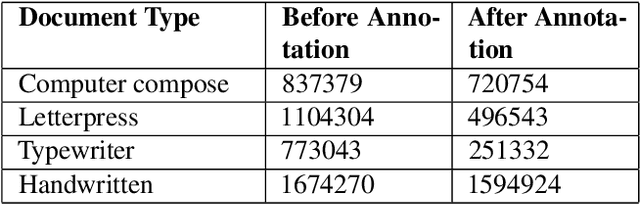
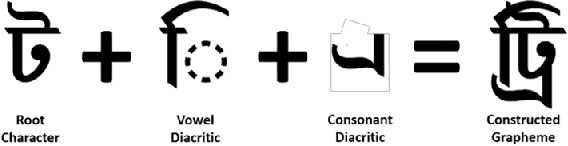
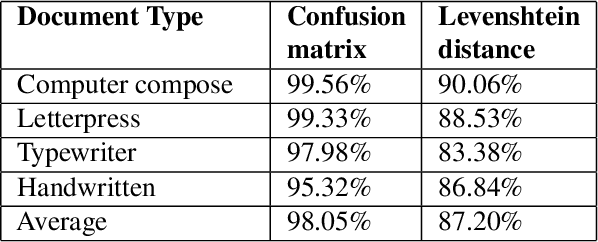
This research paper presents a unique Bengali OCR system with some capabilities. The system excels in reconstructing document layouts while preserving structure, alignment, and images. It incorporates advanced image and signature detection for accurate extraction. Specialized models for word segmentation cater to diverse document types, including computer-composed, letterpress, typewriter, and handwritten documents. The system handles static and dynamic handwritten inputs, recognizing various writing styles. Furthermore, it has the ability to recognize compound characters in Bengali. Extensive data collection efforts provide a diverse corpus, while advanced technical components optimize character and word recognition. Additional contributions include image, logo, signature and table recognition, perspective correction, layout reconstruction, and a queuing module for efficient and scalable processing. The system demonstrates outstanding performance in efficient and accurate text extraction and analysis.
* 8 pages, 7 figures, 4 table Link of the paper https://openaccess.thecvf.com/content/WACV2024W/WVLL/html/Rabby_Enhancement_of_Bengali_OCR_by_Specialized_Models_and_Advanced_Techniques_WACVW_2024_paper.html
LumiNet: The Bright Side of Perceptual Knowledge Distillation
Oct 05, 2023
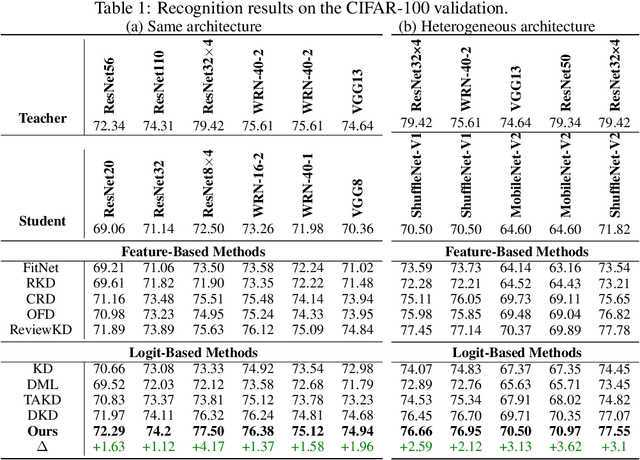

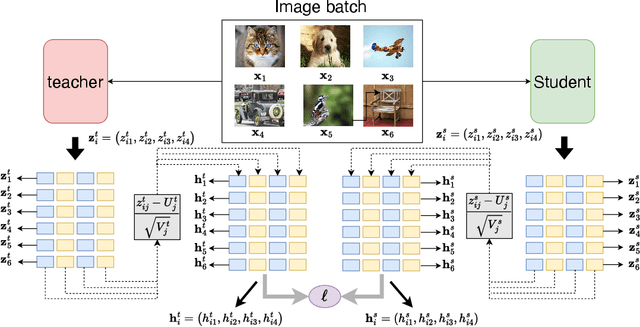
In knowledge distillation research, feature-based methods have dominated due to their ability to effectively tap into extensive teacher models. In contrast, logit-based approaches are considered to be less adept at extracting hidden 'dark knowledge' from teachers. To bridge this gap, we present LumiNet, a novel knowledge-transfer algorithm designed to enhance logit-based distillation. We introduce a perception matrix that aims to recalibrate logits through adjustments based on the model's representation capability. By meticulously analyzing intra-class dynamics, LumiNet reconstructs more granular inter-class relationships, enabling the student model to learn a richer breadth of knowledge. Both teacher and student models are mapped onto this refined matrix, with the student's goal being to minimize representational discrepancies. Rigorous testing on benchmark datasets (CIFAR-100, ImageNet, and MSCOCO) attests to LumiNet's efficacy, revealing its competitive edge over leading feature-based methods. Moreover, in exploring the realm of transfer learning, we assess how effectively the student model, trained using our method, adapts to downstream tasks. Notably, when applied to Tiny ImageNet, the transferred features exhibit remarkable performance, further underscoring LumiNet's versatility and robustness in diverse settings. With LumiNet, we hope to steer the research discourse towards a renewed interest in the latent capabilities of logit-based knowledge distillation.
Bangla-Wave: Improving Bangla Automatic Speech Recognition Utilizing N-gram Language Models
Sep 13, 2022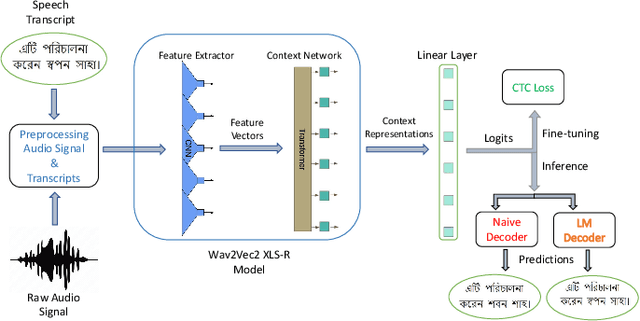
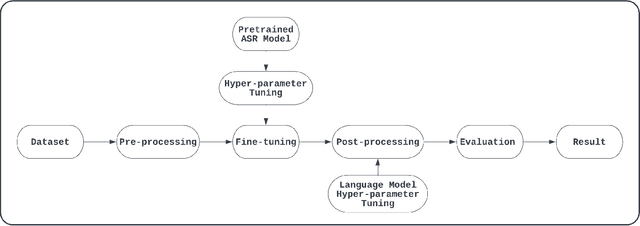
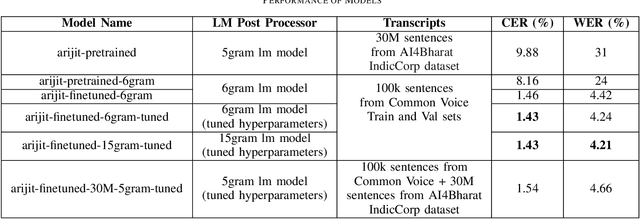
Although over 300M around the world speak Bangla, scant work has been done in improving Bangla voice-to-text transcription due to Bangla being a low-resource language. However, with the introduction of the Bengali Common Voice 9.0 speech dataset, Automatic Speech Recognition (ASR) models can now be significantly improved. With 399hrs of speech recordings, Bengali Common Voice is the largest and most diversified open-source Bengali speech corpus in the world. In this paper, we outperform the SOTA pretrained Bengali ASR models by finetuning a pretrained wav2vec2 model on the common voice dataset. We also demonstrate how to significantly improve the performance of an ASR model by adding an n-gram language model as a post-processor. Finally, we do some experiments and hyperparameter tuning to generate a robust Bangla ASR model that is better than the existing ASR models.
LILA-BOTI : Leveraging Isolated Letter Accumulations By Ordering Teacher Insights for Bangla Handwriting Recognition
May 23, 2022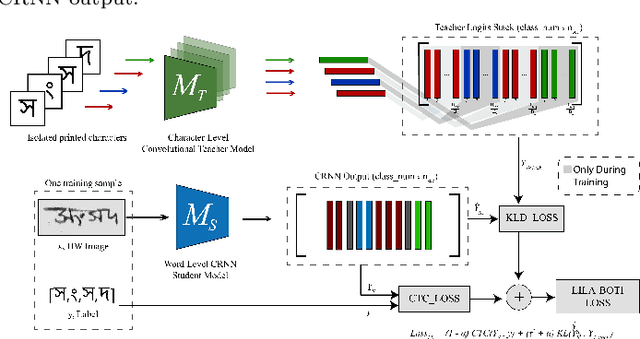
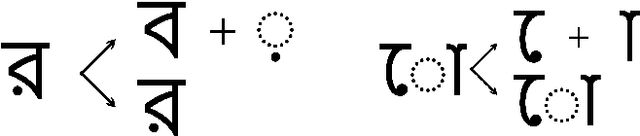
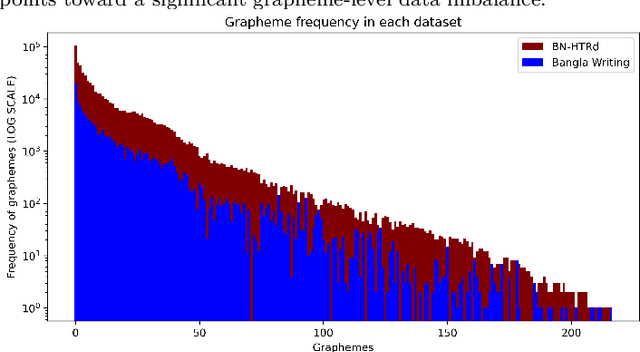
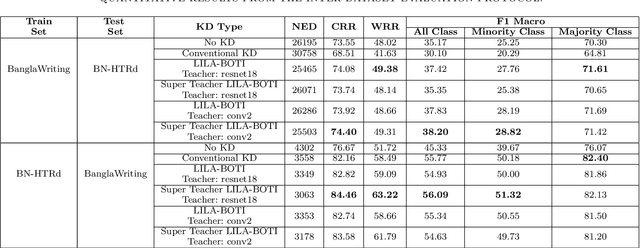
Word-level handwritten optical character recognition (OCR) remains a challenge for morphologically rich languages like Bangla. The complexity arises from the existence of a large number of alphabets, the presence of several diacritic forms, and the appearance of complex conjuncts. The difficulty is exacerbated by the fact that some graphemes occur infrequently but remain indispensable, so addressing the class imbalance is required for satisfactory results. This paper addresses this issue by introducing two knowledge distillation methods: Leveraging Isolated Letter Accumulations By Ordering Teacher Insights (LILA-BOTI) and Super Teacher LILA-BOTI. In both cases, a Convolutional Recurrent Neural Network (CRNN) student model is trained with the dark knowledge gained from a printed isolated character recognition teacher model. We conducted inter-dataset testing on \emph{BN-HTRd} and \emph{BanglaWriting} as our evaluation protocol, thus setting up a challenging problem where the results would better reflect the performance on unseen data. Our evaluations achieved up to a 3.5% increase in the F1-Macro score for the minor classes and up to 4.5% increase in our overall word recognition rate when compared with the base model (No KD) and conventional KD.