 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancement of Bengali OCR by Specialized Models and Advanced Techniques for Diverse Document Types
Feb 07, 2024
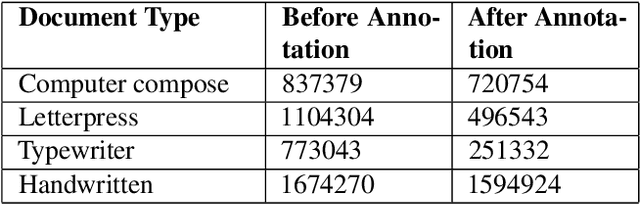
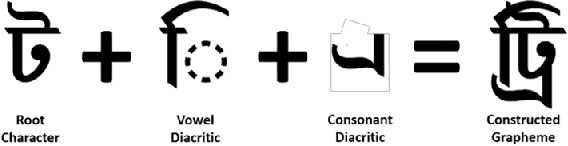
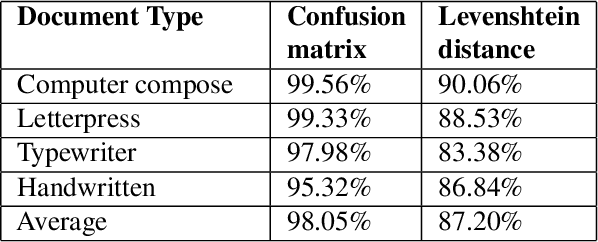
This research paper presents a unique Bengali OCR system with some capabilities. The system excels in reconstructing document layouts while preserving structure, alignment, and images. It incorporates advanced image and signature detection for accurate extraction. Specialized models for word segmentation cater to diverse document types, including computer-composed, letterpress, typewriter, and handwritten documents. The system handles static and dynamic handwritten inputs, recognizing various writing styles. Furthermore, it has the ability to recognize compound characters in Bengali. Extensive data collection efforts provide a diverse corpus, while advanced technical components optimize character and word recognition. Additional contributions include image, logo, signature and table recognition, perspective correction, layout reconstruction, and a queuing module for efficient and scalable processing. The system demonstrates outstanding performance in efficient and accurate text extraction and analysis.
* 8 pages, 7 figures, 4 table Link of the paper https://openaccess.thecvf.com/content/WACV2024W/WVLL/html/Rabby_Enhancement_of_Bengali_OCR_by_Specialized_Models_and_Advanced_Techniques_WACVW_2024_paper.html