 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Temperature Scheduler for Knowledge Distillation
Nov 14, 2025Knowledge Distillation (KD) trains a smaller student model using a large, pre-trained teacher model, with temperature as a key hyperparameter controlling the softness of output probabilities. Traditional methods use a fixed temperature throughout training, which is suboptimal. Moreover, architectural differences between teacher and student often result in mismatched logit magnitudes. We demonstrate that students benefit from softer probabilities early in training but require sharper probabilities in later stages. We introduce Dynamic Temperature Scheduler (DTS), which adjusts temperature dynamically based on the cross-entropy loss gap between teacher and student. To our knowledge, this is the first temperature scheduling method that adapts based on the divergence between teacher and student distributions. Our method integrates seamlessly with existing KD frameworks. We validate DTS across multiple KD strategies on vision (CIFAR-100, Tiny-ImageNet) and NLP tasks (GLUE, Dolly, SelfIns, UnNI, S-NI), consistently outperforming static-temperature baselines. Code is available at https://github.com/Sibgat-Ul/DTS.
LegalRAG: A Hybrid RAG System for Multilingual Legal Information Retrieval
Apr 19, 2025Natural Language Processing (NLP) and computational linguistic techniques are increasingly being applied across various domains, yet their use in legal and regulatory tasks remains limited. To address this gap, we develop an efficient bilingual question-answering framework for regulatory documents, specifically the Bangladesh Police Gazettes, which contain both English and Bangla text. Our approach employs modern Retrieval Augmented Generation (RAG) pipelines to enhance information retrieval and response generation. In addition to conventional RAG pipelines, we propose an advanced RAG-based approach that improves retrieval performance, leading to more precise answers. This system enables efficient searching for specific government legal notices, making legal information more accessible. We evaluate both our proposed and conventional RAG systems on a diverse test set on Bangladesh Police Gazettes, demonstrating that our approach consistently outperforms existing methods across all evaluation metrics.
Empowering Meta-Analysis: Leveraging Large Language Models for Scientific Synthesis
Nov 16, 2024This study investigates the automation of meta-analysis in scientific documents using large language models (LLMs). Meta-analysis is a robust statistical method that synthesizes the findings of multiple studies support articles to provide a comprehensive understanding. We know that a meta-article provides a structured analysis of several articles. However, conducting meta-analysis by hand is labor-intensive, time-consuming, and susceptible to human error, highlighting the need for automated pipelines to streamline the process. Our research introduces a novel approach that fine-tunes the LLM on extensive scientific datasets to address challenges in big data handling and structured data extraction. We automate and optimize the meta-analysis process by integrating Retrieval Augmented Generation (RAG). Tailored through prompt engineering and a new loss metric, Inverse Cosine Distance (ICD), designed for fine-tuning on large contextual datasets, LLMs efficiently generate structured meta-analysis content. Human evaluation then assesses relevance and provides information on model performance in key metrics. This research demonstrates that fine-tuned models outperform non-fine-tuned models, with fine-tuned LLMs generating 87.6% relevant meta-analysis abstracts. The relevance of the context, based on human evaluation, shows a reduction in irrelevancy from 4.56% to 1.9%. These experiments were conducted in a low-resource environment, highlighting the study's contribution to enhancing the efficiency and reliability of meta-analysis automation.
BanglaDialecto: An End-to-End AI-Powered Regional Speech Standardization
Nov 16, 2024



This study focuses on recognizing Bangladeshi dialects and converting diverse Bengali accents into standardized formal Bengali speech. Dialects, often referred to as regional languages, are distinctive variations of a language spoken in a particular location and are identified by their phonetics, pronunciations, and lexicon. Subtle changes in pronunciation and intonation are also influenced by geographic location, educational attainment, and socioeconomic status. Dialect standardization is needed to ensure effective communication, educational consistency, access to technology, economic opportunities, and the preservation of linguistic resources while respecting cultural diversity. Being the fifth most spoken language with around 55 distinct dialects spoken by 160 million people, addressing Bangla dialects is crucial for developing inclusive communication tools. However, limited research exists due to a lack of comprehensive datasets and the challenges of handling diverse dialects. With the advancement in multilingual Large Language Models (mLLMs), emerging possibilities have been created to address the challenges of dialectal Automated Speech Recognition (ASR) and Machine Translation (MT). This study presents an end-to-end pipeline for converting dialectal Noakhali speech to standard Bangla speech. This investigation includes constructing a large-scale diverse dataset with dialectal speech signals that tailored the fine-tuning process in ASR and LLM for transcribing the dialect speech to dialect text and translating the dialect text to standard Bangla text. Our experiments demonstrated that fine-tuning the Whisper ASR model achieved a CER of 0.8% and WER of 1.5%, while the BanglaT5 model attained a BLEU score of 41.6% for dialect-to-standard text translation.
Beyond Labels: Aligning Large Language Models with Human-like Reasoning
Aug 20, 2024



Aligning large language models (LLMs) with a human reasoning approach ensures that LLMs produce morally correct and human-like decisions. Ethical concerns are raised because current models are prone to generating false positives and providing malicious responses. To contribute to this issue, we have curated an ethics dataset named Dataset for Aligning Reasons (DFAR), designed to aid in aligning language models to generate human-like reasons. The dataset comprises statements with ethical-unethical labels and their corresponding reasons. In this study, we employed a unique and novel fine-tuning approach that utilizes ethics labels and their corresponding reasons (L+R), in contrast to the existing fine-tuning approach that only uses labels (L). The original pre-trained versions, the existing fine-tuned versions, and our proposed fine-tuned versions of LLMs were then evaluated on an ethical-unethical classification task and a reason-generation task. Our proposed fine-tuning strategy notably outperforms the others in both tasks, achieving significantly higher accuracy scores in the classification task and lower misalignment rates in the reason-generation task. The increase in classification accuracies and decrease in misalignment rates indicate that the L+R fine-tuned models align more with human ethics. Hence, this study illustrates that injecting reasons has substantially improved the alignment of LLMs, resulting in more human-like responses. We have made the DFAR dataset and corresponding codes publicly available at https://github.com/apurba-nsu-rnd-lab/DFAR.
Breaking Free Transformer Models: Task-specific Context Attribution Promises Improved Generalizability Without Fine-tuning Pre-trained LLMs
Jan 30, 2024Fine-tuning large pre-trained language models (LLMs) on particular datasets is a commonly employed strategy in Natural Language Processing (NLP) classification tasks. However, this approach usually results in a loss of models generalizability. In this paper, we present a framework that allows for maintaining generalizability, and enhances the performance on the downstream task by utilizing task-specific context attribution. We show that a linear transformation of the text representation from any transformer model using the task-specific concept operator results in a projection onto the latent concept space, referred to as context attribution in this paper. The specific concept operator is optimized during the supervised learning stage via novel loss functions. The proposed framework demonstrates that context attribution of the text representation for each task objective can improve the capacity of the discriminator function and thus achieve better performance for the classification task. Experimental results on three datasets, namely HateXplain, IMDB reviews, and Social Media Attributions, illustrate that the proposed model attains superior accuracy and generalizability. Specifically, for the non-fine-tuned BERT on the HateXplain dataset, we observe 8% improvement in accuracy and 10% improvement in F1-score. Whereas for the IMDB dataset, fine-tuned state-of-the-art XLNet is outperformed by 1% for both accuracy and F1-score. Furthermore, in an out-of-domain cross-dataset test, DistilBERT fine-tuned on the IMDB dataset in conjunction with the proposed model improves the F1-score on the HateXplain dataset by 7%. For the Social Media Attributions dataset of YouTube comments, we observe 5.2% increase in F1-metric. The proposed framework is implemented with PyTorch and provided open-source on GitHub.
BanLemma: A Word Formation Dependent Rule and Dictionary Based Bangla Lemmatizer
Nov 06, 2023
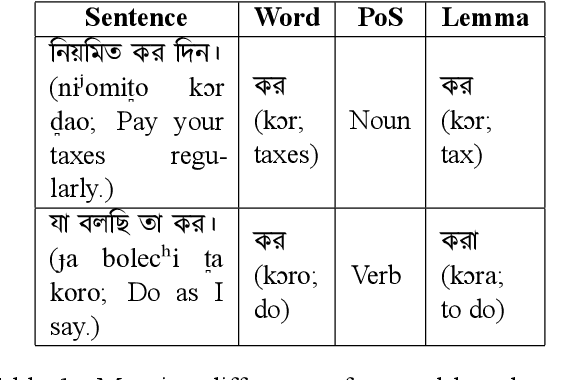


Lemmatization holds significance in both natural language processing (NLP) and linguistics, as it effectively decreases data density and aids in comprehending contextual meaning. However, due to the highly inflected nature and morphological richness, lemmatization in Bangla text poses a complex challenge. In this study, we propose linguistic rules for lemmatization and utilize a dictionary along with the rules to design a lemmatizer specifically for Bangla. Our system aims to lemmatize words based on their parts of speech class within a given sentence. Unlike previous rule-based approaches, we analyzed the suffix marker occurrence according to the morpho-syntactic values and then utilized sequences of suffix markers instead of entire suffixes. To develop our rules, we analyze a large corpus of Bangla text from various domains, sources, and time periods to observe the word formation of inflected words. The lemmatizer achieves an accuracy of 96.36% when tested against a manually annotated test dataset by trained linguists and demonstrates competitive performance on three previously published Bangla lemmatization datasets. We are making the code and datasets publicly available at https://github.com/eblict-gigatech/BanLemma in order to contribute to the further advancement of Bangla NLP.
SentiGOLD: A Large Bangla Gold Standard Multi-Domain Sentiment Analysis Dataset and its Evaluation
Jun 09, 2023


This study introduces SentiGOLD, a Bangla multi-domain sentiment analysis dataset. Comprising 70,000 samples, it was created from diverse sources and annotated by a gender-balanced team of linguists. SentiGOLD adheres to established linguistic conventions agreed upon by the Government of Bangladesh and a Bangla linguistics committee. Unlike English and other languages, Bangla lacks standard sentiment analysis datasets due to the absence of a national linguistics framework. The dataset incorporates data from online video comments, social media posts, blogs, news, and other sources while maintaining domain and class distribution rigorously. It spans 30 domains (e.g., politics, entertainment, sports) and includes 5 sentiment classes (strongly negative, weakly negative, neutral, and strongly positive). The annotation scheme, approved by the national linguistics committee, ensures a robust Inter Annotator Agreement (IAA) with a Fleiss' kappa score of 0.88. Intra- and cross-dataset evaluation protocols are applied to establish a standard classification system. Cross-dataset evaluation on the noisy SentNoB dataset presents a challenging test scenario. Additionally, zero-shot experiments demonstrate the generalizability of SentiGOLD. The top model achieves a macro f1 score of 0.62 (intra-dataset) across 5 classes, setting a benchmark, and 0.61 (cross-dataset from SentNoB) across 3 classes, comparable to the state-of-the-art. Fine-tuned sentiment analysis model can be accessed at https://sentiment.bangla.gov.bd.
BD-SHS: A Benchmark Dataset for Learning to Detect Online Bangla Hate Speech in Different Social Contexts
Jun 01, 2022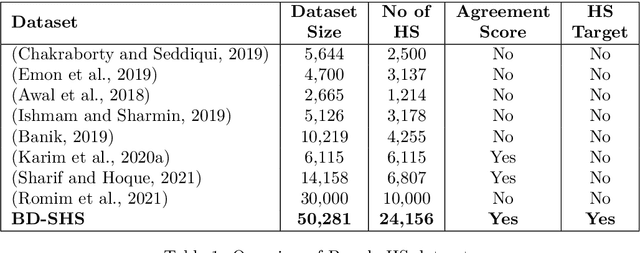

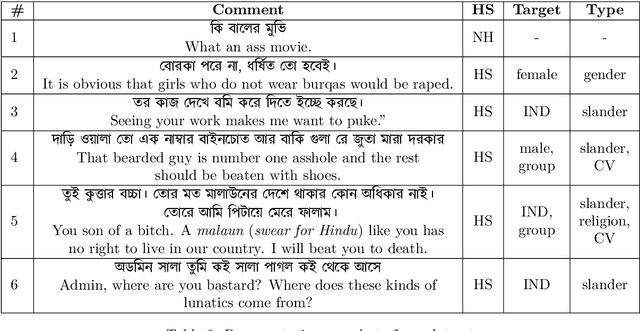
Social media platforms and online streaming services have spawned a new breed of Hate Speech (HS). Due to the massive amount of user-generated content on these sites, modern machine learning techniques are found to be feasible and cost-effective to tackle this problem. However, linguistically diverse datasets covering different social contexts in which offensive language is typically used are required to train generalizable models. In this paper, we identify the shortcomings of existing Bangla HS datasets and introduce a large manually labeled dataset BD-SHS that includes HS in different social contexts. The labeling criteria were prepared following a hierarchical annotation process, which is the first of its kind in Bangla HS to the best of our knowledge. The dataset includes more than 50,200 offensive comments crawled from online social networking sites and is at least 60% larger than any existing Bangla HS datasets. We present the benchmark result of our dataset by training different NLP models resulting in the best one achieving an F1-score of 91.0%. In our experiments, we found that a word embedding trained exclusively using 1.47 million comments from social media and streaming sites consistently resulted in better modeling of HS detection in comparison to other pre-trained embeddings. Our dataset and all accompanying codes is publicly available at github.com/naurosromim/hate-speech-dataset-for-Bengali-social-media
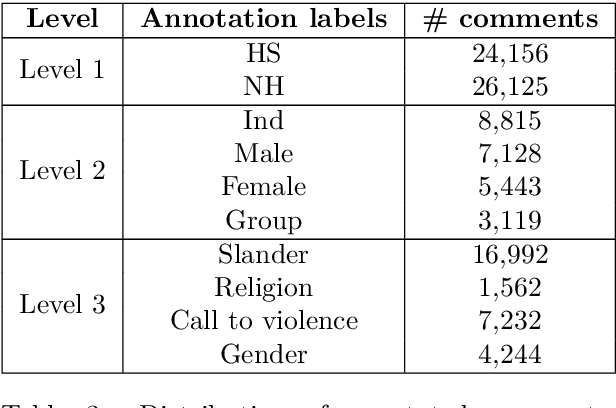
HS-BAN: A Benchmark Dataset of Social Media Comments for Hate Speech Detection in Bangla
Dec 03, 2021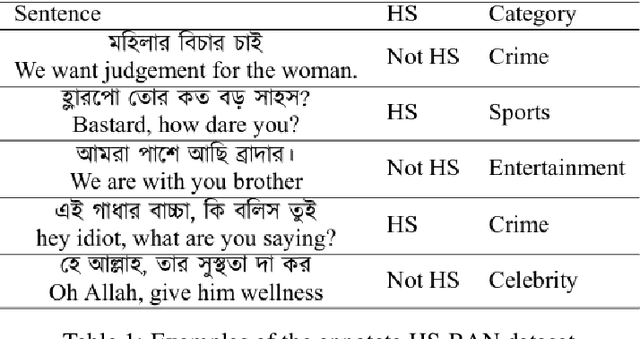
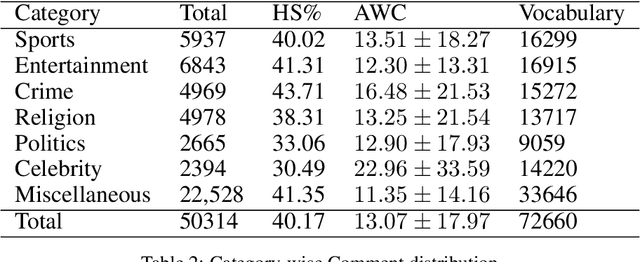
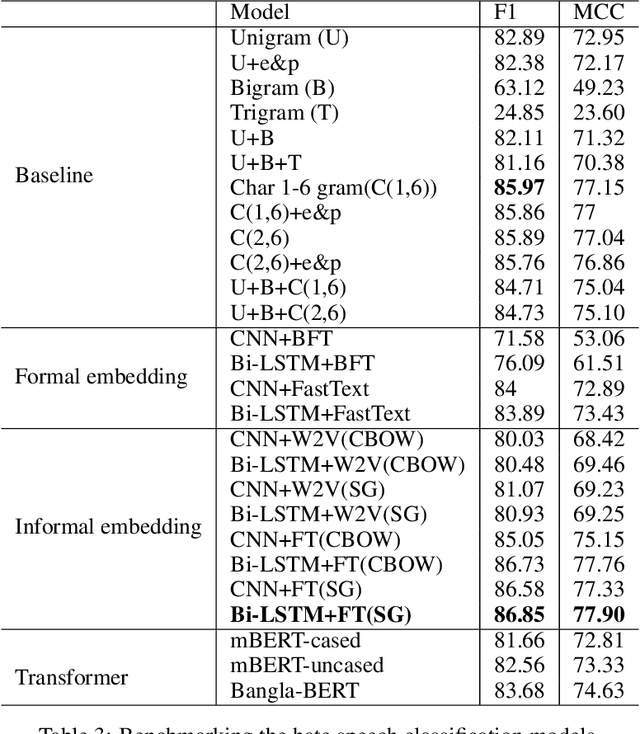
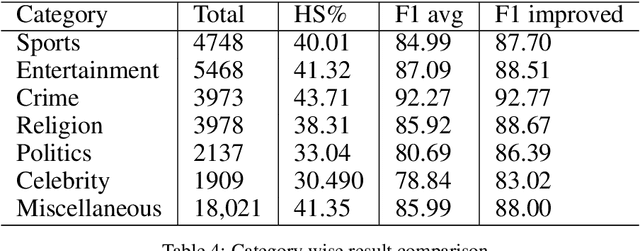
In this paper, we present HS-BAN, a binary class hate speech (HS) dataset in Bangla language consisting of more than 50,000 labeled comments, including 40.17% hate and rest are non hate speech. While preparing the dataset a strict and detailed annotation guideline was followed to reduce human annotation bias. The HS dataset was also preprocessed linguistically to extract different types of slang currently people write using symbols, acronyms, or alternative spellings. These slang words were further categorized into traditional and non-traditional slang lists and included in the results of this paper. We explored traditional linguistic features and neural network-based methods to develop a benchmark system for hate speech detection for the Bangla language. Our experimental results show that existing word embedding models trained with informal texts perform better than those trained with formal text. Our benchmark shows that a Bi-LSTM model on top of the FastText informal word embedding achieved 86.78% F1-score. We will make the dataset available for public use.