 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHS-BAN: A Benchmark Dataset of Social Media Comments for Hate Speech Detection in Bangla
Paper and Code
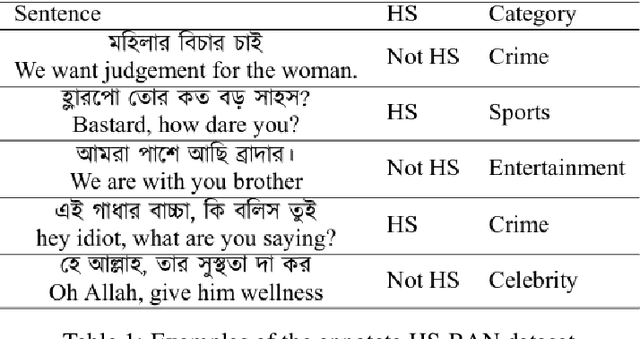
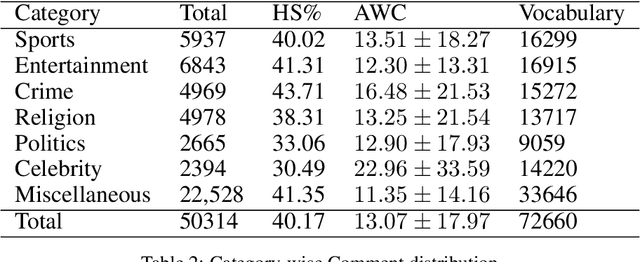
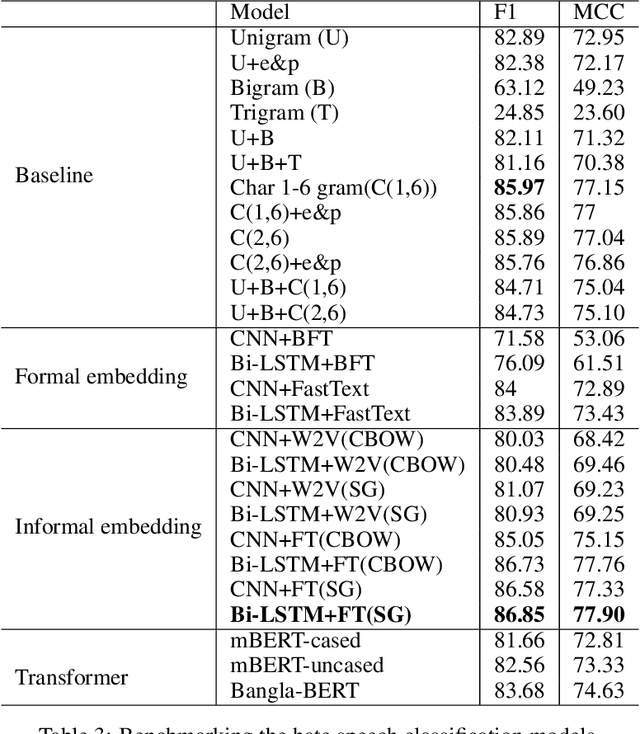
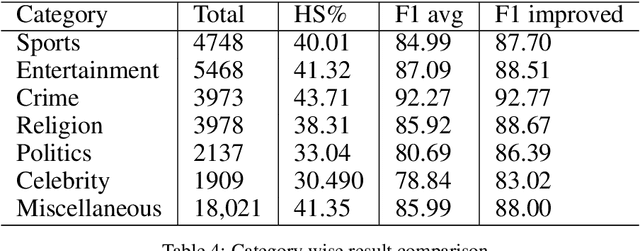
In this paper, we present HS-BAN, a binary class hate speech (HS) dataset in Bangla language consisting of more than 50,000 labeled comments, including 40.17% hate and rest are non hate speech. While preparing the dataset a strict and detailed annotation guideline was followed to reduce human annotation bias. The HS dataset was also preprocessed linguistically to extract different types of slang currently people write using symbols, acronyms, or alternative spellings. These slang words were further categorized into traditional and non-traditional slang lists and included in the results of this paper. We explored traditional linguistic features and neural network-based methods to develop a benchmark system for hate speech detection for the Bangla language. Our experimental results show that existing word embedding models trained with informal texts perform better than those trained with formal text. Our benchmark shows that a Bi-LSTM model on top of the FastText informal word embedding achieved 86.78% F1-score. We will make the dataset available for public use.