 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Real Weights: Hypercomplex Representations for Stable Quantization
Dec 09, 2025Multimodal language models (MLLMs) require large parameter capacity to align high-dimensional visual features with linguistic representations, making them computationally heavy and difficult to deploy efficiently. We introduce a progressive reparameterization strategy that compresses these models by gradually replacing dense feed-forward network blocks with compact Parameterized Hypercomplex Multiplication (PHM) layers. A residual interpolation schedule, together with lightweight reconstruction and knowledge distillation losses, ensures that the PHM modules inherit the functional behavior of their dense counterparts during training. This transition yields substantial parameter and FLOP reductions while preserving strong multimodal alignment, enabling faster inference without degrading output quality. We evaluate the approach on multiple vision-language models (VLMs). Our method maintains performance comparable to the base models while delivering significant reductions in model size and inference latency. Progressive PHM substitution thus offers an architecture-compatible path toward more efficient multimodal reasoning and complements existing low-bit quantization techniques.
LAET: A Layer-wise Adaptive Ensemble Tuning Framework for Pretrained Language Models
Nov 14, 2025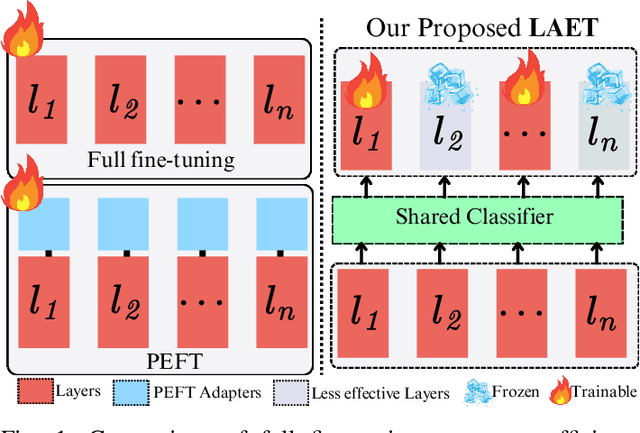
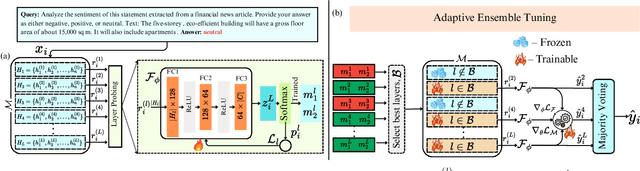
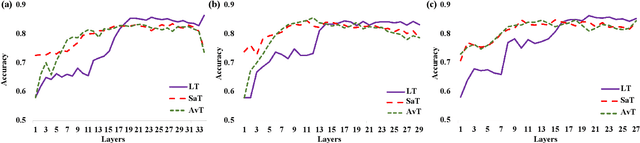
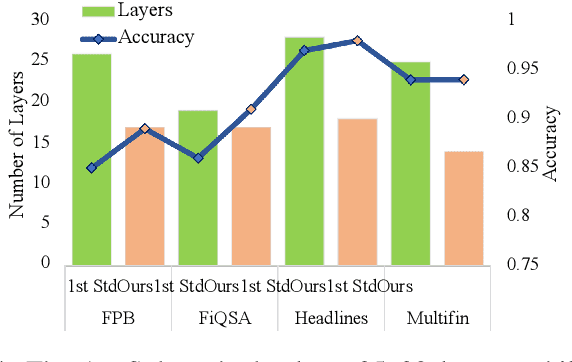
Natural Language Processing (NLP) has transformed the financial industry, enabling advancements in areas such as textual analysis, risk management, and forecasting. Large language models (LLMs) like BloombergGPT and FinMA have set new benchmarks across various financial NLP tasks, including sentiment analysis, stock movement prediction, and credit risk assessment. Furthermore, FinMA-ES, a bilingual financial LLM, has also demonstrated strong performance using the FLARE and FLARE-ES benchmarks. However, the high computational demands of these models limit the accessibility of many organizations. To address this, we propose Layer-wise Adaptive Ensemble Tuning (LAET), a novel strategy that selectively fine-tunes the most effective layers of pre-trained LLMs by analyzing hidden state representations while freezing less critical layers. LAET significantly reduces computational overhead while enhancing task-specific performance. Our approach shows strong results in financial NLP tasks, outperforming existing benchmarks and state-of-the-art LLMs such as GPT-4, even with smaller LLMs ($\sim$3B parameters). This work bridges cutting-edge financial NLP research and real-world deployment with efficient and scalable models for financial applications.
LegalRAG: A Hybrid RAG System for Multilingual Legal Information Retrieval
Apr 19, 2025Natural Language Processing (NLP) and computational linguistic techniques are increasingly being applied across various domains, yet their use in legal and regulatory tasks remains limited. To address this gap, we develop an efficient bilingual question-answering framework for regulatory documents, specifically the Bangladesh Police Gazettes, which contain both English and Bangla text. Our approach employs modern Retrieval Augmented Generation (RAG) pipelines to enhance information retrieval and response generation. In addition to conventional RAG pipelines, we propose an advanced RAG-based approach that improves retrieval performance, leading to more precise answers. This system enables efficient searching for specific government legal notices, making legal information more accessible. We evaluate both our proposed and conventional RAG systems on a diverse test set on Bangladesh Police Gazettes, demonstrating that our approach consistently outperforms existing methods across all evaluation metrics.
BanglaEmbed: Efficient Sentence Embedding Models for a Low-Resource Language Using Cross-Lingual Distillation Techniques
Nov 22, 2024



Sentence-level embedding is essential for various tasks that require understanding natural language. Many studies have explored such embeddings for high-resource languages like English. However, low-resource languages like Bengali (a language spoken by almost two hundred and thirty million people) are still under-explored. This work introduces two lightweight sentence transformers for the Bangla language, leveraging a novel cross-lingual knowledge distillation approach. This method distills knowledge from a pre-trained, high-performing English sentence transformer. Proposed models are evaluated across multiple downstream tasks, including paraphrase detection, semantic textual similarity (STS), and Bangla hate speech detection. The new method consistently outperformed existing Bangla sentence transformers. Moreover, the lightweight architecture and shorter inference time make the models highly suitable for deployment in resource-constrained environments, making them valuable for practical NLP applications in low-resource languages.
Beyond Labels: Aligning Large Language Models with Human-like Reasoning
Aug 20, 2024



Aligning large language models (LLMs) with a human reasoning approach ensures that LLMs produce morally correct and human-like decisions. Ethical concerns are raised because current models are prone to generating false positives and providing malicious responses. To contribute to this issue, we have curated an ethics dataset named Dataset for Aligning Reasons (DFAR), designed to aid in aligning language models to generate human-like reasons. The dataset comprises statements with ethical-unethical labels and their corresponding reasons. In this study, we employed a unique and novel fine-tuning approach that utilizes ethics labels and their corresponding reasons (L+R), in contrast to the existing fine-tuning approach that only uses labels (L). The original pre-trained versions, the existing fine-tuned versions, and our proposed fine-tuned versions of LLMs were then evaluated on an ethical-unethical classification task and a reason-generation task. Our proposed fine-tuning strategy notably outperforms the others in both tasks, achieving significantly higher accuracy scores in the classification task and lower misalignment rates in the reason-generation task. The increase in classification accuracies and decrease in misalignment rates indicate that the L+R fine-tuned models align more with human ethics. Hence, this study illustrates that injecting reasons has substantially improved the alignment of LLMs, resulting in more human-like responses. We have made the DFAR dataset and corresponding codes publicly available at https://github.com/apurba-nsu-rnd-lab/DFAR.