 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Improved Generative Adversarial Network for Micro-Resistivity Imaging Logging Restoration
Jun 08, 2026An improved GAN-based imaging logging image restoration method is presented in this paper for solving the problem of partially missing micro-resistivity imaging logging images. The method uses FCN as the generative network infrastructure and adds a depth-separable convolutional residual block to learn and retain more effective pixel and semantic information; an Inception module is added to increase the multi-scale perceptual field of the network and reduce the number of parameters in the network; and a multi-scale feature extraction module and a spatial attention residual block are added to combine the channel attention. The multi-scale module adds a multi-scale feature extraction module and a spatial attention residual block, which combine the channel attention mechanism and the residual block to achieve multi-scale feature extraction. The global discriminative network and the local discriminative network are designed to gradually improve the content and semantic structure coherence between the restored parts and the whole image by playing off each other and the generative network. According to the experimental results, the average structural similarity measure of the five sets of imaged logging images with different sizes of missing regions in the test set is 0.903, which is an improvement of about 0.3 compared with other similar methods. It is shown that the method in this study can be used for the restoration of micro-resistivity imaging log images with good improvement in semantic structural coherence and texture details, thus providing a new deep learning method to ensure the smooth advancement of the subsequent interpretation of micro-resistivity imaging log images.
Balancing Accuracy and Efficiency: CNN Fusion Models for Diabetic Retinopathy Screening
Dec 26, 2025Diabetic retinopathy (DR) remains a leading cause of preventable blindness, yet large-scale screening is constrained by limited specialist availability and variable image quality across devices and populations. This work investigates whether feature-level fusion of complementary convolutional neural network (CNN) backbones can deliver accurate and efficient binary DR screening on globally sourced fundus images. Using 11,156 images pooled from five public datasets (APTOS, EyePACS, IDRiD, Messidor, and ODIR), we frame DR detection as a binary classification task and compare three pretrained models (ResNet50, EfficientNet-B0, and DenseNet121) against pairwise and tri-fusion variants. Across five independent runs, fusion consistently outperforms single backbones. The EfficientNet-B0 + DenseNet121 (Eff+Den) fusion model achieves the best overall mean performance (accuracy: 82.89\%) with balanced class-wise F1-scores for normal (83.60\%) and diabetic (82.60\%) cases. While the tri-fusion is competitive, it incurs a substantially higher computational cost. Inference profiling highlights a practical trade-off: EfficientNet-B0 is the fastest (approximately 1.16 ms/image at batch size 1000), whereas the Eff+Den fusion offers a favorable accuracy--latency balance. These findings indicate that lightweight feature fusion can enhance generalization across heterogeneous datasets, supporting scalable binary DR screening workflows where both accuracy and throughput are critical.
BanglaEmbed: Efficient Sentence Embedding Models for a Low-Resource Language Using Cross-Lingual Distillation Techniques
Nov 22, 2024



Sentence-level embedding is essential for various tasks that require understanding natural language. Many studies have explored such embeddings for high-resource languages like English. However, low-resource languages like Bengali (a language spoken by almost two hundred and thirty million people) are still under-explored. This work introduces two lightweight sentence transformers for the Bangla language, leveraging a novel cross-lingual knowledge distillation approach. This method distills knowledge from a pre-trained, high-performing English sentence transformer. Proposed models are evaluated across multiple downstream tasks, including paraphrase detection, semantic textual similarity (STS), and Bangla hate speech detection. The new method consistently outperformed existing Bangla sentence transformers. Moreover, the lightweight architecture and shorter inference time make the models highly suitable for deployment in resource-constrained environments, making them valuable for practical NLP applications in low-resource languages.
Automatic Differential Diagnosis using Transformer-Based Multi-Label Sequence Classification
Aug 28, 2024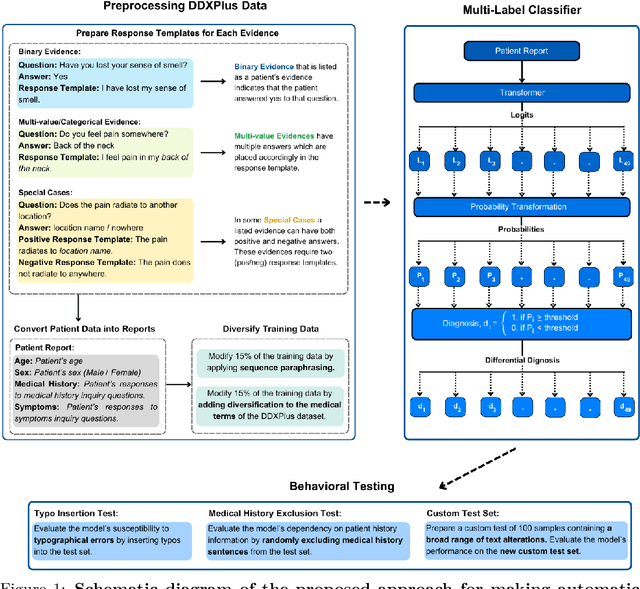
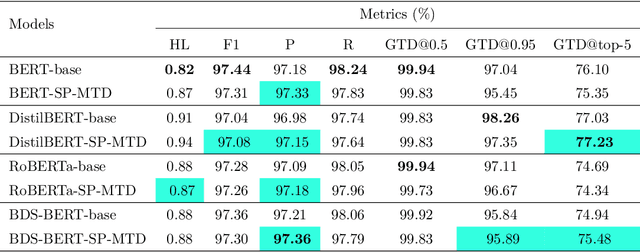


As the field of artificial intelligence progresses, assistive technologies are becoming more widely used across all industries. The healthcare industry is no different, with numerous studies being done to develop assistive tools for healthcare professionals. Automatic diagnostic systems are one such beneficial tool that can assist with a variety of tasks, including collecting patient information, analyzing test results, and diagnosing patients. However, the idea of developing systems that can provide a differential diagnosis has been largely overlooked in most of these research studies. In this study, we propose a transformer-based approach for providing differential diagnoses based on a patient's age, sex, medical history, and symptoms. We use the DDXPlus dataset, which provides differential diagnosis information for patients based on 49 disease types. Firstly, we propose a method to process the tabular patient data from the dataset and engineer them into patient reports to make them suitable for our research. In addition, we introduce two data modification modules to diversify the training data and consequently improve the robustness of the models. We approach the task as a multi-label classification problem and conduct extensive experiments using four transformer models. All the models displayed promising results by achieving over 97% F1 score on the held-out test set. Moreover, we design additional behavioral tests to get a broader understanding of the models. In particular, for one of our test cases, we prepared a custom test set of 100 samples with the assistance of a doctor. The results on the custom set showed that our proposed data modification modules improved the model's generalization capabilities. We hope our findings will provide future researchers with valuable insights and inspire them to develop reliable systems for automatic differential diagnosis.
Preserving the knowledge of long clinical texts using aggregated ensembles of large language models
Nov 02, 2023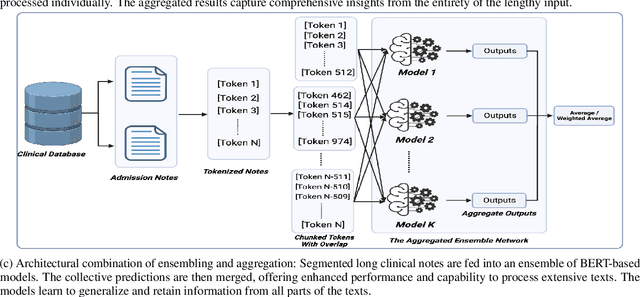

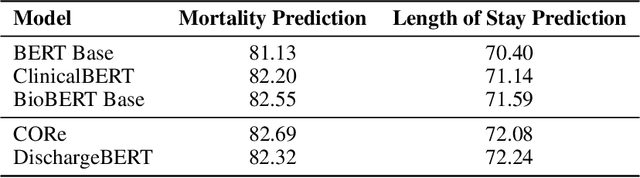
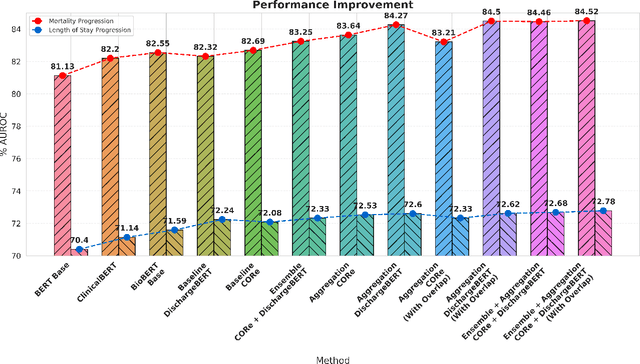
Clinical texts, such as admission notes, discharge summaries, and progress notes, contain rich and valuable information that can be used for various clinical outcome prediction tasks. However, applying large language models, such as BERT-based models, to clinical texts poses two major challenges: the limitation of input length and the diversity of data sources. This paper proposes a novel method to preserve the knowledge of long clinical texts using aggregated ensembles of large language models. Unlike previous studies which use model ensembling or text aggregation methods separately, we combine ensemble learning with text aggregation and train multiple large language models on two clinical outcome tasks: mortality prediction and length of stay prediction. We show that our method can achieve better results than baselines, ensembling, and aggregation individually, and can improve the performance of large language models while handling long inputs and diverse datasets. We conduct extensive experiments on the admission notes from the MIMIC-III clinical database by combining multiple unstructured and high-dimensional datasets, demonstrating our method's effectiveness and superiority over existing approaches. We also provide a comprehensive analysis and discussion of our results, highlighting our method's applications and limitations for future research in the domain of clinical healthcare. The results and analysis of this study is supportive of our method assisting in clinical healthcare systems by enabling clinical decision-making with robust performance overcoming the challenges of long text inputs and varied datasets.
A Comparative Study on Approaches to Acoustic Scene Classification using CNNs
Apr 26, 2022

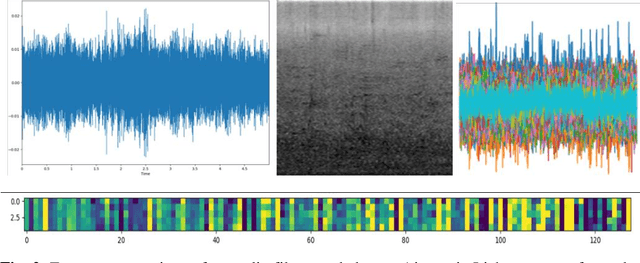

Acoustic scene classification is a process of characterizing and classifying the environments from sound recordings. The first step is to generate features (representations) from the recorded sound and then classify the background environments. However, different kinds of representations have dramatic effects on the accuracy of the classification. In this paper, we explored the three such representations on classification accuracy using neural networks. We investigated the spectrograms, MFCCs, and embeddings representations using different CNN networks and autoencoders. Our dataset consists of sounds from three settings of indoors and outdoors environments - thus the dataset contains sound from six different kinds of environments. We found that the spectrogram representation has the highest classification accuracy while MFCC has the lowest classification accuracy. We reported our findings, insights as well as some guidelines to achieve better accuracy for environment classification using sounds.
* Presented at 2021 Mexican International Conference on Artificial Intelligence. Published in Advances in Computational Intelligence, MICAI 2021, Lecture Notes in Computer Science. 12 pages, 3 figures, 5 tables