 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study on Approaches to Acoustic Scene Classification using CNNs
Apr 26, 2022

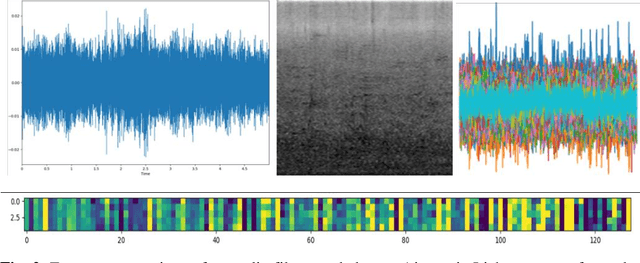

Acoustic scene classification is a process of characterizing and classifying the environments from sound recordings. The first step is to generate features (representations) from the recorded sound and then classify the background environments. However, different kinds of representations have dramatic effects on the accuracy of the classification. In this paper, we explored the three such representations on classification accuracy using neural networks. We investigated the spectrograms, MFCCs, and embeddings representations using different CNN networks and autoencoders. Our dataset consists of sounds from three settings of indoors and outdoors environments - thus the dataset contains sound from six different kinds of environments. We found that the spectrogram representation has the highest classification accuracy while MFCC has the lowest classification accuracy. We reported our findings, insights as well as some guidelines to achieve better accuracy for environment classification using sounds.
* Presented at 2021 Mexican International Conference on Artificial Intelligence. Published in Advances in Computational Intelligence, MICAI 2021, Lecture Notes in Computer Science. 12 pages, 3 figures, 5 tables