 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Real Weights: Hypercomplex Representations for Stable Quantization
Dec 09, 2025Multimodal language models (MLLMs) require large parameter capacity to align high-dimensional visual features with linguistic representations, making them computationally heavy and difficult to deploy efficiently. We introduce a progressive reparameterization strategy that compresses these models by gradually replacing dense feed-forward network blocks with compact Parameterized Hypercomplex Multiplication (PHM) layers. A residual interpolation schedule, together with lightweight reconstruction and knowledge distillation losses, ensures that the PHM modules inherit the functional behavior of their dense counterparts during training. This transition yields substantial parameter and FLOP reductions while preserving strong multimodal alignment, enabling faster inference without degrading output quality. We evaluate the approach on multiple vision-language models (VLMs). Our method maintains performance comparable to the base models while delivering significant reductions in model size and inference latency. Progressive PHM substitution thus offers an architecture-compatible path toward more efficient multimodal reasoning and complements existing low-bit quantization techniques.
LAET: A Layer-wise Adaptive Ensemble Tuning Framework for Pretrained Language Models
Nov 14, 2025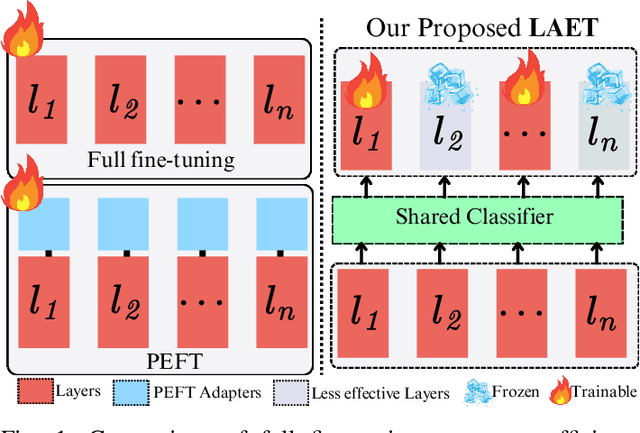
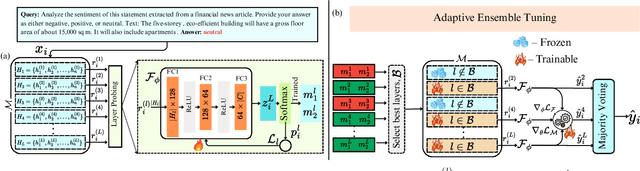
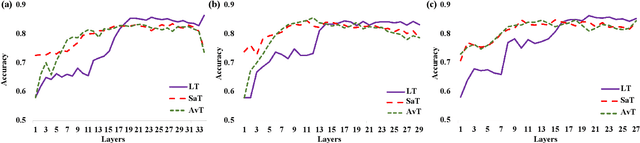
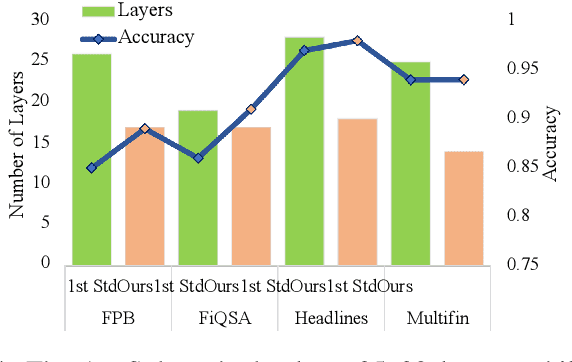
Natural Language Processing (NLP) has transformed the financial industry, enabling advancements in areas such as textual analysis, risk management, and forecasting. Large language models (LLMs) like BloombergGPT and FinMA have set new benchmarks across various financial NLP tasks, including sentiment analysis, stock movement prediction, and credit risk assessment. Furthermore, FinMA-ES, a bilingual financial LLM, has also demonstrated strong performance using the FLARE and FLARE-ES benchmarks. However, the high computational demands of these models limit the accessibility of many organizations. To address this, we propose Layer-wise Adaptive Ensemble Tuning (LAET), a novel strategy that selectively fine-tunes the most effective layers of pre-trained LLMs by analyzing hidden state representations while freezing less critical layers. LAET significantly reduces computational overhead while enhancing task-specific performance. Our approach shows strong results in financial NLP tasks, outperforming existing benchmarks and state-of-the-art LLMs such as GPT-4, even with smaller LLMs ($\sim$3B parameters). This work bridges cutting-edge financial NLP research and real-world deployment with efficient and scalable models for financial applications.
Dynamic Temperature Scheduler for Knowledge Distillation
Nov 14, 2025Knowledge Distillation (KD) trains a smaller student model using a large, pre-trained teacher model, with temperature as a key hyperparameter controlling the softness of output probabilities. Traditional methods use a fixed temperature throughout training, which is suboptimal. Moreover, architectural differences between teacher and student often result in mismatched logit magnitudes. We demonstrate that students benefit from softer probabilities early in training but require sharper probabilities in later stages. We introduce Dynamic Temperature Scheduler (DTS), which adjusts temperature dynamically based on the cross-entropy loss gap between teacher and student. To our knowledge, this is the first temperature scheduling method that adapts based on the divergence between teacher and student distributions. Our method integrates seamlessly with existing KD frameworks. We validate DTS across multiple KD strategies on vision (CIFAR-100, Tiny-ImageNet) and NLP tasks (GLUE, Dolly, SelfIns, UnNI, S-NI), consistently outperforming static-temperature baselines. Code is available at https://github.com/Sibgat-Ul/DTS.
BanglaDialecto: An End-to-End AI-Powered Regional Speech Standardization
Nov 16, 2024



This study focuses on recognizing Bangladeshi dialects and converting diverse Bengali accents into standardized formal Bengali speech. Dialects, often referred to as regional languages, are distinctive variations of a language spoken in a particular location and are identified by their phonetics, pronunciations, and lexicon. Subtle changes in pronunciation and intonation are also influenced by geographic location, educational attainment, and socioeconomic status. Dialect standardization is needed to ensure effective communication, educational consistency, access to technology, economic opportunities, and the preservation of linguistic resources while respecting cultural diversity. Being the fifth most spoken language with around 55 distinct dialects spoken by 160 million people, addressing Bangla dialects is crucial for developing inclusive communication tools. However, limited research exists due to a lack of comprehensive datasets and the challenges of handling diverse dialects. With the advancement in multilingual Large Language Models (mLLMs), emerging possibilities have been created to address the challenges of dialectal Automated Speech Recognition (ASR) and Machine Translation (MT). This study presents an end-to-end pipeline for converting dialectal Noakhali speech to standard Bangla speech. This investigation includes constructing a large-scale diverse dataset with dialectal speech signals that tailored the fine-tuning process in ASR and LLM for transcribing the dialect speech to dialect text and translating the dialect text to standard Bangla text. Our experiments demonstrated that fine-tuning the Whisper ASR model achieved a CER of 0.8% and WER of 1.5%, while the BanglaT5 model attained a BLEU score of 41.6% for dialect-to-standard text translation.
Empowering Meta-Analysis: Leveraging Large Language Models for Scientific Synthesis
Nov 16, 2024This study investigates the automation of meta-analysis in scientific documents using large language models (LLMs). Meta-analysis is a robust statistical method that synthesizes the findings of multiple studies support articles to provide a comprehensive understanding. We know that a meta-article provides a structured analysis of several articles. However, conducting meta-analysis by hand is labor-intensive, time-consuming, and susceptible to human error, highlighting the need for automated pipelines to streamline the process. Our research introduces a novel approach that fine-tunes the LLM on extensive scientific datasets to address challenges in big data handling and structured data extraction. We automate and optimize the meta-analysis process by integrating Retrieval Augmented Generation (RAG). Tailored through prompt engineering and a new loss metric, Inverse Cosine Distance (ICD), designed for fine-tuning on large contextual datasets, LLMs efficiently generate structured meta-analysis content. Human evaluation then assesses relevance and provides information on model performance in key metrics. This research demonstrates that fine-tuned models outperform non-fine-tuned models, with fine-tuned LLMs generating 87.6% relevant meta-analysis abstracts. The relevance of the context, based on human evaluation, shows a reduction in irrelevancy from 4.56% to 1.9%. These experiments were conducted in a low-resource environment, highlighting the study's contribution to enhancing the efficiency and reliability of meta-analysis automation.
Beyond Labels: Aligning Large Language Models with Human-like Reasoning
Aug 20, 2024



Aligning large language models (LLMs) with a human reasoning approach ensures that LLMs produce morally correct and human-like decisions. Ethical concerns are raised because current models are prone to generating false positives and providing malicious responses. To contribute to this issue, we have curated an ethics dataset named Dataset for Aligning Reasons (DFAR), designed to aid in aligning language models to generate human-like reasons. The dataset comprises statements with ethical-unethical labels and their corresponding reasons. In this study, we employed a unique and novel fine-tuning approach that utilizes ethics labels and their corresponding reasons (L+R), in contrast to the existing fine-tuning approach that only uses labels (L). The original pre-trained versions, the existing fine-tuned versions, and our proposed fine-tuned versions of LLMs were then evaluated on an ethical-unethical classification task and a reason-generation task. Our proposed fine-tuning strategy notably outperforms the others in both tasks, achieving significantly higher accuracy scores in the classification task and lower misalignment rates in the reason-generation task. The increase in classification accuracies and decrease in misalignment rates indicate that the L+R fine-tuned models align more with human ethics. Hence, this study illustrates that injecting reasons has substantially improved the alignment of LLMs, resulting in more human-like responses. We have made the DFAR dataset and corresponding codes publicly available at https://github.com/apurba-nsu-rnd-lab/DFAR.