 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanLemma: A Word Formation Dependent Rule and Dictionary Based Bangla Lemmatizer
Nov 06, 2023
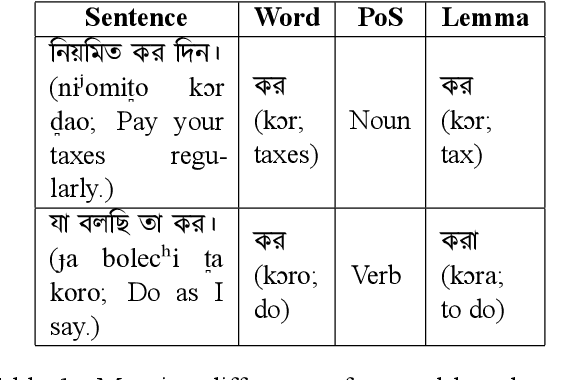


Lemmatization holds significance in both natural language processing (NLP) and linguistics, as it effectively decreases data density and aids in comprehending contextual meaning. However, due to the highly inflected nature and morphological richness, lemmatization in Bangla text poses a complex challenge. In this study, we propose linguistic rules for lemmatization and utilize a dictionary along with the rules to design a lemmatizer specifically for Bangla. Our system aims to lemmatize words based on their parts of speech class within a given sentence. Unlike previous rule-based approaches, we analyzed the suffix marker occurrence according to the morpho-syntactic values and then utilized sequences of suffix markers instead of entire suffixes. To develop our rules, we analyze a large corpus of Bangla text from various domains, sources, and time periods to observe the word formation of inflected words. The lemmatizer achieves an accuracy of 96.36% when tested against a manually annotated test dataset by trained linguists and demonstrates competitive performance on three previously published Bangla lemmatization datasets. We are making the code and datasets publicly available at https://github.com/eblict-gigatech/BanLemma in order to contribute to the further advancement of Bangla NLP.
SentiGOLD: A Large Bangla Gold Standard Multi-Domain Sentiment Analysis Dataset and its Evaluation
Jun 09, 2023


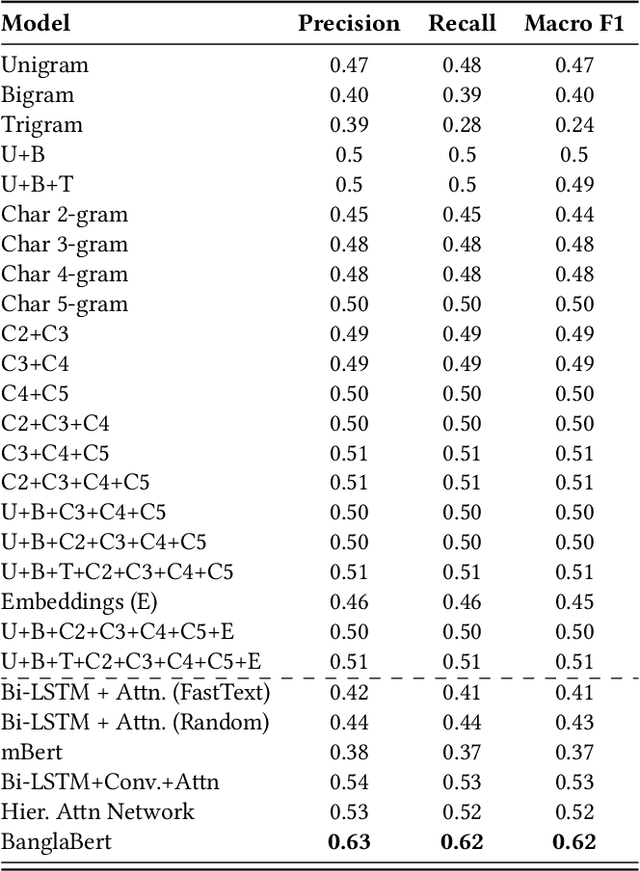
This study introduces SentiGOLD, a Bangla multi-domain sentiment analysis dataset. Comprising 70,000 samples, it was created from diverse sources and annotated by a gender-balanced team of linguists. SentiGOLD adheres to established linguistic conventions agreed upon by the Government of Bangladesh and a Bangla linguistics committee. Unlike English and other languages, Bangla lacks standard sentiment analysis datasets due to the absence of a national linguistics framework. The dataset incorporates data from online video comments, social media posts, blogs, news, and other sources while maintaining domain and class distribution rigorously. It spans 30 domains (e.g., politics, entertainment, sports) and includes 5 sentiment classes (strongly negative, weakly negative, neutral, and strongly positive). The annotation scheme, approved by the national linguistics committee, ensures a robust Inter Annotator Agreement (IAA) with a Fleiss' kappa score of 0.88. Intra- and cross-dataset evaluation protocols are applied to establish a standard classification system. Cross-dataset evaluation on the noisy SentNoB dataset presents a challenging test scenario. Additionally, zero-shot experiments demonstrate the generalizability of SentiGOLD. The top model achieves a macro f1 score of 0.62 (intra-dataset) across 5 classes, setting a benchmark, and 0.61 (cross-dataset from SentNoB) across 3 classes, comparable to the state-of-the-art. Fine-tuned sentiment analysis model can be accessed at https://sentiment.bangla.gov.bd.
LMFLOSS: A Hybrid Loss For Imbalanced Medical Image Classification
Dec 24, 2022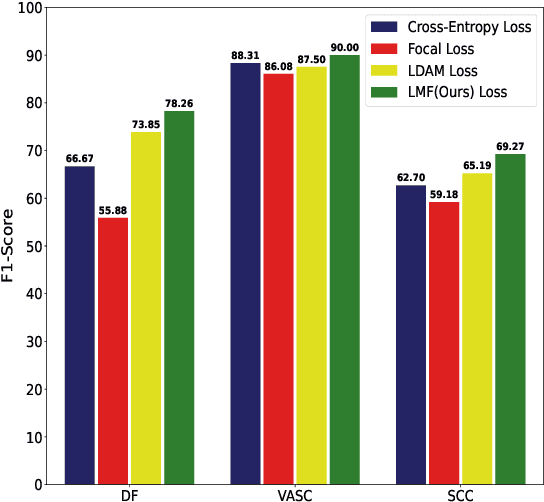



Automatic medical image classification is a very important field where the use of AI has the potential to have a real social impact. However, there are still many challenges that act as obstacles to making practically effective solutions. One of those is the fact that most of the medical imaging datasets have a class imbalance problem. This leads to the fact that existing AI techniques, particularly neural network-based deep-learning methodologies, often perform poorly in such scenarios. Thus this makes this area an interesting and active research focus for researchers. In this study, we propose a novel loss function to train neural network models to mitigate this critical issue in this important field. Through rigorous experiments on three independently collected datasets of three different medical imaging domains, we empirically show that our proposed loss function consistently performs well with an improvement between 2%-10% macro f1 when compared to the baseline models. We hope that our work will precipitate new research toward a more generalized approach to medical image classification.