 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOral to Web: Digitizing 'Zero Resource'Languages of Bangladesh
Mar 05, 2026We present the Multilingual Cloud Corpus, the first national-scale, parallel, multimodal linguistic dataset of Bangladesh's ethnic and indigenous languages. Despite being home to approximately 40 minority languages spanning four language families, Bangladesh has lacked a systematic, cross-family digital corpus for these predominantly oral, computationally "zero resource" varieties, 14 of which are classified as endangered. Our corpus comprises 85792 structured textual entries, each containing a Bengali stimulus text, an English translation, and an IPA transcription, together with approximately 107 hours of transcribed audio recordings, covering 42 language varieties from the Tibeto-Burman, Indo-European, Austro-Asiatic, and Dravidian families, plus two genetically unclassified languages. The data were collected through systematic fieldwork over 90 days across nine districts of Bangladesh, involving 16 data collectors, 77 speakers, and 43 validators, following a predefined elicitation template of 2224 unique items organized at three levels of linguistic granularity: isolated lexical items (475 words across 22 semantic domains), grammatical constructions (887 sentences across 21 categories including verbal conjugation paradigms), and directed speech (862 prompts across 46 conversational scenarios). Post-field processing included IPA transcription by 10 linguists with independent adjudication by 6 reviewers. The complete dataset is publicly accessible through the Multilingual Cloud platform (multiling.cloud), providing searchable access to annotated audio and textual data for all documented varieties. We describe the corpus design, fieldwork methodology, dataset structure, and per-language coverage, and discuss implications for endangered language documentation, low-resource NLP, and digital preservation in linguistically diverse developing countries.
Textual Toxicity in Social Media: Understanding the Bangla Toxic Language Expressed in Facebook Comment
Dec 09, 2023Social Media is a repository of digital literature including user-generated content. The users of social media are expressing their opinion with diverse mediums such as text, emojis, memes, and also through other visual and textual mediums. A major portion of these media elements could be treated as harmful to others and they are known by many words including Cyberbullying and Toxic Language . The goal of this research paper is to analyze a curated and value-added dataset of toxic language titled ToxLex_bn . It is an exhaustive wordlist that can be used as classifier material to detect toxicity in social media. The toxic language/script used by the Bengali community as cyberbullying, hate speech and moral policing became major trends in social media culture in Bangladesh and West Bengal. The toxicity became so high that the victims has to post as a counter or release explanation video for the haters. Most cases are pointed to women celebrity and their relation, dress, lifestyle are became trolled and toxicity flooded in comments boxes. Not only celebrity bashing but also hates occurred between Hindu Muslims, India-Bangladesh, Two opponents of 1971 and these are very common for virtual conflict in the comment thread. Even many times facebook comment causes sue and legal matters in Bangladesh and thus it requires more study. In this study, a Bangla toxic language dataset has been analyzed which was inputted by the user in Bengali script & language. For this, about 1968 unique bigrams or phrases as wordlists have been analyzed which are derived from 2207590 comments. It is assumed that this analysis will reinforce the detection of Bangla's toxic language used in social media and thus cure this virtual disease.
BanLemma: A Word Formation Dependent Rule and Dictionary Based Bangla Lemmatizer
Nov 06, 2023
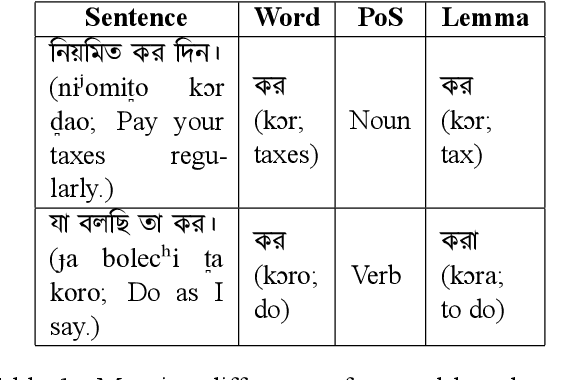


Lemmatization holds significance in both natural language processing (NLP) and linguistics, as it effectively decreases data density and aids in comprehending contextual meaning. However, due to the highly inflected nature and morphological richness, lemmatization in Bangla text poses a complex challenge. In this study, we propose linguistic rules for lemmatization and utilize a dictionary along with the rules to design a lemmatizer specifically for Bangla. Our system aims to lemmatize words based on their parts of speech class within a given sentence. Unlike previous rule-based approaches, we analyzed the suffix marker occurrence according to the morpho-syntactic values and then utilized sequences of suffix markers instead of entire suffixes. To develop our rules, we analyze a large corpus of Bangla text from various domains, sources, and time periods to observe the word formation of inflected words. The lemmatizer achieves an accuracy of 96.36% when tested against a manually annotated test dataset by trained linguists and demonstrates competitive performance on three previously published Bangla lemmatization datasets. We are making the code and datasets publicly available at https://github.com/eblict-gigatech/BanLemma in order to contribute to the further advancement of Bangla NLP.
SentiGOLD: A Large Bangla Gold Standard Multi-Domain Sentiment Analysis Dataset and its Evaluation
Jun 09, 2023


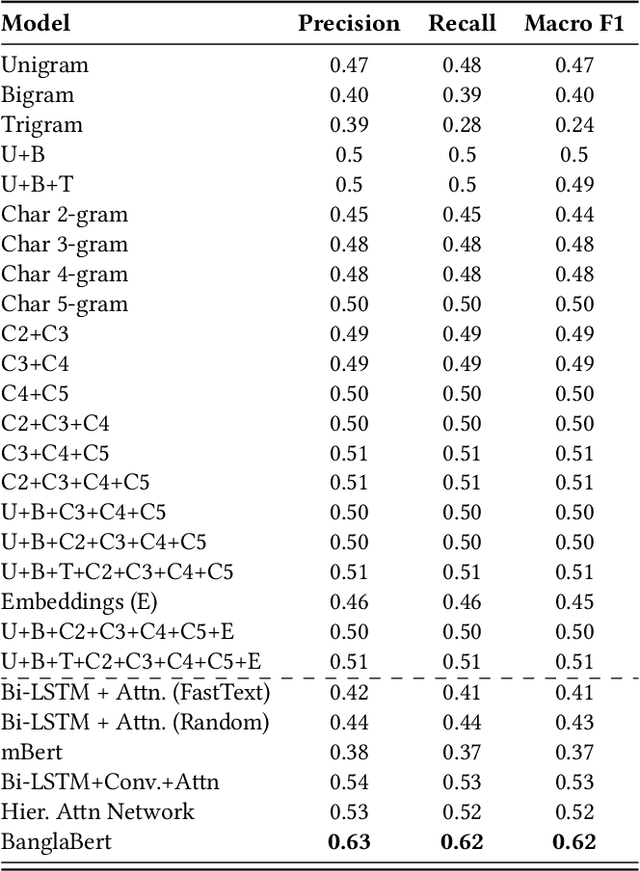
This study introduces SentiGOLD, a Bangla multi-domain sentiment analysis dataset. Comprising 70,000 samples, it was created from diverse sources and annotated by a gender-balanced team of linguists. SentiGOLD adheres to established linguistic conventions agreed upon by the Government of Bangladesh and a Bangla linguistics committee. Unlike English and other languages, Bangla lacks standard sentiment analysis datasets due to the absence of a national linguistics framework. The dataset incorporates data from online video comments, social media posts, blogs, news, and other sources while maintaining domain and class distribution rigorously. It spans 30 domains (e.g., politics, entertainment, sports) and includes 5 sentiment classes (strongly negative, weakly negative, neutral, and strongly positive). The annotation scheme, approved by the national linguistics committee, ensures a robust Inter Annotator Agreement (IAA) with a Fleiss' kappa score of 0.88. Intra- and cross-dataset evaluation protocols are applied to establish a standard classification system. Cross-dataset evaluation on the noisy SentNoB dataset presents a challenging test scenario. Additionally, zero-shot experiments demonstrate the generalizability of SentiGOLD. The top model achieves a macro f1 score of 0.62 (intra-dataset) across 5 classes, setting a benchmark, and 0.61 (cross-dataset from SentNoB) across 3 classes, comparable to the state-of-the-art. Fine-tuned sentiment analysis model can be accessed at https://sentiment.bangla.gov.bd.
BenCoref: A Multi-Domain Dataset of Nominal Phrases and Pronominal Reference Annotations
Apr 07, 2023
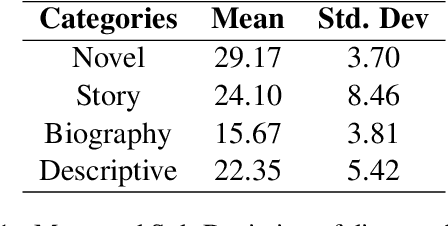
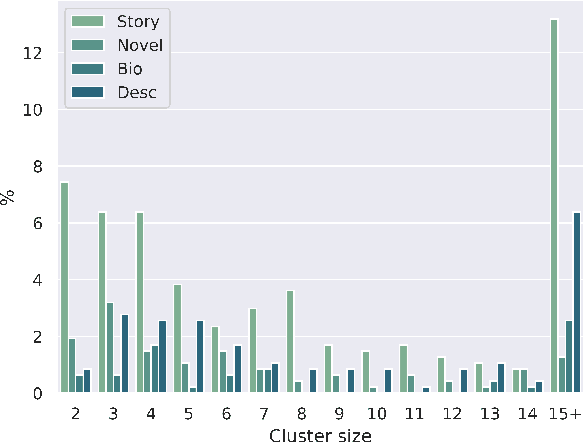
Coreference Resolution is a well studied problem in NLP. While widely studied for English and other resource-rich languages, research on coreference resolution in Bengali largely remains unexplored due to the absence of relevant datasets. Bengali, being a low-resource language, exhibits greater morphological richness compared to English. In this article, we introduce a new dataset, BenCoref, comprising coreference annotations for Bengali texts gathered from four distinct domains. This relatively small dataset contains 5200 mention annotations forming 502 mention clusters within 48,569 tokens. We describe the process of creating this dataset and report performance of multiple models trained using BenCoref. We anticipate that our work sheds some light on the variations in coreference phenomena across multiple domains in Bengali and encourages the development of additional resources for Bengali. Furthermore, we found poor crosslingual performance at zero-shot setting from English, highlighting the need for more language-specific resources for this task.