 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning in Healthcare: Model Misconducts, Security, Challenges, Applications, and Future Research Directions -- A Systematic Review
May 22, 2024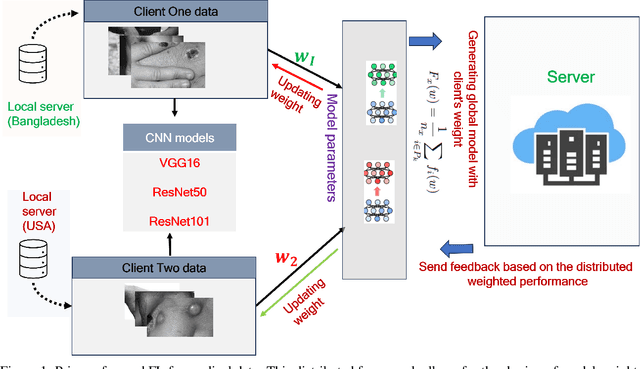
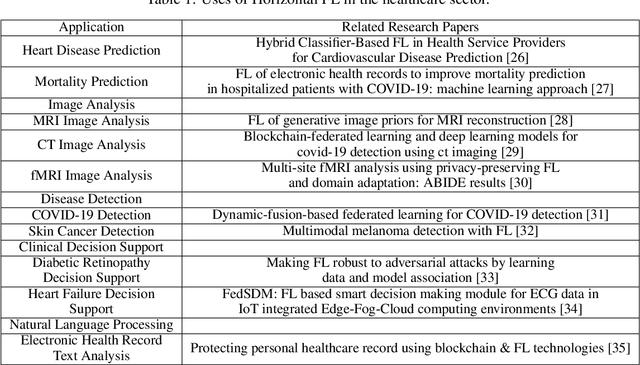
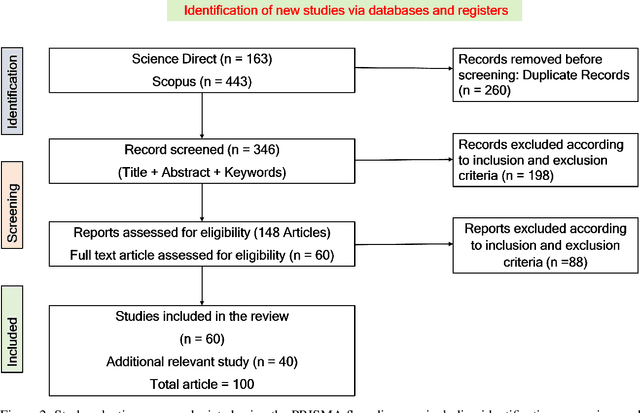

Data privacy has become a major concern in healthcare due to the increasing digitization of medical records and data-driven medical research. Protecting sensitive patient information from breaches and unauthorized access is critical, as such incidents can have severe legal and ethical complications. Federated Learning (FL) addresses this concern by enabling multiple healthcare institutions to collaboratively learn from decentralized data without sharing it. FL's scope in healthcare covers areas such as disease prediction, treatment customization, and clinical trial research. However, implementing FL poses challenges, including model convergence in non-IID (independent and identically distributed) data environments, communication overhead, and managing multi-institutional collaborations. A systematic review of FL in healthcare is necessary to evaluate how effectively FL can provide privacy while maintaining the integrity and usability of medical data analysis. In this study, we analyze existing literature on FL applications in healthcare. We explore the current state of model security practices, identify prevalent challenges, and discuss practical applications and their implications. Additionally, the review highlights promising future research directions to refine FL implementations, enhance data security protocols, and expand FL's use to broader healthcare applications, which will benefit future researchers and practitioners.
BanLemma: A Word Formation Dependent Rule and Dictionary Based Bangla Lemmatizer
Nov 06, 2023
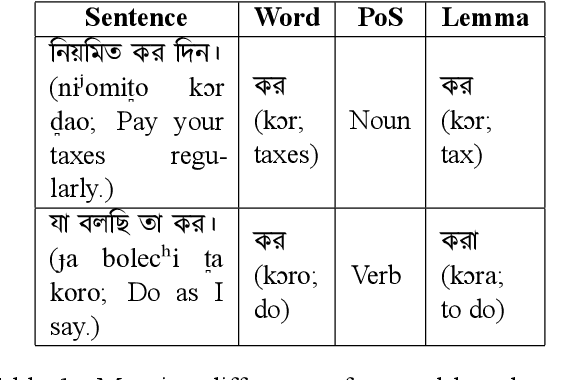


Lemmatization holds significance in both natural language processing (NLP) and linguistics, as it effectively decreases data density and aids in comprehending contextual meaning. However, due to the highly inflected nature and morphological richness, lemmatization in Bangla text poses a complex challenge. In this study, we propose linguistic rules for lemmatization and utilize a dictionary along with the rules to design a lemmatizer specifically for Bangla. Our system aims to lemmatize words based on their parts of speech class within a given sentence. Unlike previous rule-based approaches, we analyzed the suffix marker occurrence according to the morpho-syntactic values and then utilized sequences of suffix markers instead of entire suffixes. To develop our rules, we analyze a large corpus of Bangla text from various domains, sources, and time periods to observe the word formation of inflected words. The lemmatizer achieves an accuracy of 96.36% when tested against a manually annotated test dataset by trained linguists and demonstrates competitive performance on three previously published Bangla lemmatization datasets. We are making the code and datasets publicly available at https://github.com/eblict-gigatech/BanLemma in order to contribute to the further advancement of Bangla NLP.