 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning in Healthcare: Model Misconducts, Security, Challenges, Applications, and Future Research Directions -- A Systematic Review
May 22, 2024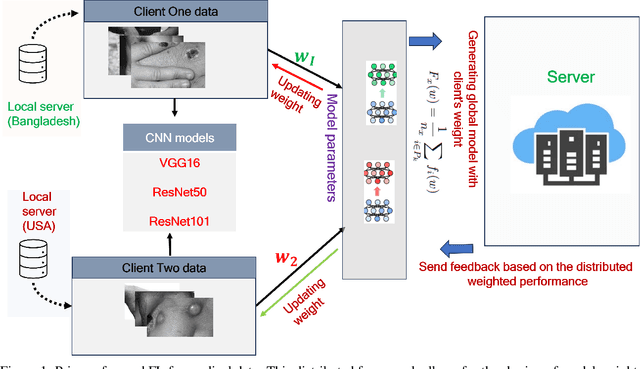
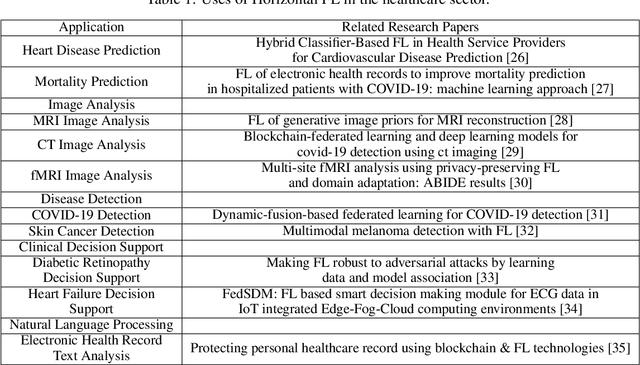
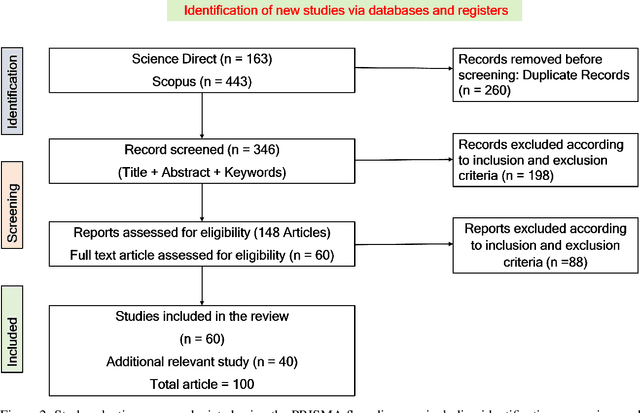

Data privacy has become a major concern in healthcare due to the increasing digitization of medical records and data-driven medical research. Protecting sensitive patient information from breaches and unauthorized access is critical, as such incidents can have severe legal and ethical complications. Federated Learning (FL) addresses this concern by enabling multiple healthcare institutions to collaboratively learn from decentralized data without sharing it. FL's scope in healthcare covers areas such as disease prediction, treatment customization, and clinical trial research. However, implementing FL poses challenges, including model convergence in non-IID (independent and identically distributed) data environments, communication overhead, and managing multi-institutional collaborations. A systematic review of FL in healthcare is necessary to evaluate how effectively FL can provide privacy while maintaining the integrity and usability of medical data analysis. In this study, we analyze existing literature on FL applications in healthcare. We explore the current state of model security practices, identify prevalent challenges, and discuss practical applications and their implications. Additionally, the review highlights promising future research directions to refine FL implementations, enhance data security protocols, and expand FL's use to broader healthcare applications, which will benefit future researchers and practitioners.
Case Studies on X-Ray Imaging, MRI and Nuclear Imaging
Jun 17, 2023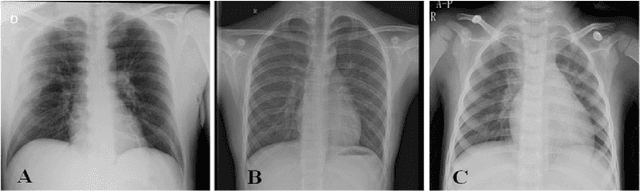
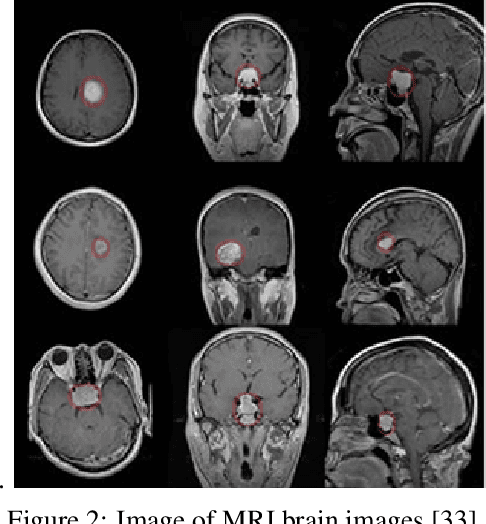

The field of medical imaging is an essential aspect of the medical sciences, involving various forms of radiation to capture images of the internal tissues and organs of the body. These images provide vital information for clinical diagnosis, and in this chapter, we will explore the use of X-ray, MRI, and nuclear imaging in detecting severe illnesses. However, manual evaluation and storage of these images can be a challenging and time-consuming process. To address this issue, artificial intelligence (AI)-based techniques, particularly deep learning (DL), have become increasingly popular for systematic feature extraction and classification from imaging modalities, thereby aiding doctors in making rapid and accurate diagnoses. In this review study, we will focus on how AI-based approaches, particularly the use of Convolutional Neural Networks (CNN), can assist in disease detection through medical imaging technology. CNN is a commonly used approach for image analysis due to its ability to extract features from raw input images, and as such, will be the primary area of discussion in this study. Therefore, we have considered CNN as our discussion area in this study to diagnose ailments using medical imaging technology.
Active Learning on Medical Image
Jun 07, 2023



The development of medical science greatly depends on the increased utilization of machine learning algorithms. By incorporating machine learning, the medical imaging field can significantly improve in terms of the speed and accuracy of the diagnostic process. Computed tomography (CT), magnetic resonance imaging (MRI), X-ray imaging, ultrasound imaging, and positron emission tomography (PET) are the most commonly used types of imaging data in the diagnosis process, and machine learning can aid in detecting diseases at an early stage. However, training machine learning models with limited annotated medical image data poses a challenge. The majority of medical image datasets have limited data, which can impede the pattern-learning process of machine-learning algorithms. Additionally, the lack of labeled data is another critical issue for machine learning. In this context, active learning techniques can be employed to address the challenge of limited annotated medical image data. Active learning involves iteratively selecting the most informative samples from a large pool of unlabeled data for annotation by experts. By actively selecting the most relevant and informative samples, active learning reduces the reliance on large amounts of labeled data and maximizes the model's learning capacity with minimal human labeling effort. By incorporating active learning into the training process, medical imaging machine learning models can make more efficient use of the available labeled data, improving their accuracy and performance. This approach allows medical professionals to focus their efforts on annotating the most critical cases, while the machine learning model actively learns from these annotated samples to improve its diagnostic capabilities.
Few Shot Learning for Medical Imaging: A Comparative Analysis of Methodologies and Formal Mathematical Framework
May 08, 2023Deep learning becomes an elevated context regarding disposing of many machine learning tasks and has shown a breakthrough upliftment to extract features from unstructured data. Though this flourishing context is developing in the medical image processing sector, scarcity of problem-dependent training data has become a larger issue in the way of easy application of deep learning in the medical sector. To unravel the confined data source, researchers have developed a model that can solve machine learning problems with fewer data called ``Few shot learning". Few hot learning algorithms determine to solve the data limitation problems by extracting the characteristics from a small dataset through classification and segmentation methods. In the medical sector, there is frequently a shortage of available datasets in respect of some confidential diseases. Therefore, Few shot learning gets the limelight in this data scarcity sector. In this chapter, the background and basic overview of a few shots of learning is represented. Henceforth, the classification of few-shot learning is described also. Even the paper shows a comparison of methodological approaches that are applied in medical image analysis over time. The current advancement in the implementation of few-shot learning concerning medical imaging is illustrated. The future scope of this domain in the medical imaging sector is further described.
Transfer learning and Local interpretable model agnostic based visual approach in Monkeypox Disease Detection and Classification: A Deep Learning insights
Nov 14, 2022



The recent development of Monkeypox disease among various nations poses a global pandemic threat when the world is still fighting Coronavirus Disease-2019 (COVID-19). At its dawn, the slow and steady transmission of Monkeypox disease among individuals needs to be addressed seriously. Over the years, Deep learning (DL) based disease prediction has demonstrated true potential by providing early, cheap, and affordable diagnosis facilities. Considering this opportunity, we have conducted two studies where we modified and tested six distinct deep learning models-VGG16, InceptionResNetV2, ResNet50, ResNet101, MobileNetV2, and VGG19-using transfer learning approaches. Our preliminary computational results show that the proposed modified InceptionResNetV2 and MobileNetV2 models perform best by achieving an accuracy ranging from 93% to 99%. Our findings are reinforced by recent academic work that demonstrates improved performance in constructing multiple disease diagnosis models using transfer learning approaches. Lastly, we further explain our model prediction using Local Interpretable Model-Agnostic Explanations (LIME), which play an essential role in identifying important features that characterize the onset of Monkeypox disease.
Imbalanced Class Data Performance Evaluation and Improvement using Novel Generative Adversarial Network-based Approach: SSG and GBO
Oct 23, 2022Class imbalance in a dataset is one of the major challenges that can significantly impact the performance of machine learning models resulting in biased predictions. Numerous techniques have been proposed to address class imbalanced problems, including, but not limited to, Oversampling, Undersampling, and cost-sensitive approaches. Due to its ability to generate synthetic data, oversampling techniques such as the Synthetic Minority Oversampling Technique (SMOTE) is among the most widely used methodology by researchers. However, one of SMOTE's potential disadvantages is that newly created minor samples may overlap with major samples. As an effect, the probability of ML models' biased performance towards major classes increases. Recently, generative adversarial network (GAN) has garnered much attention due to its ability to create almost real samples. However, GAN is hard to train even though it has much potential. This study proposes two novel techniques: GAN-based Oversampling (GBO) and Support Vector Machine-SMOTE-GAN (SSG) to overcome the limitations of the existing oversampling approaches. The preliminary computational result shows that SSG and GBO performed better on the expanded imbalanced eight benchmark datasets than the original SMOTE. The study also revealed that the minor sample generated by SSG demonstrates Gaussian distributions, which is often difficult to achieve using original SMOTE.