 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Point Cloud Network Pruning: When Some Weights Do not Matter
Aug 26, 2024A point cloud is a crucial geometric data structure utilized in numerous applications. The adoption of deep neural networks referred to as Point Cloud Neural Networks (PC- NNs), for processing 3D point clouds, has significantly advanced fields that rely on 3D geometric data to enhance the efficiency of tasks. Expanding the size of both neural network models and 3D point clouds introduces significant challenges in minimizing computational and memory requirements. This is essential for meeting the demanding requirements of real-world applications, which prioritize minimal energy consumption and low latency. Therefore, investigating redundancy in PCNNs is crucial yet challenging due to their sensitivity to parameters. Additionally, traditional pruning methods face difficulties as these networks rely heavily on weights and points. Nonetheless, our research reveals a promising phenomenon that could refine standard PCNN pruning techniques. Our findings suggest that preserving only the top p% of the highest magnitude weights is crucial for accuracy preservation. For example, pruning 99% of the weights from the PointNet model still results in accuracy close to the base level. Specifically, in the ModelNet40 dataset, where the base accuracy with the PointNet model was 87. 5%, preserving only 1% of the weights still achieves an accuracy of 86.8%. Codes are available in: https://github.com/apurba-nsu-rnd-lab/PCNN_Pruning
LumiNet: The Bright Side of Perceptual Knowledge Distillation
Oct 05, 2023
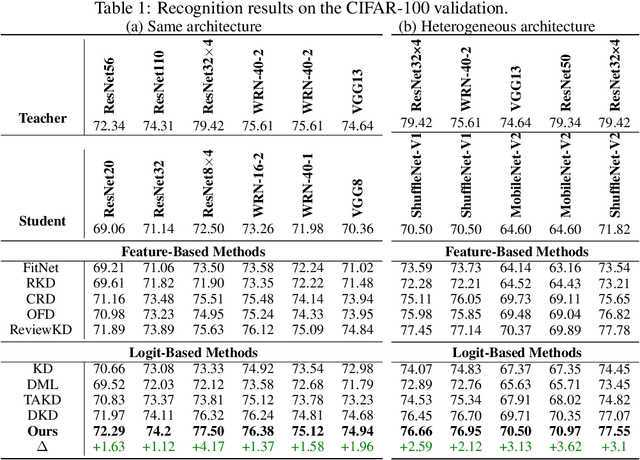

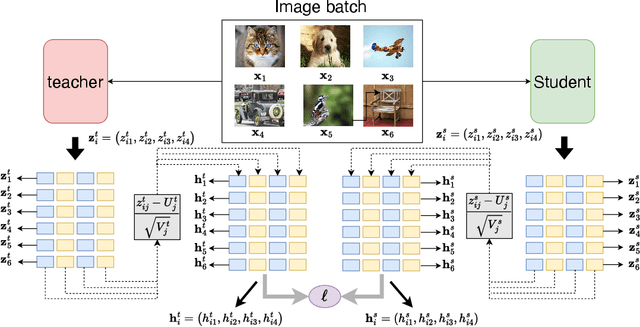
In knowledge distillation research, feature-based methods have dominated due to their ability to effectively tap into extensive teacher models. In contrast, logit-based approaches are considered to be less adept at extracting hidden 'dark knowledge' from teachers. To bridge this gap, we present LumiNet, a novel knowledge-transfer algorithm designed to enhance logit-based distillation. We introduce a perception matrix that aims to recalibrate logits through adjustments based on the model's representation capability. By meticulously analyzing intra-class dynamics, LumiNet reconstructs more granular inter-class relationships, enabling the student model to learn a richer breadth of knowledge. Both teacher and student models are mapped onto this refined matrix, with the student's goal being to minimize representational discrepancies. Rigorous testing on benchmark datasets (CIFAR-100, ImageNet, and MSCOCO) attests to LumiNet's efficacy, revealing its competitive edge over leading feature-based methods. Moreover, in exploring the realm of transfer learning, we assess how effectively the student model, trained using our method, adapts to downstream tasks. Notably, when applied to Tiny ImageNet, the transferred features exhibit remarkable performance, further underscoring LumiNet's versatility and robustness in diverse settings. With LumiNet, we hope to steer the research discourse towards a renewed interest in the latent capabilities of logit-based knowledge distillation.