 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAPE: CAM as a Probabilistic Ensemble for Enhanced DNN Interpretation
Apr 04, 2024Deep Neural Networks (DNNs) are widely used for visual classification tasks, but their complex computation process and black-box nature hinder decision transparency and interpretability. Class activation maps (CAMs) and recent variants provide ways to visually explain the DNN decision-making process by displaying 'attention' heatmaps of the DNNs. Nevertheless, the CAM explanation only offers relative attention information, that is, on an attention heatmap, we can interpret which image region is more or less important than the others. However, these regions cannot be meaningfully compared across classes, and the contribution of each region to the model's class prediction is not revealed. To address these challenges that ultimately lead to better DNN Interpretation, in this paper, we propose CAPE, a novel reformulation of CAM that provides a unified and probabilistically meaningful assessment of the contributions of image regions. We quantitatively and qualitatively compare CAPE with state-of-the-art CAM methods on CUB and ImageNet benchmark datasets to demonstrate enhanced interpretability. We also test on a cytology imaging dataset depicting a challenging Chronic Myelomonocytic Leukemia (CMML) diagnosis problem. Code is available at: https://github.com/AIML-MED/CAPE.
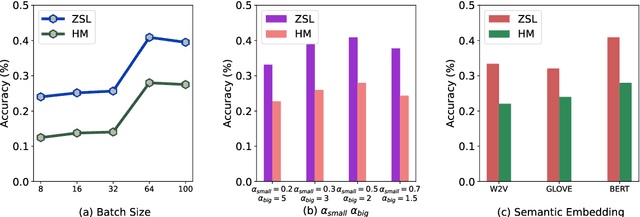
ChatGPT-guided Semantics for Zero-shot Learning
Oct 18, 2023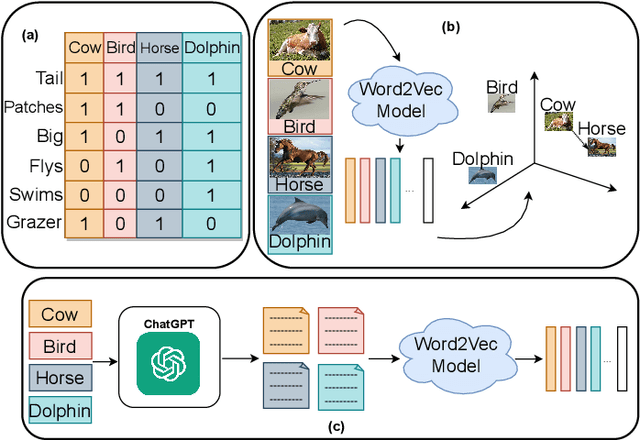
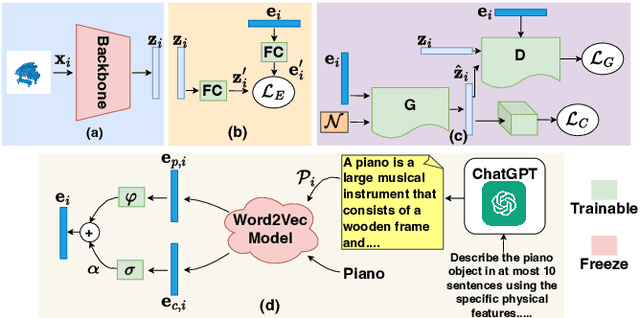
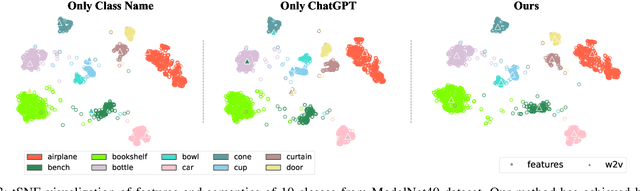
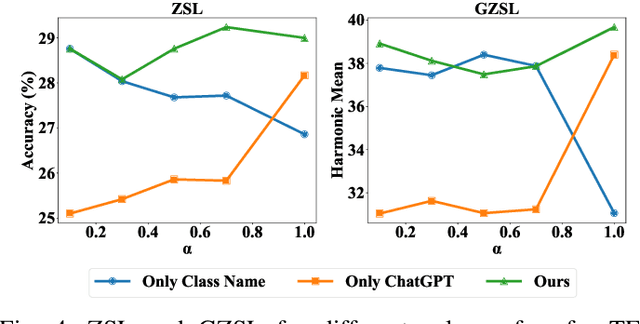
Zero-shot learning (ZSL) aims to classify objects that are not observed or seen during training. It relies on class semantic description to transfer knowledge from the seen classes to the unseen classes. Existing methods of obtaining class semantics include manual attributes or automatic word vectors from language models (like word2vec). We know attribute annotation is costly, whereas automatic word-vectors are relatively noisy. To address this problem, we explore how ChatGPT, a large language model, can enhance class semantics for ZSL tasks. ChatGPT can be a helpful source to obtain text descriptions for each class containing related attributes and semantics. We use the word2vec model to get a word vector using the texts from ChatGPT. Then, we enrich word vectors by combining the word embeddings from class names and descriptions generated by ChatGPT. More specifically, we leverage ChatGPT to provide extra supervision for the class description, eventually benefiting ZSL models. We evaluate our approach on various 2D image (CUB and AwA) and 3D point cloud (ModelNet10, ModelNet40, and ScanObjectNN) datasets and show that it improves ZSL performance. Our work contributes to the ZSL literature by applying ChatGPT for class semantics enhancement and proposing a novel word vector fusion method.
Prompt-guided Scene Generation for 3D Zero-Shot Learning
Sep 29, 2022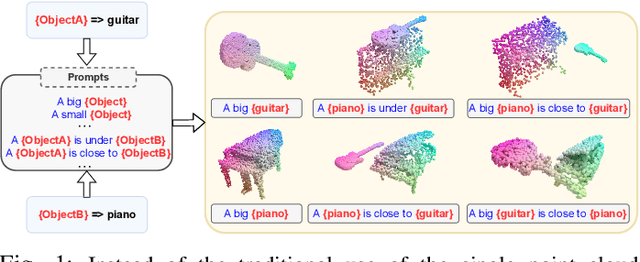
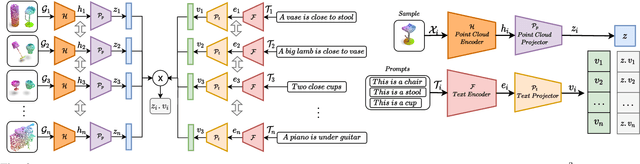

Zero-shot learning on 3D point cloud data is a related underexplored problem compared to its 2D image counterpart. 3D data brings new challenges for ZSL due to the unavailability of robust pre-trained feature extraction models. To address this problem, we propose a prompt-guided 3D scene generation and supervision method that augments 3D data to learn the network better, exploring the complex interplay of seen and unseen objects. First, we merge point clouds of two 3D models in certain ways described by a prompt. The prompt acts like the annotation describing each 3D scene. Later, we perform contrastive learning to train our proposed architecture in an end-to-end manner. We argue that 3D scenes can relate objects more efficiently than single objects because popular language models (like BERT) can achieve high performance when objects appear in a context. Our proposed prompt-guided scene generation method encapsulates data augmentation and prompt-based annotation/captioning to improve 3D ZSL performance. We have achieved state-of-the-art ZSL and generalized ZSL performance on synthetic (ModelNet40, ModelNet10) and real-scanned (ScanOjbectNN) 3D object datasets.
Rethinking Task-Incremental Learning Baselines
May 23, 2022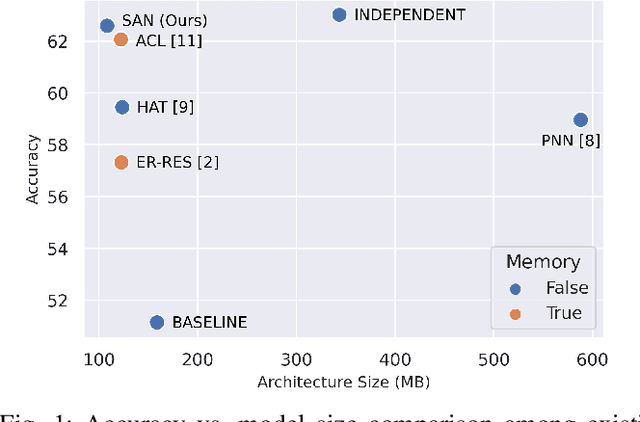
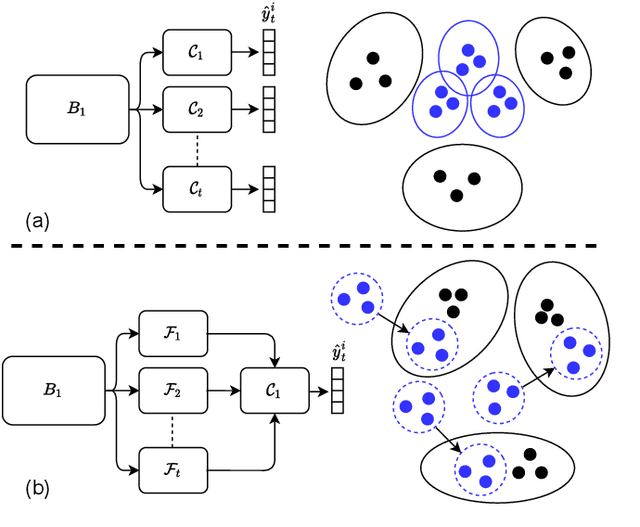
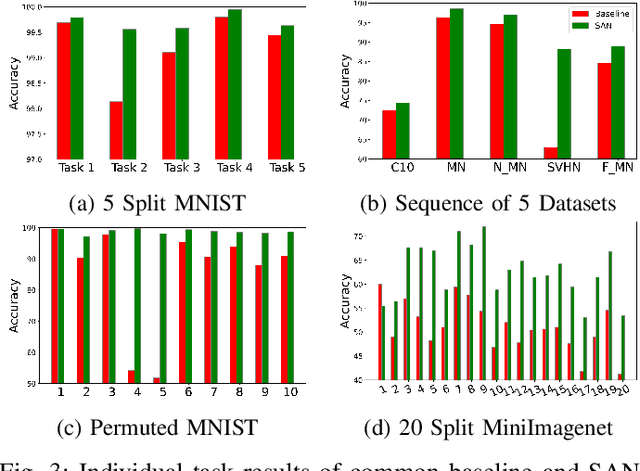
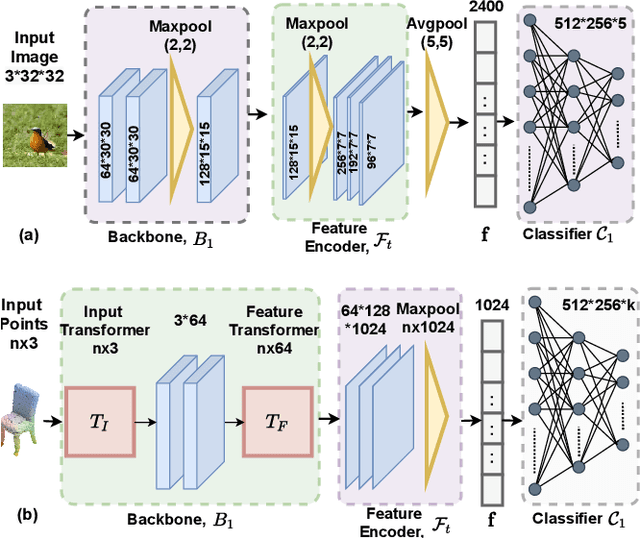
It is common to have continuous streams of new data that need to be introduced in the system in real-world applications. The model needs to learn newly added capabilities (future tasks) while retaining the old knowledge (past tasks). Incremental learning has recently become increasingly appealing for this problem. Task-incremental learning is a kind of incremental learning where task identity of newly included task (a set of classes) remains known during inference. A common goal of task-incremental methods is to design a network that can operate on minimal size, maintaining decent performance. To manage the stability-plasticity dilemma, different methods utilize replay memory of past tasks, specialized hardware, regularization monitoring etc. However, these methods are still less memory efficient in terms of architecture growth or input data costs. In this study, we present a simple yet effective adjustment network (SAN) for task incremental learning that achieves near state-of-the-art performance while using minimal architectural size without using memory instances compared to previous state-of-the-art approaches. We investigate this approach on both 3D point cloud object (ModelNet40) and 2D image (CIFAR10, CIFAR100, MiniImageNet, MNIST, PermutedMNIST, notMNIST, SVHN, and FashionMNIST) recognition tasks and establish a strong baseline result for a fair comparison with existing methods. On both 2D and 3D domains, we also observe that SAN is primarily unaffected by different task orders in a task-incremental setting.