 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Task-Incremental Learning Baselines
May 23, 2022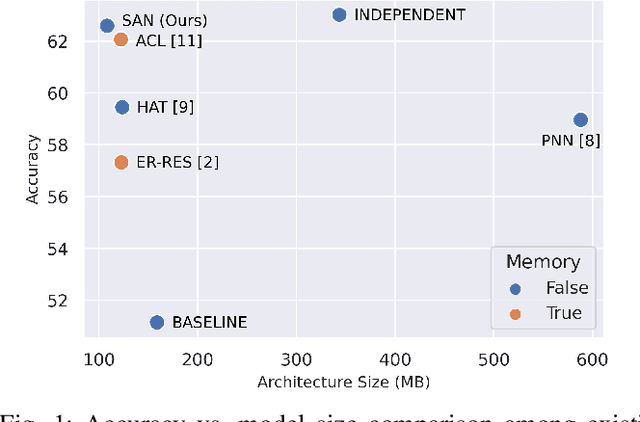
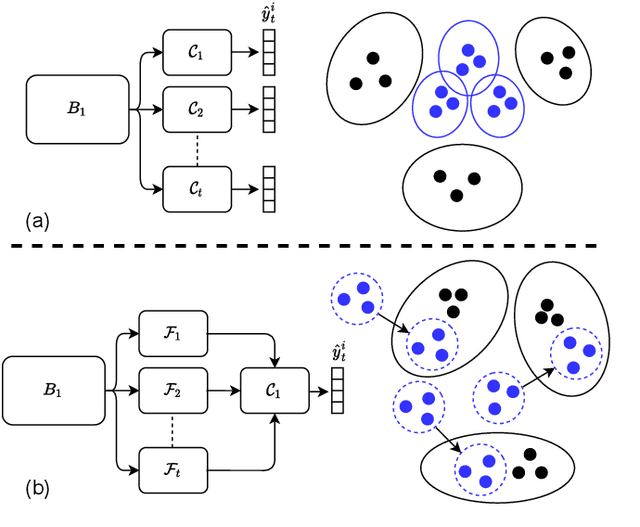
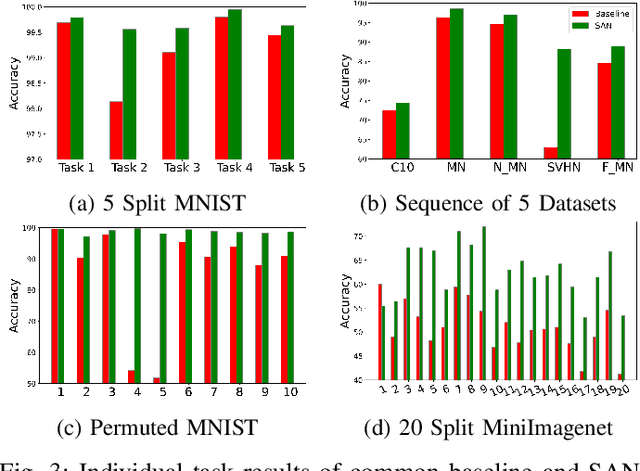
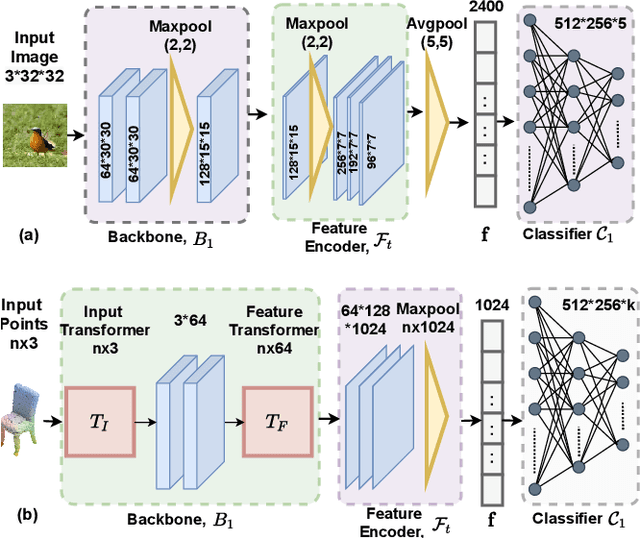
It is common to have continuous streams of new data that need to be introduced in the system in real-world applications. The model needs to learn newly added capabilities (future tasks) while retaining the old knowledge (past tasks). Incremental learning has recently become increasingly appealing for this problem. Task-incremental learning is a kind of incremental learning where task identity of newly included task (a set of classes) remains known during inference. A common goal of task-incremental methods is to design a network that can operate on minimal size, maintaining decent performance. To manage the stability-plasticity dilemma, different methods utilize replay memory of past tasks, specialized hardware, regularization monitoring etc. However, these methods are still less memory efficient in terms of architecture growth or input data costs. In this study, we present a simple yet effective adjustment network (SAN) for task incremental learning that achieves near state-of-the-art performance while using minimal architectural size without using memory instances compared to previous state-of-the-art approaches. We investigate this approach on both 3D point cloud object (ModelNet40) and 2D image (CIFAR10, CIFAR100, MiniImageNet, MNIST, PermutedMNIST, notMNIST, SVHN, and FashionMNIST) recognition tasks and establish a strong baseline result for a fair comparison with existing methods. On both 2D and 3D domains, we also observe that SAN is primarily unaffected by different task orders in a task-incremental setting.
Adaptive Class Weight based Dual Focal Loss for Improved Semantic Segmentation
Oct 13, 2019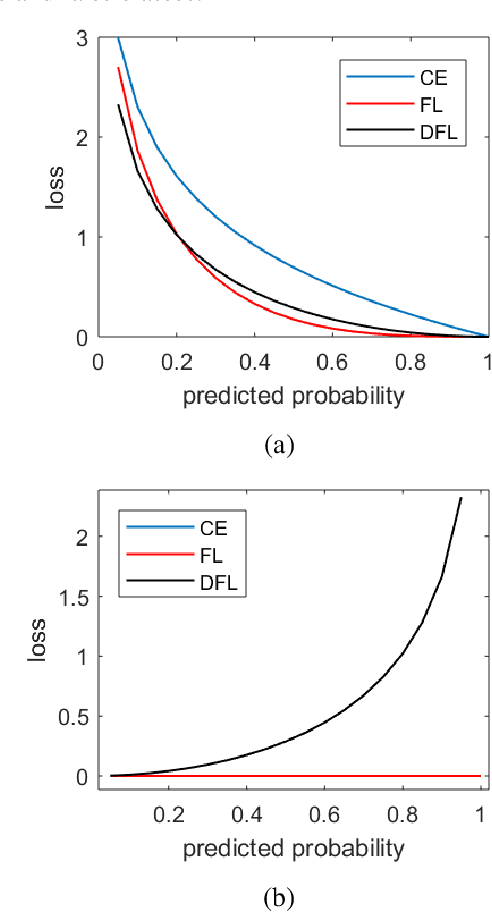
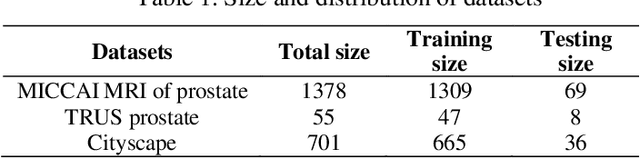
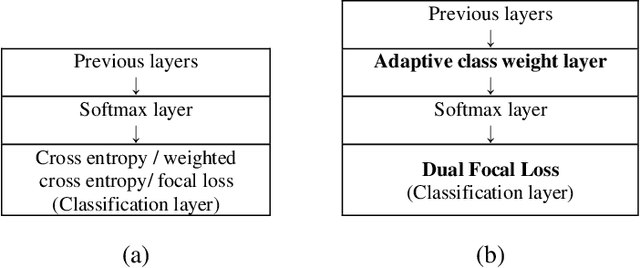

In this paper, we propose a Dual Focal Loss (DFL) function, as a replacement for the standard cross entropy (CE) function to achieve a better treatment of the unbalanced classes in a dataset. Our DFL method is an improvement on the recently reported Focal Loss (FL) cross-entropy function, which proposes a scaling method that puts more weight on the examples that are difficult to classify over those that are easy. However, the scaling parameter of FL is empirically set, which is problem-dependent. In addition, like other CE variants, FL only focuses on the loss of true classes. Therefore, no loss feedback is gained from the false classes. Although focusing only on true examples increases probability on true classes and correspondingly reduces probability on false classes due to the nature of the softmax function, it does not achieve the best convergence due to avoidance of the loss on false classes. Our DFL method improves on the simple FL in two ways. Firstly, it takes the idea of FL to focus more on difficult examples than the easy ones, but evaluates loss on both true and negative classes with equal importance. Secondly, the scaling parameter of DFL has been made learnable so that it can tune itself by backpropagation rather than being dependent on manual tuning. In this way, our proposed DFL method offers an auto-tunable loss function that can reduce the class imbalance effect as well as put more focus on both true difficult examples and negative easy examples. Experimental results show that our proposed method provides better accuracy in every test run conducted over a variety of different network models and datasets.