 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Class Weight based Dual Focal Loss for Improved Semantic Segmentation
Oct 13, 2019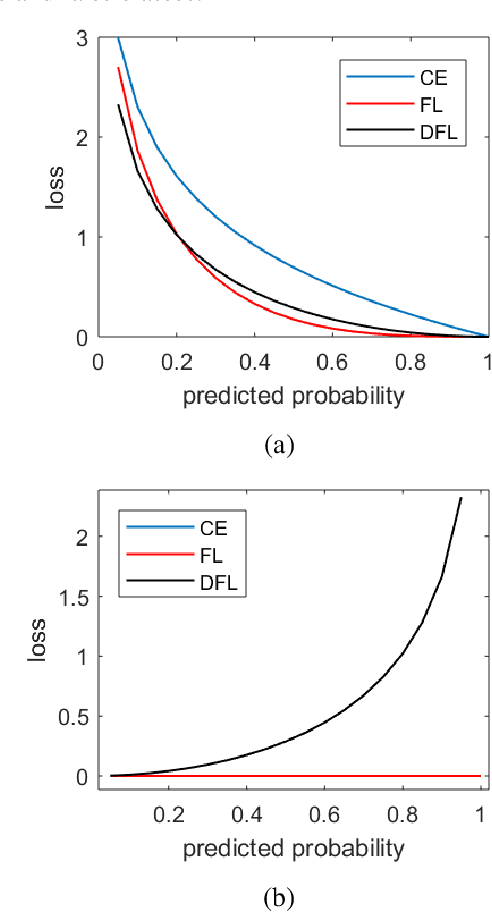
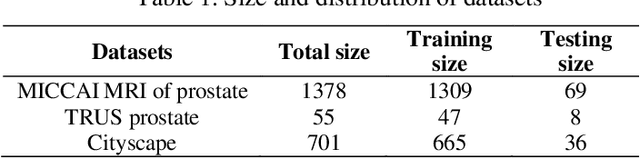
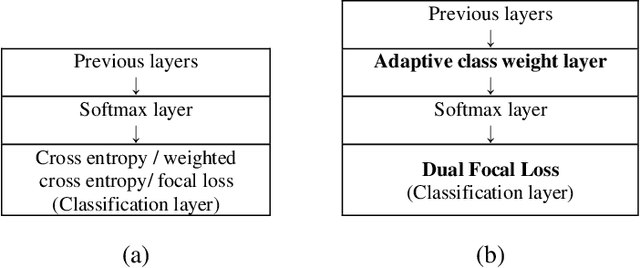

In this paper, we propose a Dual Focal Loss (DFL) function, as a replacement for the standard cross entropy (CE) function to achieve a better treatment of the unbalanced classes in a dataset. Our DFL method is an improvement on the recently reported Focal Loss (FL) cross-entropy function, which proposes a scaling method that puts more weight on the examples that are difficult to classify over those that are easy. However, the scaling parameter of FL is empirically set, which is problem-dependent. In addition, like other CE variants, FL only focuses on the loss of true classes. Therefore, no loss feedback is gained from the false classes. Although focusing only on true examples increases probability on true classes and correspondingly reduces probability on false classes due to the nature of the softmax function, it does not achieve the best convergence due to avoidance of the loss on false classes. Our DFL method improves on the simple FL in two ways. Firstly, it takes the idea of FL to focus more on difficult examples than the easy ones, but evaluates loss on both true and negative classes with equal importance. Secondly, the scaling parameter of DFL has been made learnable so that it can tune itself by backpropagation rather than being dependent on manual tuning. In this way, our proposed DFL method offers an auto-tunable loss function that can reduce the class imbalance effect as well as put more focus on both true difficult examples and negative easy examples. Experimental results show that our proposed method provides better accuracy in every test run conducted over a variety of different network models and datasets.
Semi-Supervised Classification for oil reservoir
Apr 05, 2018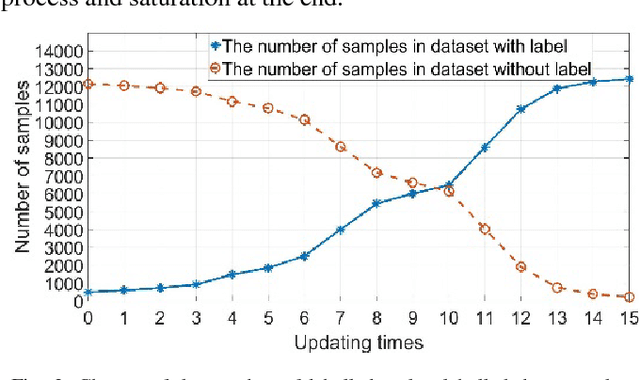
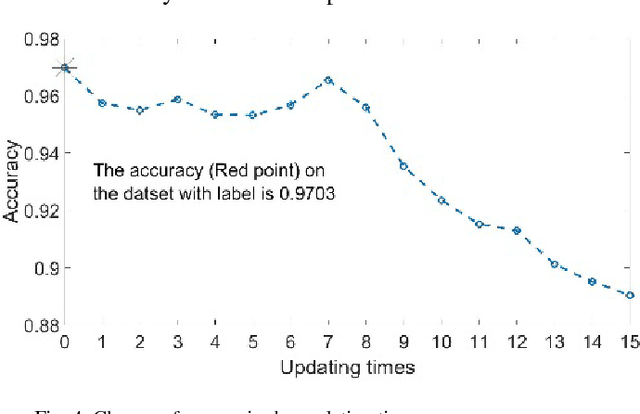
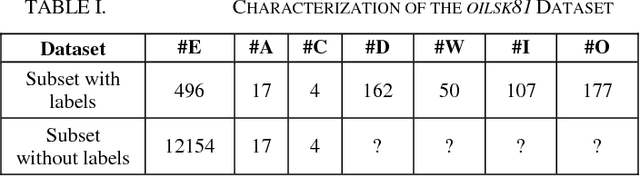
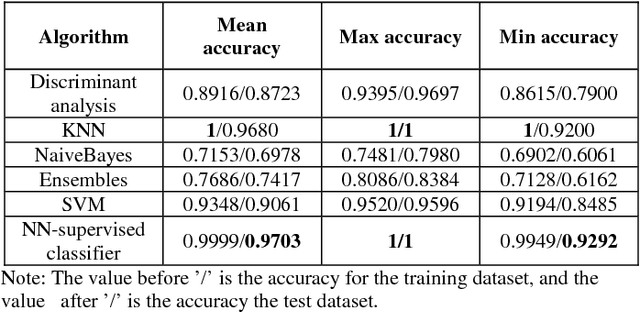
This paper addresses the general problem of accurate identification of oil reservoirs. Recent improvements in well or borehole logging technology have resulted in an explosive amount of data available for processing. The traditional methods of analysis of the logs characteristics by experts require significant amount of time and money and is no longer practicable. In this paper, we use the semi-supervised learning to solve the problem of ever-increasing amount of unlabelled data available for interpretation. The experts are needed to label only a small amount of the log data. The neural network classifier is first trained with the initial labelled data. Next, batches of unlabelled data are being classified and the samples with the very high class probabilities are being used in the next training session, bootstrapping the classifier. The process of training, classifying, enhancing the labelled data is repeated iteratively until the stopping criteria are met, that is, no more high probability samples are found. We make an empirical study on the well data from Jianghan oil field and test the performance of the neural network semi-supervised classifier. We compare this method with other classifiers. The comparison results show that our neural network semi-supervised classifier is superior to other classification methods.