 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-guided Scene Generation for 3D Zero-Shot Learning
Sep 29, 2022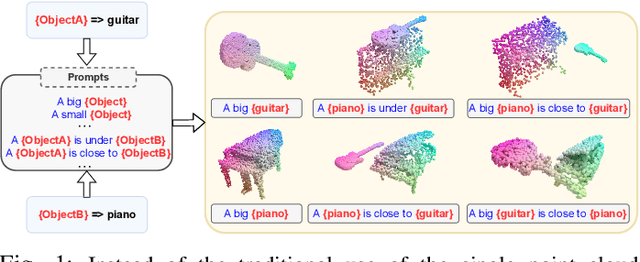
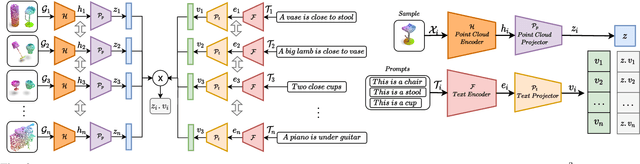
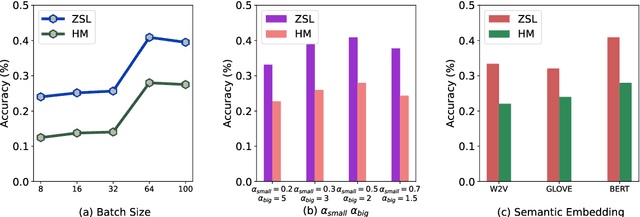

Zero-shot learning on 3D point cloud data is a related underexplored problem compared to its 2D image counterpart. 3D data brings new challenges for ZSL due to the unavailability of robust pre-trained feature extraction models. To address this problem, we propose a prompt-guided 3D scene generation and supervision method that augments 3D data to learn the network better, exploring the complex interplay of seen and unseen objects. First, we merge point clouds of two 3D models in certain ways described by a prompt. The prompt acts like the annotation describing each 3D scene. Later, we perform contrastive learning to train our proposed architecture in an end-to-end manner. We argue that 3D scenes can relate objects more efficiently than single objects because popular language models (like BERT) can achieve high performance when objects appear in a context. Our proposed prompt-guided scene generation method encapsulates data augmentation and prompt-based annotation/captioning to improve 3D ZSL performance. We have achieved state-of-the-art ZSL and generalized ZSL performance on synthetic (ModelNet40, ModelNet10) and real-scanned (ScanOjbectNN) 3D object datasets.