 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapt-As-You-Walk Through the Clouds: Training-Free Online Test-Time Adaptation of 3D Vision-Language Foundation Models
Nov 19, 2025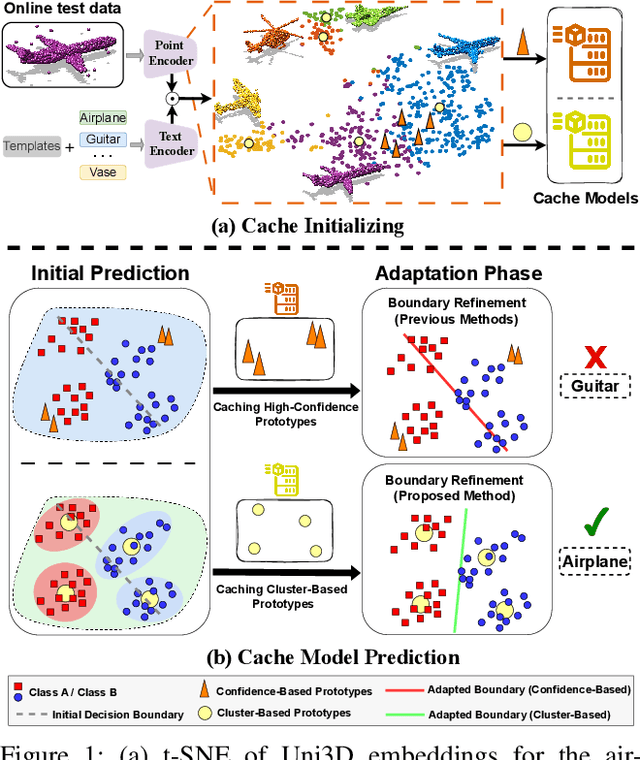
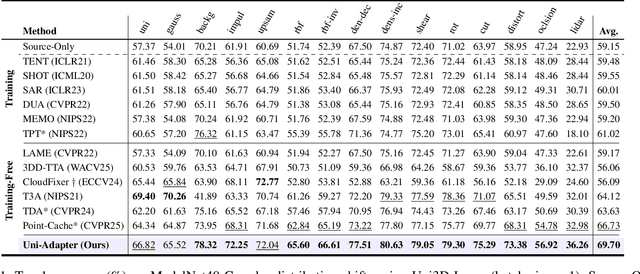
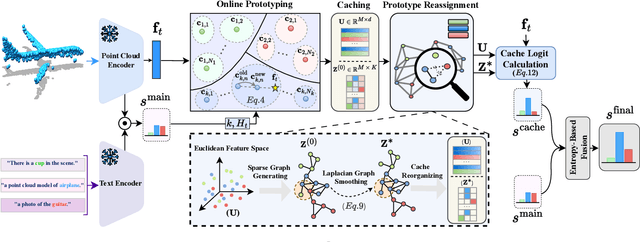
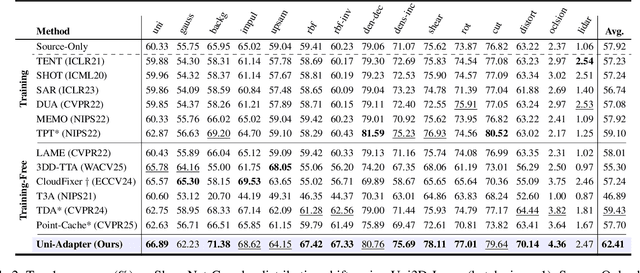
3D Vision-Language Foundation Models (VLFMs) have shown strong generalization and zero-shot recognition capabilities in open-world point cloud processing tasks. However, these models often underperform in practical scenarios where data are noisy, incomplete, or drawn from a different distribution than the training data. To address this, we propose Uni-Adapter, a novel training-free online test-time adaptation (TTA) strategy for 3D VLFMs based on dynamic prototype learning. We define a 3D cache to store class-specific cluster centers as prototypes, which are continuously updated to capture intra-class variability in heterogeneous data distributions. These dynamic prototypes serve as anchors for cache-based logit computation via similarity scoring. Simultaneously, a graph-based label smoothing module captures inter-prototype similarities to enforce label consistency among similar prototypes. Finally, we unify predictions from the original 3D VLFM and the refined 3D cache using entropy-weighted aggregation for reliable adaptation. Without retraining, Uni-Adapter effectively mitigates distribution shifts, achieving state-of-the-art performance on diverse 3D benchmarks over different 3D VLFMs, improving ModelNet-40C by 10.55%, ScanObjectNN-C by 8.26%, and ShapeNet-C by 4.49% over the source 3D VLFMs.
RAG/LLM Augmented Switching Driven Polymorphic Metaheuristic Framework
May 20, 2025



Metaheuristic algorithms are widely used for solving complex optimization problems, yet their effectiveness is often constrained by fixed structures and the need for extensive tuning. The Polymorphic Metaheuristic Framework (PMF) addresses this limitation by introducing a self-adaptive metaheuristic switching mechanism driven by real-time performance feedback and dynamic algorithmic selection. PMF leverages the Polymorphic Metaheuristic Agent (PMA) and the Polymorphic Metaheuristic Selection Agent (PMSA) to dynamically select and transition between metaheuristic algorithms based on key performance indicators, ensuring continuous adaptation. This approach enhances convergence speed, adaptability, and solution quality, outperforming traditional metaheuristics in high-dimensional, dynamic, and multimodal environments. Experimental results on benchmark functions demonstrate that PMF significantly improves optimization efficiency by mitigating stagnation and balancing exploration-exploitation strategies across various problem landscapes. By integrating AI-driven decision-making and self-correcting mechanisms, PMF paves the way for scalable, intelligent, and autonomous optimization frameworks, with promising applications in engineering, logistics, and complex decision-making systems.
Foundation Model-Powered 3D Few-Shot Class Incremental Learning via Training-free Adaptor
Oct 11, 2024Recent advances in deep learning for processing point clouds hold increased interest in Few-Shot Class Incremental Learning (FSCIL) for 3D computer vision. This paper introduces a new method to tackle the Few-Shot Continual Incremental Learning (FSCIL) problem in 3D point cloud environments. We leverage a foundational 3D model trained extensively on point cloud data. Drawing from recent improvements in foundation models, known for their ability to work well across different tasks, we propose a novel strategy that does not require additional training to adapt to new tasks. Our approach uses a dual cache system: first, it uses previous test samples based on how confident the model was in its predictions to prevent forgetting, and second, it includes a small number of new task samples to prevent overfitting. This dynamic adaptation ensures strong performance across different learning tasks without needing lots of fine-tuning. We tested our approach on datasets like ModelNet, ShapeNet, ScanObjectNN, and CO3D, showing that it outperforms other FSCIL methods and demonstrating its effectiveness and versatility. The code is available at \url{https://github.com/ahmadisahar/ACCV_FCIL3D}.
An Investigation of Hepatitis B Virus Genome using Markov Models
Nov 12, 2023
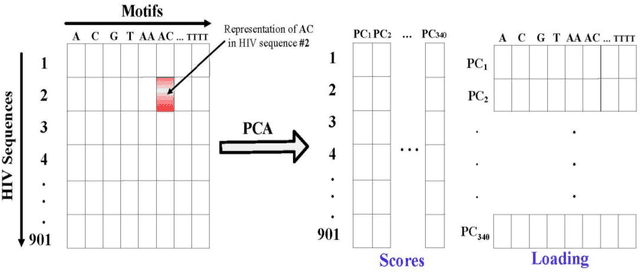
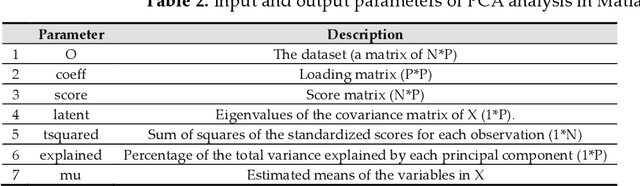
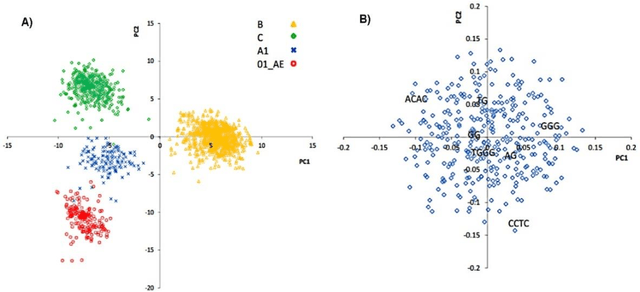
The human genome encodes a family of editing enzymes known as APOBEC3 (apolipoprotein B mRNA editing enzyme, catalytic polypeptide-like 3). Several family members, such as APO-BEC3G, APOBEC3F, and APOBEC3H haplotype II, exhibit activity against viruses such as HIV. These enzymes induce C-to-U mutations in the negative strand of viral genomes, resulting in multiple G-to-A changes, commonly referred to as 'hypermutation.' Mutations catalyzed by these enzymes are sequence context-dependent in the HIV genome; for instance, APOBEC3G preferen-tially mutates G within GG, TGG, and TGGG contexts, while other members mutate G within GA, TGA, and TGAA contexts. However, the same sequence context has not been explored in relation to these enzymes and HBV. In this study, our objective is to identify the mutational footprint of APOBEC3 enzymes in the HBV genome. To achieve this, we employ a multivariable data analytics technique to investigate motif preferences and potential sequence hierarchies of mutation by APOBEC3 enzymes using full genome HBV sequences from a diverse range of naturally infected patients. This approach allows us to distinguish between normal and hypermutated sequences based on the representation of mono- to tetra-nucleotide motifs. Additionally, we aim to identify motifs associated with hypermutation induced by different APOBEC3 enzymes in HBV genomes. Our analyses reveal that either APOBEC3 enzymes are not active against HBV, or the induction of G-to-A mutations by these enzymes is not sequence context-dependent in the HBV genome.
ChatGPT-guided Semantics for Zero-shot Learning
Oct 18, 2023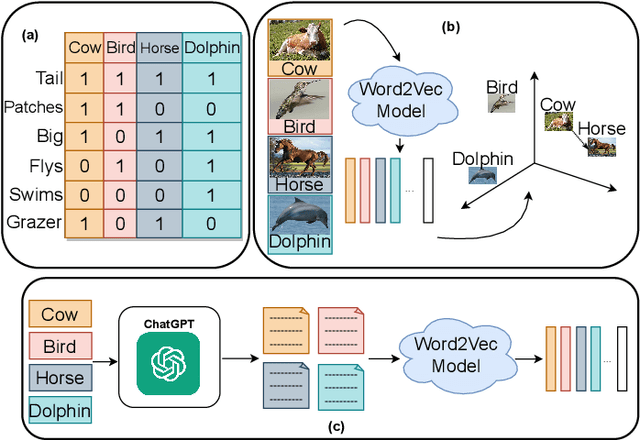
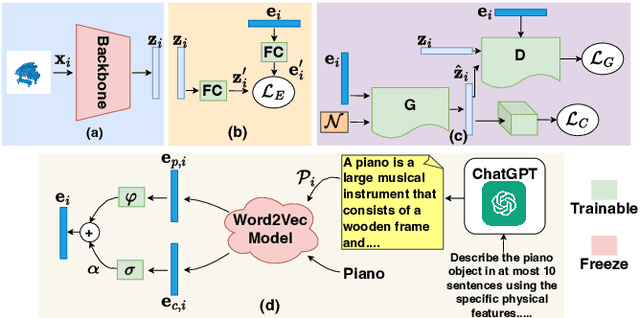
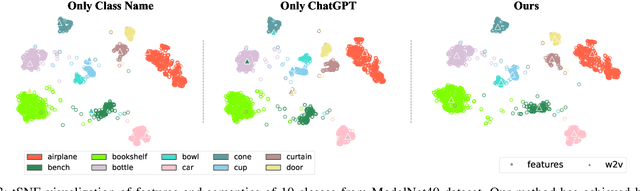
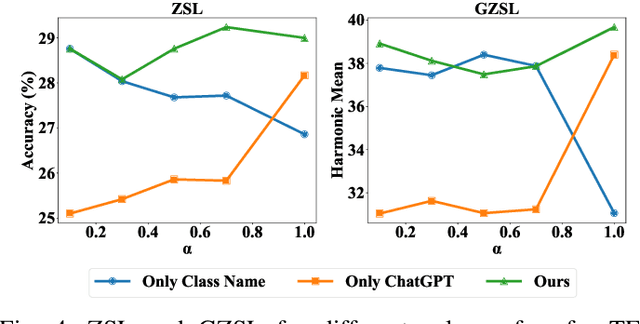
Zero-shot learning (ZSL) aims to classify objects that are not observed or seen during training. It relies on class semantic description to transfer knowledge from the seen classes to the unseen classes. Existing methods of obtaining class semantics include manual attributes or automatic word vectors from language models (like word2vec). We know attribute annotation is costly, whereas automatic word-vectors are relatively noisy. To address this problem, we explore how ChatGPT, a large language model, can enhance class semantics for ZSL tasks. ChatGPT can be a helpful source to obtain text descriptions for each class containing related attributes and semantics. We use the word2vec model to get a word vector using the texts from ChatGPT. Then, we enrich word vectors by combining the word embeddings from class names and descriptions generated by ChatGPT. More specifically, we leverage ChatGPT to provide extra supervision for the class description, eventually benefiting ZSL models. We evaluate our approach on various 2D image (CUB and AwA) and 3D point cloud (ModelNet10, ModelNet40, and ScanObjectNN) datasets and show that it improves ZSL performance. Our work contributes to the ZSL literature by applying ChatGPT for class semantics enhancement and proposing a novel word vector fusion method.
Prompt-guided Scene Generation for 3D Zero-Shot Learning
Sep 29, 2022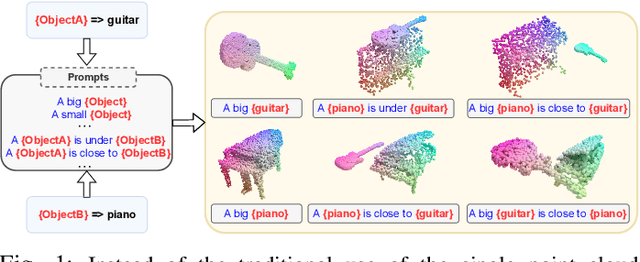
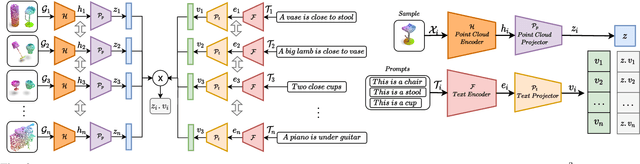
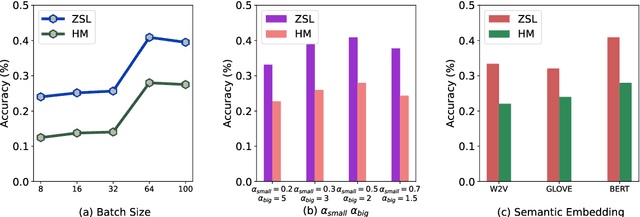

Zero-shot learning on 3D point cloud data is a related underexplored problem compared to its 2D image counterpart. 3D data brings new challenges for ZSL due to the unavailability of robust pre-trained feature extraction models. To address this problem, we propose a prompt-guided 3D scene generation and supervision method that augments 3D data to learn the network better, exploring the complex interplay of seen and unseen objects. First, we merge point clouds of two 3D models in certain ways described by a prompt. The prompt acts like the annotation describing each 3D scene. Later, we perform contrastive learning to train our proposed architecture in an end-to-end manner. We argue that 3D scenes can relate objects more efficiently than single objects because popular language models (like BERT) can achieve high performance when objects appear in a context. Our proposed prompt-guided scene generation method encapsulates data augmentation and prompt-based annotation/captioning to improve 3D ZSL performance. We have achieved state-of-the-art ZSL and generalized ZSL performance on synthetic (ModelNet40, ModelNet10) and real-scanned (ScanOjbectNN) 3D object datasets.
Few-shot Class-incremental Learning for 3D Point Cloud Objects
May 30, 2022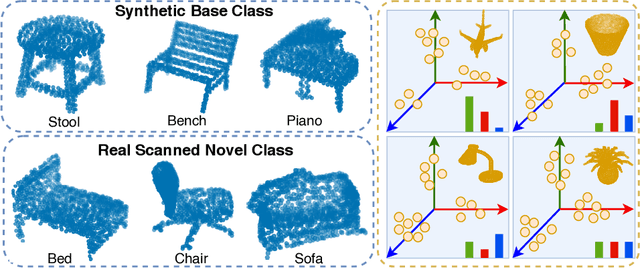
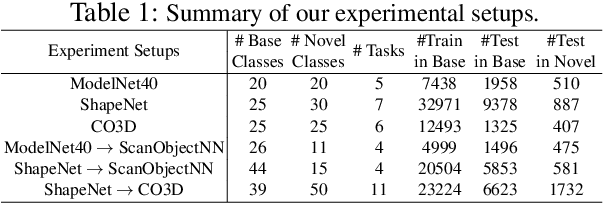

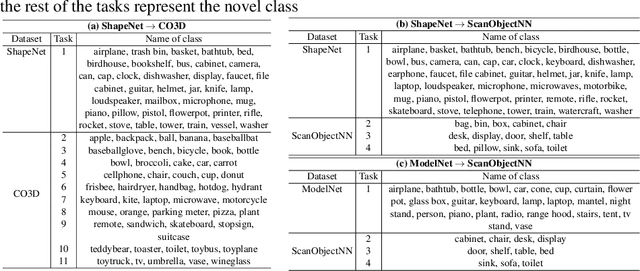
Few-shot class-incremental learning (FSCIL) aims to incrementally fine-tune a model trained on base classes for a novel set of classes using a few examples without forgetting the previous training. Recent efforts of FSCIL address this problem primarily on 2D image data. However, due to the advancement of camera technology, 3D point cloud data has become more available than ever, which warrants considering FSCIL on 3D data. In this paper, we address FSCIL in the 3D domain. In addition to well-known problems of catastrophic forgetting of past knowledge and overfitting of few-shot data, 3D FSCIL can bring newer challenges. For example, base classes may contain many synthetic instances in a realistic scenario. In contrast, only a few real-scanned samples (from RGBD sensors) of novel classes are available in incremental steps. Due to the data variation from synthetic to real, FSCIL endures additional challenges, degrading performance in later incremental steps. We attempt to solve this problem by using Microshapes (orthogonal basis vectors) describing any 3D objects using a pre-defined set of rules. It supports incremental training with few-shot examples minimizing synthetic to real data variation. We propose new test protocols for 3D FSCIL using popular synthetic datasets, ModelNet and ShapeNet, and 3D real-scanned datasets, ScanObjectNN, and Common Objects in 3D (CO3D). By comparing state-of-the-art methods, we establish the effectiveness of our approach in the 3D domain.