 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation of Hepatitis B Virus Genome using Markov Models
Nov 12, 2023
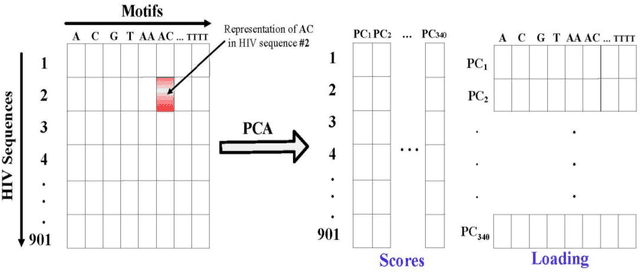
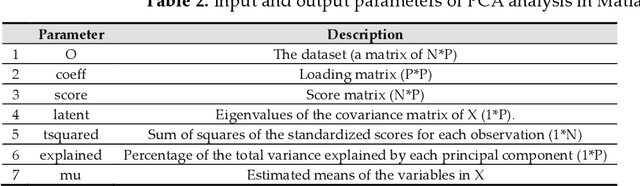
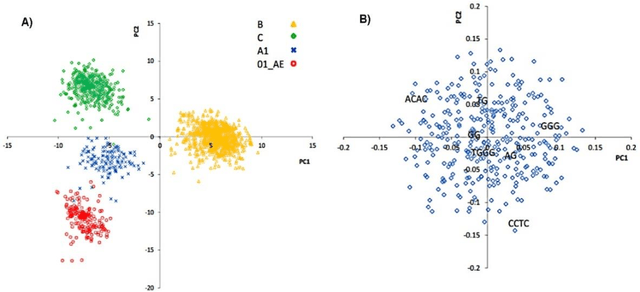
The human genome encodes a family of editing enzymes known as APOBEC3 (apolipoprotein B mRNA editing enzyme, catalytic polypeptide-like 3). Several family members, such as APO-BEC3G, APOBEC3F, and APOBEC3H haplotype II, exhibit activity against viruses such as HIV. These enzymes induce C-to-U mutations in the negative strand of viral genomes, resulting in multiple G-to-A changes, commonly referred to as 'hypermutation.' Mutations catalyzed by these enzymes are sequence context-dependent in the HIV genome; for instance, APOBEC3G preferen-tially mutates G within GG, TGG, and TGGG contexts, while other members mutate G within GA, TGA, and TGAA contexts. However, the same sequence context has not been explored in relation to these enzymes and HBV. In this study, our objective is to identify the mutational footprint of APOBEC3 enzymes in the HBV genome. To achieve this, we employ a multivariable data analytics technique to investigate motif preferences and potential sequence hierarchies of mutation by APOBEC3 enzymes using full genome HBV sequences from a diverse range of naturally infected patients. This approach allows us to distinguish between normal and hypermutated sequences based on the representation of mono- to tetra-nucleotide motifs. Additionally, we aim to identify motifs associated with hypermutation induced by different APOBEC3 enzymes in HBV genomes. Our analyses reveal that either APOBEC3 enzymes are not active against HBV, or the induction of G-to-A mutations by these enzymes is not sequence context-dependent in the HBV genome.
Revolutionizing Genomics with Reinforcement Learning Techniques
Feb 26, 2023



In recent years, Reinforcement Learning (RL) has emerged as a powerful tool for solving a wide range of problems, including decision-making and genomics. The exponential growth of raw genomic data over the past two decades has exceeded the capacity of manual analysis, leading to a growing interest in automatic data analysis and processing. RL algorithms are capable of learning from experience with minimal human supervision, making them well-suited for genomic data analysis and interpretation. One of the key benefits of using RL is the reduced cost associated with collecting labeled training data, which is required for supervised learning. While there have been numerous studies examining the applications of Machine Learning (ML) in genomics, this survey focuses exclusively on the use of RL in various genomics research fields, including gene regulatory networks (GRNs), genome assembly, and sequence alignment. We present a comprehensive technical overview of existing studies on the application of RL in genomics, highlighting the strengths and limitations of these approaches. We then discuss potential research directions that are worthy of future exploration, including the development of more sophisticated reward functions as RL heavily depends on the accuracy of the reward function, the integration of RL with other machine learning techniques, and the application of RL to new and emerging areas in genomics research. Finally, we present our findings and conclude by summarizing the current state of the field and the future outlook for RL in genomics.