 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Model-Powered 3D Few-Shot Class Incremental Learning via Training-free Adaptor
Oct 11, 2024Recent advances in deep learning for processing point clouds hold increased interest in Few-Shot Class Incremental Learning (FSCIL) for 3D computer vision. This paper introduces a new method to tackle the Few-Shot Continual Incremental Learning (FSCIL) problem in 3D point cloud environments. We leverage a foundational 3D model trained extensively on point cloud data. Drawing from recent improvements in foundation models, known for their ability to work well across different tasks, we propose a novel strategy that does not require additional training to adapt to new tasks. Our approach uses a dual cache system: first, it uses previous test samples based on how confident the model was in its predictions to prevent forgetting, and second, it includes a small number of new task samples to prevent overfitting. This dynamic adaptation ensures strong performance across different learning tasks without needing lots of fine-tuning. We tested our approach on datasets like ModelNet, ShapeNet, ScanObjectNN, and CO3D, showing that it outperforms other FSCIL methods and demonstrating its effectiveness and versatility. The code is available at \url{https://github.com/ahmadisahar/ACCV_FCIL3D}.
Prompt-guided Scene Generation for 3D Zero-Shot Learning
Sep 29, 2022

Zero-shot learning on 3D point cloud data is a related underexplored problem compared to its 2D image counterpart. 3D data brings new challenges for ZSL due to the unavailability of robust pre-trained feature extraction models. To address this problem, we propose a prompt-guided 3D scene generation and supervision method that augments 3D data to learn the network better, exploring the complex interplay of seen and unseen objects. First, we merge point clouds of two 3D models in certain ways described by a prompt. The prompt acts like the annotation describing each 3D scene. Later, we perform contrastive learning to train our proposed architecture in an end-to-end manner. We argue that 3D scenes can relate objects more efficiently than single objects because popular language models (like BERT) can achieve high performance when objects appear in a context. Our proposed prompt-guided scene generation method encapsulates data augmentation and prompt-based annotation/captioning to improve 3D ZSL performance. We have achieved state-of-the-art ZSL and generalized ZSL performance on synthetic (ModelNet40, ModelNet10) and real-scanned (ScanOjbectNN) 3D object datasets.
Few-shot Class-incremental Learning for 3D Point Cloud Objects
May 30, 2022
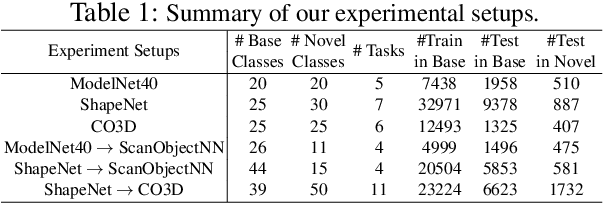

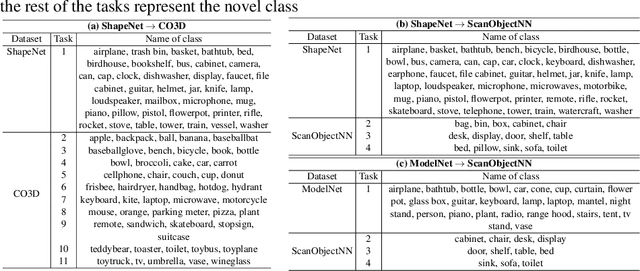
Few-shot class-incremental learning (FSCIL) aims to incrementally fine-tune a model trained on base classes for a novel set of classes using a few examples without forgetting the previous training. Recent efforts of FSCIL address this problem primarily on 2D image data. However, due to the advancement of camera technology, 3D point cloud data has become more available than ever, which warrants considering FSCIL on 3D data. In this paper, we address FSCIL in the 3D domain. In addition to well-known problems of catastrophic forgetting of past knowledge and overfitting of few-shot data, 3D FSCIL can bring newer challenges. For example, base classes may contain many synthetic instances in a realistic scenario. In contrast, only a few real-scanned samples (from RGBD sensors) of novel classes are available in incremental steps. Due to the data variation from synthetic to real, FSCIL endures additional challenges, degrading performance in later incremental steps. We attempt to solve this problem by using Microshapes (orthogonal basis vectors) describing any 3D objects using a pre-defined set of rules. It supports incremental training with few-shot examples minimizing synthetic to real data variation. We propose new test protocols for 3D FSCIL using popular synthetic datasets, ModelNet and ShapeNet, and 3D real-scanned datasets, ScanObjectNN, and Common Objects in 3D (CO3D). By comparing state-of-the-art methods, we establish the effectiveness of our approach in the 3D domain.