 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoCap: Video Object Captioning and Segmentation from Any Prompt
Aug 29, 2025Understanding objects in videos in terms of fine-grained localization masks and detailed semantic properties is a fundamental task in video understanding. In this paper, we propose VoCap, a flexible video model that consumes a video and a prompt of various modalities (text, box or mask), and produces a spatio-temporal masklet with a corresponding object-centric caption. As such our model addresses simultaneously the tasks of promptable video object segmentation, referring expression segmentation, and object captioning. Since obtaining data for this task is tedious and expensive, we propose to annotate an existing large-scale segmentation dataset (SAV) with pseudo object captions. We do so by preprocessing videos with their ground-truth masks to highlight the object of interest and feed this to a large Vision Language Model (VLM). For an unbiased evaluation, we collect manual annotations on the validation set. We call the resulting dataset SAV-Caption. We train our VoCap model at scale on a SAV-Caption together with a mix of other image and video datasets. Our model yields state-of-the-art results on referring expression video object segmentation, is competitive on semi-supervised video object segmentation, and establishes a benchmark for video object captioning. Our dataset will be made available at https://github.com/google-deepmind/vocap.
MALT Diffusion: Memory-Augmented Latent Transformers for Any-Length Video Generation
Feb 18, 2025Diffusion models are successful for synthesizing high-quality videos but are limited to generating short clips (e.g., 2-10 seconds). Synthesizing sustained footage (e.g. over minutes) still remains an open research question. In this paper, we propose MALT Diffusion (using Memory-Augmented Latent Transformers), a new diffusion model specialized for long video generation. MALT Diffusion (or just MALT) handles long videos by subdividing them into short segments and doing segment-level autoregressive generation. To achieve this, we first propose recurrent attention layers that encode multiple segments into a compact memory latent vector; by maintaining this memory vector over time, MALT is able to condition on it and continuously generate new footage based on a long temporal context. We also present several training techniques that enable the model to generate frames over a long horizon with consistent quality and minimal degradation. We validate the effectiveness of MALT through experiments on long video benchmarks. We first perform extensive analysis of MALT in long-contextual understanding capability and stability using popular long video benchmarks. For example, MALT achieves an FVD score of 220.4 on 128-frame video generation on UCF-101, outperforming the previous state-of-the-art of 648.4. Finally, we explore MALT's capabilities in a text-to-video generation setting and show that it can produce long videos compared with recent techniques for long text-to-video generation.
CAPE: CAM as a Probabilistic Ensemble for Enhanced DNN Interpretation
Apr 04, 2024Deep Neural Networks (DNNs) are widely used for visual classification tasks, but their complex computation process and black-box nature hinder decision transparency and interpretability. Class activation maps (CAMs) and recent variants provide ways to visually explain the DNN decision-making process by displaying 'attention' heatmaps of the DNNs. Nevertheless, the CAM explanation only offers relative attention information, that is, on an attention heatmap, we can interpret which image region is more or less important than the others. However, these regions cannot be meaningfully compared across classes, and the contribution of each region to the model's class prediction is not revealed. To address these challenges that ultimately lead to better DNN Interpretation, in this paper, we propose CAPE, a novel reformulation of CAM that provides a unified and probabilistically meaningful assessment of the contributions of image regions. We quantitatively and qualitatively compare CAPE with state-of-the-art CAM methods on CUB and ImageNet benchmark datasets to demonstrate enhanced interpretability. We also test on a cytology imaging dataset depicting a challenging Chronic Myelomonocytic Leukemia (CMML) diagnosis problem. Code is available at: https://github.com/AIML-MED/CAPE.
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Dec 21, 2023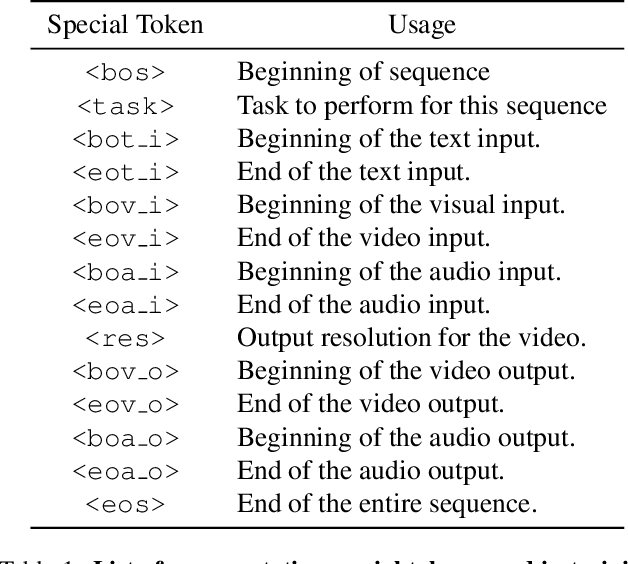



We present VideoPoet, a language model capable of synthesizing high-quality video, with matching audio, from a large variety of conditioning signals. VideoPoet employs a decoder-only transformer architecture that processes multimodal inputs -- including images, videos, text, and audio. The training protocol follows that of Large Language Models (LLMs), consisting of two stages: pretraining and task-specific adaptation. During pretraining, VideoPoet incorporates a mixture of multimodal generative objectives within an autoregressive Transformer framework. The pretrained LLM serves as a foundation that can be adapted for a range of video generation tasks. We present empirical results demonstrating the model's state-of-the-art capabilities in zero-shot video generation, specifically highlighting VideoPoet's ability to generate high-fidelity motions. Project page: http://sites.research.google/videopoet/
UnLoc: A Unified Framework for Video Localization Tasks
Aug 21, 2023



While large-scale image-text pretrained models such as CLIP have been used for multiple video-level tasks on trimmed videos, their use for temporal localization in untrimmed videos is still a relatively unexplored task. We design a new approach for this called UnLoc, which uses pretrained image and text towers, and feeds tokens to a video-text fusion model. The output of the fusion module are then used to construct a feature pyramid in which each level connects to a head to predict a per-frame relevancy score and start/end time displacements. Unlike previous works, our architecture enables Moment Retrieval, Temporal Localization, and Action Segmentation with a single stage model, without the need for action proposals, motion based pretrained features or representation masking. Unlike specialized models, we achieve state of the art results on all three different localization tasks with a unified approach. Code will be available at: \url{https://github.com/google-research/scenic}.
im2nerf: Image to Neural Radiance Field in the Wild
Sep 08, 2022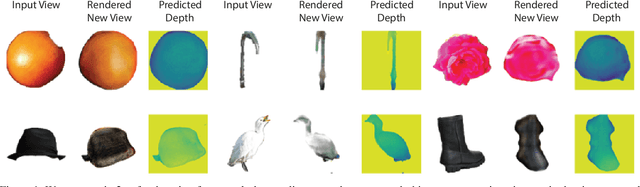
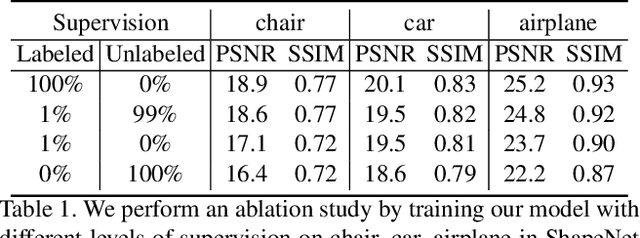
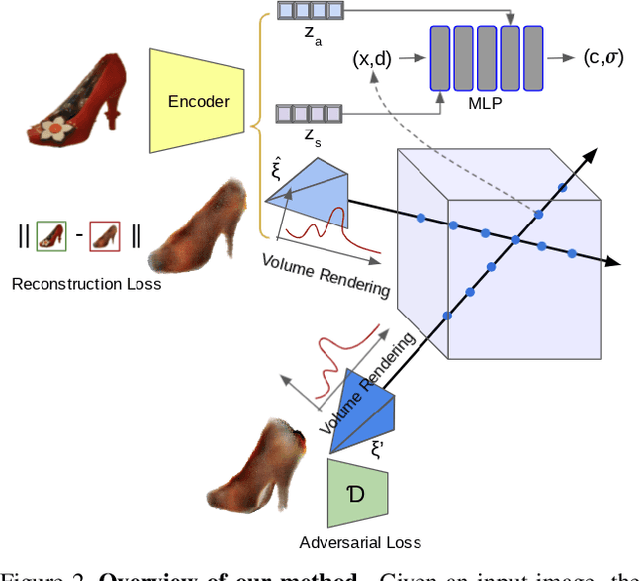
We propose im2nerf, a learning framework that predicts a continuous neural object representation given a single input image in the wild, supervised by only segmentation output from off-the-shelf recognition methods. The standard approach to constructing neural radiance fields takes advantage of multi-view consistency and requires many calibrated views of a scene, a requirement that cannot be satisfied when learning on large-scale image data in the wild. We take a step towards addressing this shortcoming by introducing a model that encodes the input image into a disentangled object representation that contains a code for object shape, a code for object appearance, and an estimated camera pose from which the object image is captured. Our model conditions a NeRF on the predicted object representation and uses volume rendering to generate images from novel views. We train the model end-to-end on a large collection of input images. As the model is only provided with single-view images, the problem is highly under-constrained. Therefore, in addition to using a reconstruction loss on the synthesized input view, we use an auxiliary adversarial loss on the novel rendered views. Furthermore, we leverage object symmetry and cycle camera pose consistency. We conduct extensive quantitative and qualitative experiments on the ShapeNet dataset as well as qualitative experiments on Open Images dataset. We show that in all cases, im2nerf achieves the state-of-the-art performance for novel view synthesis from a single-view unposed image in the wild.
Optical Mouse: 3D Mouse Pose From Single-View Video
Jun 17, 2021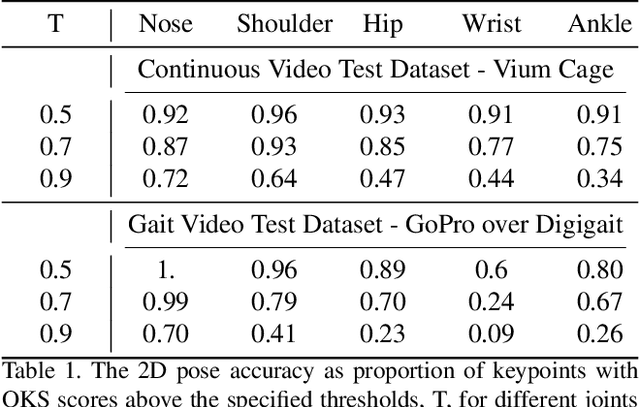

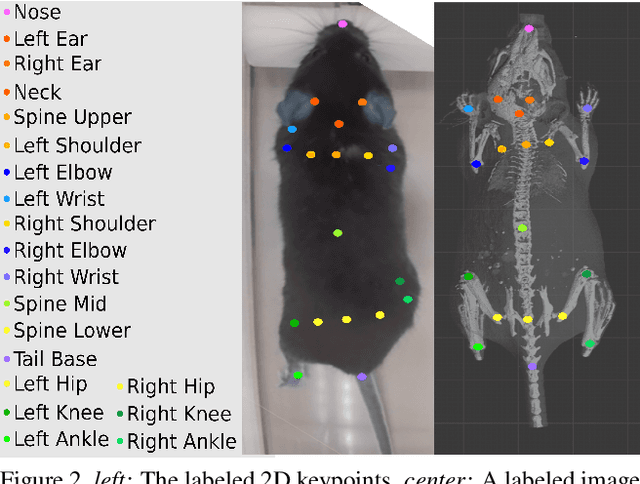
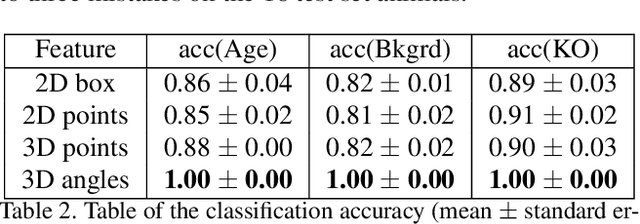
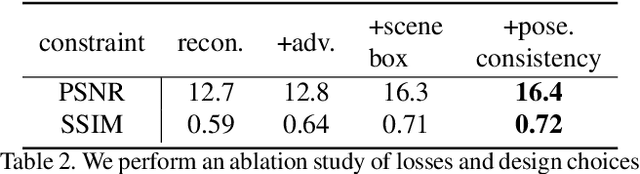
We present a method to infer the 3D pose of mice, including the limbs and feet, from monocular videos. Many human clinical conditions and their corresponding animal models result in abnormal motion, and accurately measuring 3D motion at scale offers insights into health. The 3D poses improve classification of health-related attributes over 2D representations. The inferred poses are accurate enough to estimate stride length even when the feet are mostly occluded. This method could be applied as part of a continuous monitoring system to non-invasively measure animal health.
Pillar-based Object Detection for Autonomous Driving
Jul 26, 2020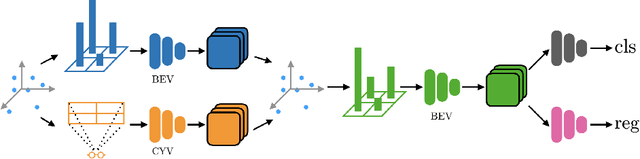
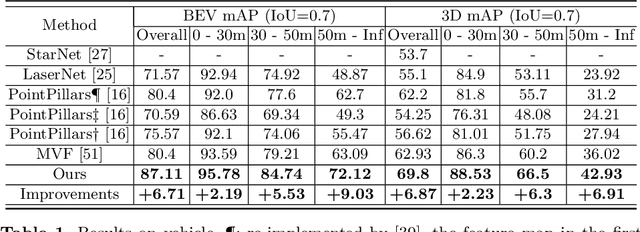
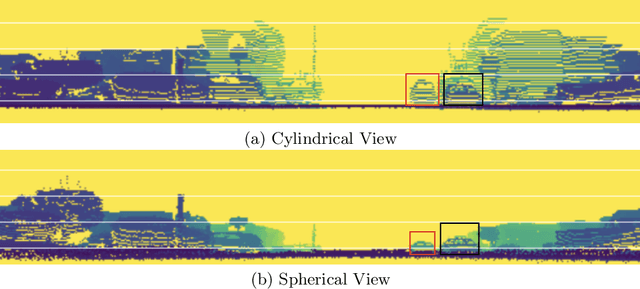
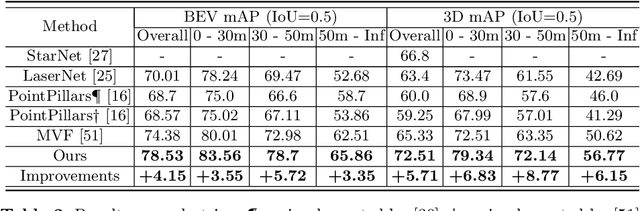
We present a simple and flexible object detection framework optimized for autonomous driving. Building on the observation that point clouds in this application are extremely sparse, we propose a practical pillar-based approach to fix the imbalance issue caused by anchors. In particular, our algorithm incorporates a cylindrical projection into multi-view feature learning, predicts bounding box parameters per pillar rather than per point or per anchor, and includes an aligned pillar-to-point projection module to improve the final prediction. Our anchor-free approach avoids hyperparameter search associated with past methods, simplifying 3D object detection while significantly improving upon state-of-the-art.
Virtual Multi-view Fusion for 3D Semantic Segmentation
Jul 26, 2020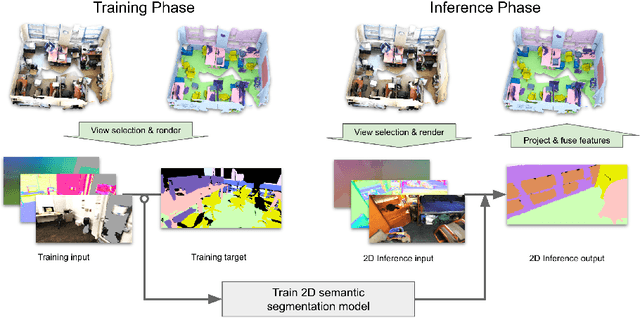
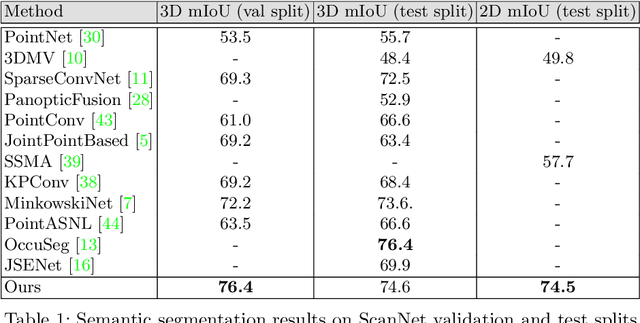
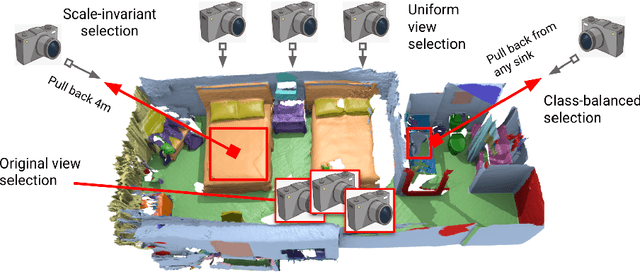
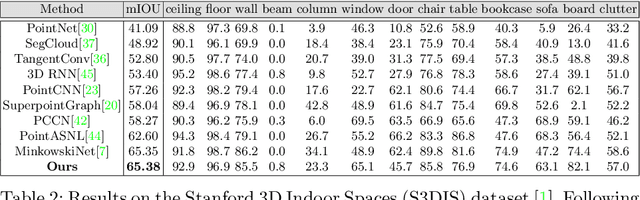
Semantic segmentation of 3D meshes is an important problem for 3D scene understanding. In this paper we revisit the classic multiview representation of 3D meshes and study several techniques that make them effective for 3D semantic segmentation of meshes. Given a 3D mesh reconstructed from RGBD sensors, our method effectively chooses different virtual views of the 3D mesh and renders multiple 2D channels for training an effective 2D semantic segmentation model. Features from multiple per view predictions are finally fused on 3D mesh vertices to predict mesh semantic segmentation labels. Using the large scale indoor 3D semantic segmentation benchmark of ScanNet, we show that our virtual views enable more effective training of 2D semantic segmentation networks than previous multiview approaches. When the 2D per pixel predictions are aggregated on 3D surfaces, our virtual multiview fusion method is able to achieve significantly better 3D semantic segmentation results compared to all prior multiview approaches and competitive with recent 3D convolution approaches.
DOPS: Learning to Detect 3D Objects and Predict their 3D Shapes
Apr 07, 2020
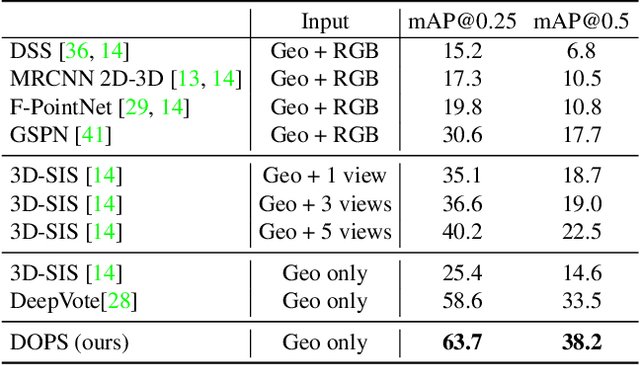
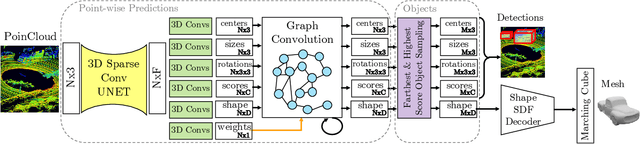
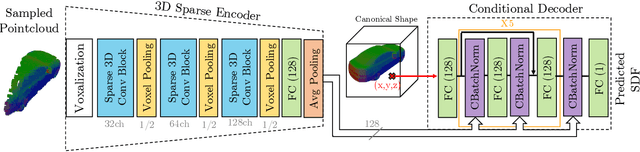
We propose DOPS, a fast single-stage 3D object detection method for LIDAR data. Previous methods often make domain-specific design decisions, for example projecting points into a bird-eye view image in autonomous driving scenarios. In contrast, we propose a general-purpose method that works on both indoor and outdoor scenes. The core novelty of our method is a fast, single-pass architecture that both detects objects in 3D and estimates their shapes. 3D bounding box parameters are estimated in one pass for every point, aggregated through graph convolutions, and fed into a branch of the network that predicts latent codes representing the shape of each detected object. The latent shape space and shape decoder are learned on a synthetic dataset and then used as supervision for the end-to-end training of the 3D object detection pipeline. Thus our model is able to extract shapes without access to ground-truth shape information in the target dataset. During experiments, we find that our proposed method achieves state-of-the-art results by ~5% on object detection in ScanNet scenes, and it gets top results by 3.4% in the Waymo Open Dataset, while reproducing the shapes of detected cars.