 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximation Algorithm for Constrained $k$-Center Clustering: A Local Search Approach
Jan 17, 2026Clustering is a long-standing research problem and a fundamental tool in AI and data analysis. The traditional k-center problem, a fundamental theoretical challenge in clustering, has a best possible approximation ratio of 2, and any improvement to a ratio of 2 - ε would imply P = NP. In this work, we study the constrained k-center clustering problem, where instance-level cannot-link (CL) and must-link (ML) constraints are incorporated as background knowledge. Although general CL constraints significantly increase the hardness of approximation, previous work has shown that disjoint CL sets permit constant-factor approximations. However, whether local search can achieve such a guarantee in this setting remains an open question. To this end, we propose a novel local search framework based on a transformation to a dominating matching set problem, achieving the best possible approximation ratio of 2. The experimental results on both real-world and synthetic datasets demonstrate that our algorithm outperforms baselines in solution quality.
TED++: Submanifold-Aware Backdoor Detection via Layerwise Tubular-Neighbourhood Screening
Oct 16, 2025As deep neural networks power increasingly critical applications, stealthy backdoor attacks, where poisoned training inputs trigger malicious model behaviour while appearing benign, pose a severe security risk. Many existing defences are vulnerable when attackers exploit subtle distance-based anomalies or when clean examples are scarce. To meet this challenge, we introduce TED++, a submanifold-aware framework that effectively detects subtle backdoors that evade existing defences. TED++ begins by constructing a tubular neighbourhood around each class's hidden-feature manifold, estimating its local ``thickness'' from a handful of clean activations. It then applies Locally Adaptive Ranking (LAR) to detect any activation that drifts outside the admissible tube. By aggregating these LAR-adjusted ranks across all layers, TED++ captures how faithfully an input remains on the evolving class submanifolds. Based on such characteristic ``tube-constrained'' behaviour, TED++ flags inputs whose LAR-based ranking sequences deviate significantly. Extensive experiments are conducted on benchmark datasets and tasks, demonstrating that TED++ achieves state-of-the-art detection performance under both adaptive-attack and limited-data scenarios. Remarkably, even with only five held-out examples per class, TED++ still delivers near-perfect detection, achieving gains of up to 14\% in AUROC over the next-best method. The code is publicly available at https://github.com/namle-w/TEDpp.
AdaCBM: An Adaptive Concept Bottleneck Model for Explainable and Accurate Diagnosis
Aug 04, 2024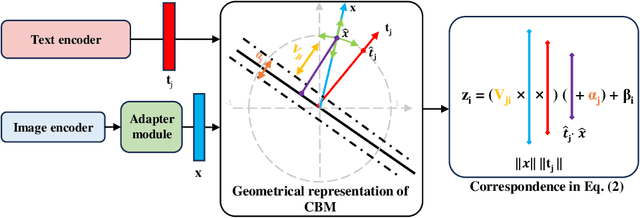
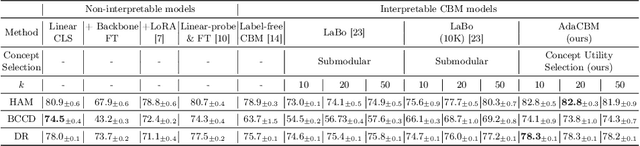

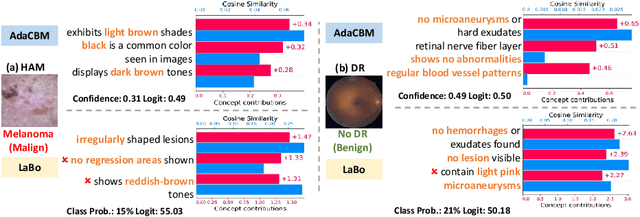
The integration of vision-language models such as CLIP and Concept Bottleneck Models (CBMs) offers a promising approach to explaining deep neural network (DNN) decisions using concepts understandable by humans, addressing the black-box concern of DNNs. While CLIP provides both explainability and zero-shot classification capability, its pre-training on generic image and text data may limit its classification accuracy and applicability to medical image diagnostic tasks, creating a transfer learning problem. To maintain explainability and address transfer learning needs, CBM methods commonly design post-processing modules after the bottleneck module. However, this way has been ineffective. This paper takes an unconventional approach by re-examining the CBM framework through the lens of its geometrical representation as a simple linear classification system. The analysis uncovers that post-CBM fine-tuning modules merely rescale and shift the classification outcome of the system, failing to fully leverage the system's learning potential. We introduce an adaptive module strategically positioned between CLIP and CBM to bridge the gap between source and downstream domains. This simple yet effective approach enhances classification performance while preserving the explainability afforded by the framework. Our work offers a comprehensive solution that encompasses the entire process, from concept discovery to model training, providing a holistic recipe for leveraging the strengths of GPT, CLIP, and CBM.
CAPE: CAM as a Probabilistic Ensemble for Enhanced DNN Interpretation
Apr 04, 2024Deep Neural Networks (DNNs) are widely used for visual classification tasks, but their complex computation process and black-box nature hinder decision transparency and interpretability. Class activation maps (CAMs) and recent variants provide ways to visually explain the DNN decision-making process by displaying 'attention' heatmaps of the DNNs. Nevertheless, the CAM explanation only offers relative attention information, that is, on an attention heatmap, we can interpret which image region is more or less important than the others. However, these regions cannot be meaningfully compared across classes, and the contribution of each region to the model's class prediction is not revealed. To address these challenges that ultimately lead to better DNN Interpretation, in this paper, we propose CAPE, a novel reformulation of CAM that provides a unified and probabilistically meaningful assessment of the contributions of image regions. We quantitatively and qualitatively compare CAPE with state-of-the-art CAM methods on CUB and ImageNet benchmark datasets to demonstrate enhanced interpretability. We also test on a cytology imaging dataset depicting a challenging Chronic Myelomonocytic Leukemia (CMML) diagnosis problem. Code is available at: https://github.com/AIML-MED/CAPE.
DeepHeteroIoT: Deep Local and Global Learning over Heterogeneous IoT Sensor Data
Mar 29, 2024



Internet of Things (IoT) sensor data or readings evince variations in timestamp range, sampling frequency, geographical location, unit of measurement, etc. Such presented sequence data heterogeneity makes it difficult for traditional time series classification algorithms to perform well. Therefore, addressing the heterogeneity challenge demands learning not only the sub-patterns (local features) but also the overall pattern (global feature). To address the challenge of classifying heterogeneous IoT sensor data (e.g., categorizing sensor data types like temperature and humidity), we propose a novel deep learning model that incorporates both Convolutional Neural Network and Bi-directional Gated Recurrent Unit to learn local and global features respectively, in an end-to-end manner. Through rigorous experimentation on heterogeneous IoT sensor datasets, we validate the effectiveness of our proposed model, which outperforms recent state-of-the-art classification methods as well as several machine learning and deep learning baselines. In particular, the model achieves an average absolute improvement of 3.37% in Accuracy and 2.85% in F1-Score across datasets
Efficient Constrained $k$-Center Clustering with Background Knowledge
Jan 23, 2024



Center-based clustering has attracted significant research interest from both theory and practice. In many practical applications, input data often contain background knowledge that can be used to improve clustering results. In this work, we build on widely adopted $k$-center clustering and model its input background knowledge as must-link (ML) and cannot-link (CL) constraint sets. However, most clustering problems including $k$-center are inherently $\mathcal{NP}$-hard, while the more complex constrained variants are known to suffer severer approximation and computation barriers that significantly limit their applicability. By employing a suite of techniques including reverse dominating sets, linear programming (LP) integral polyhedron, and LP duality, we arrive at the first efficient approximation algorithm for constrained $k$-center with the best possible ratio of 2. We also construct competitive baseline algorithms and empirically evaluate our approximation algorithm against them on a variety of real datasets. The results validate our theoretical findings and demonstrate the great advantages of our algorithm in terms of clustering cost, clustering quality, and running time.
CNN Attention Guidance for Improved Orthopedics Radiographic Fracture Classification
Mar 21, 2022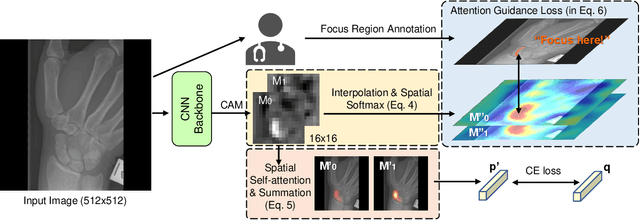
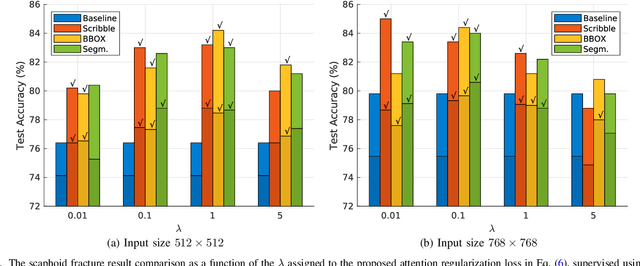
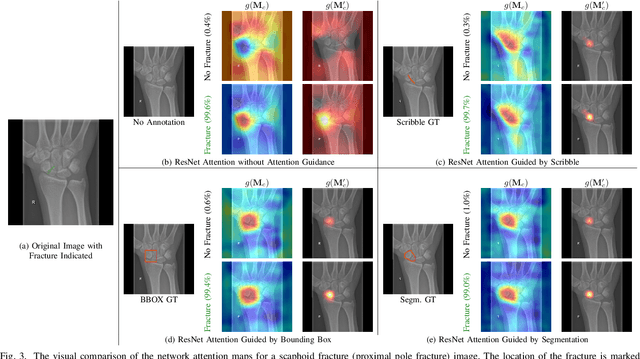
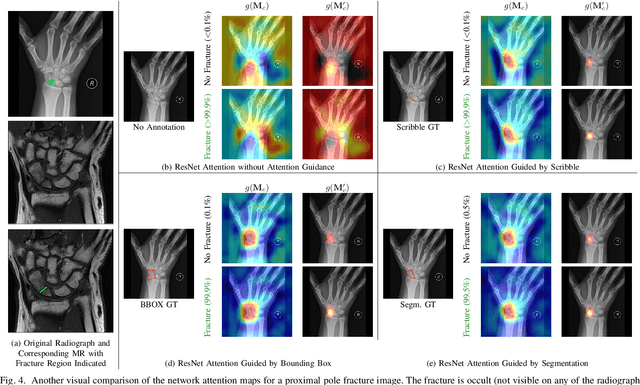
Convolutional neural networks (CNNs) have gained significant popularity in orthopedic imaging in recent years due to their ability to solve fracture classification problems. A common criticism of CNNs is their opaque learning and reasoning process, making it difficult to trust machine diagnosis and the subsequent adoption of such algorithms in clinical setting. This is especially true when the CNN is trained with limited amount of medical data, which is a common issue as curating sufficiently large amount of annotated medical imaging data is a long and costly process. While interest has been devoted to explaining CNN learnt knowledge by visualizing network attention, the utilization of the visualized attention to improve network learning has been rarely investigated. This paper explores the effectiveness of regularizing CNN network with human-provided attention guidance on where in the image the network should look for answering clues. On two orthopedics radiographic fracture classification datasets, through extensive experiments we demonstrate that explicit human-guided attention indeed can direct correct network attention and consequently significantly improve classification performance. The development code for the proposed attention guidance is publicly available on GitHub.
CorrDetector: A Framework for Structural Corrosion Detection from Drone Images using Ensemble Deep Learning
Feb 09, 2021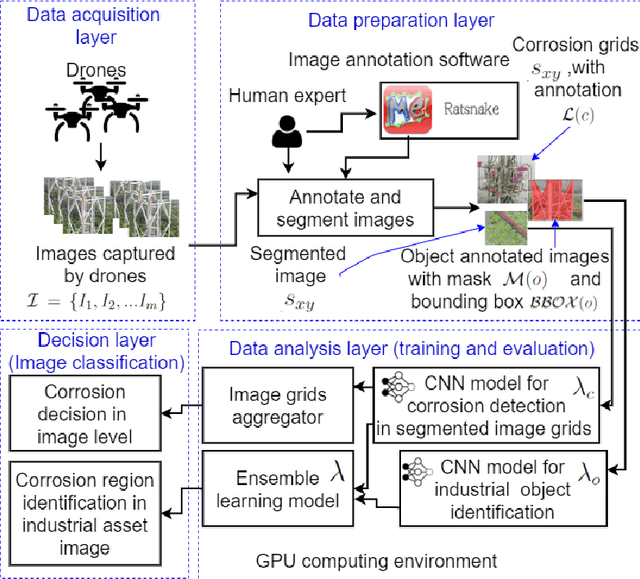

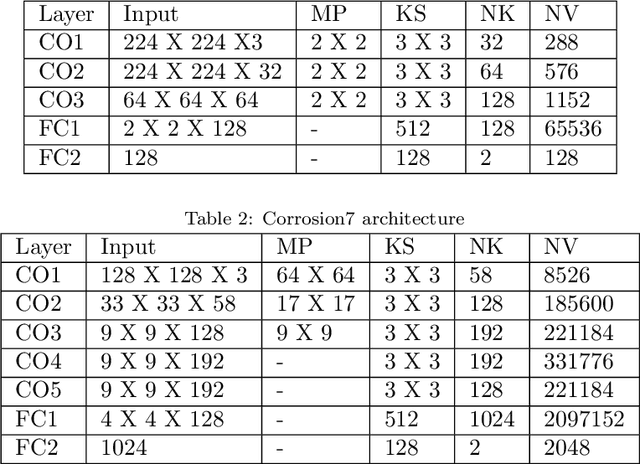
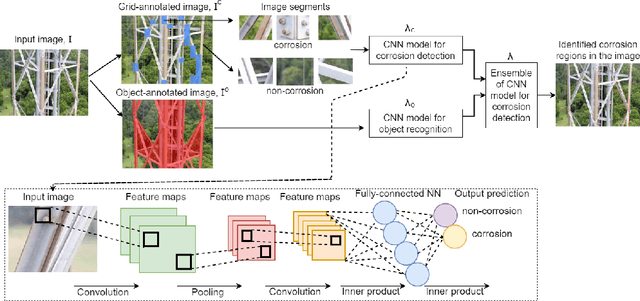
In this paper, we propose a new technique that applies automated image analysis in the area of structural corrosion monitoring and demonstrate improved efficacy compared to existing approaches. Structural corrosion monitoring is the initial step of the risk-based maintenance philosophy and depends on an engineer's assessment regarding the risk of building failure balanced against the fiscal cost of maintenance. This introduces the opportunity for human error which is further complicated when restricted to assessment using drone captured images for those areas not reachable by humans due to many background noises. The importance of this problem has promoted an active research community aiming to support the engineer through the use of artificial intelligence (AI) image analysis for corrosion detection. In this paper, we advance this area of research with the development of a framework, CorrDetector. CorrDetector uses a novel ensemble deep learning approach underpinned by convolutional neural networks (CNNs) for structural identification and corrosion feature extraction. We provide an empirical evaluation using real-world images of a complicated structure (e.g. telecommunication tower) captured by drones, a typical scenario for engineers. Our study demonstrates that the ensemble approach of \model significantly outperforms the state-of-the-art in terms of classification accuracy.