 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAACR-Bench: Evaluating Automatic Code Review with Holistic Repository-Level Context
Jan 27, 2026High-quality evaluation benchmarks are pivotal for deploying Large Language Models (LLMs) in Automated Code Review (ACR). However, existing benchmarks suffer from two critical limitations: first, the lack of multi-language support in repository-level contexts, which restricts the generalizability of evaluation results; second, the reliance on noisy, incomplete ground truth derived from raw Pull Request (PR) comments, which constrains the scope of issue detection. To address these challenges, we introduce AACR-Bench a comprehensive benchmark that provides full cross-file context across multiple programming languages. Unlike traditional datasets, AACR-Bench employs an "AI-assisted, Expert-verified" annotation pipeline to uncover latent defects often overlooked in original PRs, resulting in a 285\% increase in defect coverage. Extensive evaluations of mainstream LLMs on AACR-Bench reveal that previous assessments may have either misjudged or only partially captured model capabilities due to data limitations. Our work establishes a more rigorous standard for ACR evaluation and offers new insights on LLM based ACR, i.e., the granularity/level of context and the choice of retrieval methods significantly impact ACR performance, and this influence varies depending on the LLM, programming language, and the LLM usage paradigm e.g., whether an Agent architecture is employed. The code, data, and other artifacts of our evaluation set are available at https://github.com/alibaba/aacr-bench .
Explainable Deepfake Detection with RL Enhanced Self-Blended Images
Jan 22, 2026Most prior deepfake detection methods lack explainable outputs. With the growing interest in multimodal large language models (MLLMs), researchers have started exploring their use in interpretable deepfake detection. However, a major obstacle in applying MLLMs to this task is the scarcity of high-quality datasets with detailed forgery attribution annotations, as textual annotation is both costly and challenging - particularly for high-fidelity forged images or videos. Moreover, multiple studies have shown that reinforcement learning (RL) can substantially enhance performance in visual tasks, especially in improving cross-domain generalization. To facilitate the adoption of mainstream MLLM frameworks in deepfake detection with reduced annotation cost, and to investigate the potential of RL in this context, we propose an automated Chain-of-Thought (CoT) data generation framework based on Self-Blended Images, along with an RL-enhanced deepfake detection framework. Extensive experiments validate the effectiveness of our CoT data construction pipeline, tailored reward mechanism, and feedback-driven synthetic data generation approach. Our method achieves performance competitive with state-of-the-art (SOTA) approaches across multiple cross-dataset benchmarks. Implementation details are available at https://github.com/deon1219/rlsbi.
Distilling Desired Comments for Enhanced Code Review with Large Language Models
Dec 29, 2024There has been a growing interest in using Large Language Models (LLMs) for code review thanks to their proven proficiency in code comprehension. The primary objective of most review scenarios is to generate desired review comments (DRCs) that explicitly identify issues to trigger code fixes. However, existing LLM-based solutions are not so effective in generating DRCs for various reasons such as hallucination. To enhance their code review ability, they need to be fine-tuned with a customized dataset that is ideally full of DRCs. Nevertheless, such a dataset is not yet available, while manual annotation of DRCs is too laborious to be practical. In this paper, we propose a dataset distillation method, Desiview, which can automatically construct a distilled dataset by identifying DRCs from a code review dataset. Experiments on the CodeReviewer dataset comprising more than 150K review entries show that Desiview achieves an impressive performance of 88.93%, 80.37%, 86.67%, and 84.44% in terms of Precision, Recall, Accuracy, and F1, respectively, surpassing state-of-the-art methods. To validate the effect of such a distilled dataset on enhancing LLMs' code review ability, we first fine-tune the latest LLaMA series (i.e., LLaMA 3 and LLaMA 3.1) to build model Desiview4FT. We then enhance the model training effect through KTO alignment by feeding those review comments identified as non-DRCs to the LLMs, resulting in model Desiview4FA. Verification results indicate that Desiview4FA slightly outperforms Desiview4FT, while both models have significantly improved against the base models in terms of generating DRCs. Human evaluation confirms that both models identify issues more accurately and tend to generate review comments that better describe the issues contained in the code than the base LLMs do.
DeepHeteroIoT: Deep Local and Global Learning over Heterogeneous IoT Sensor Data
Mar 29, 2024



Internet of Things (IoT) sensor data or readings evince variations in timestamp range, sampling frequency, geographical location, unit of measurement, etc. Such presented sequence data heterogeneity makes it difficult for traditional time series classification algorithms to perform well. Therefore, addressing the heterogeneity challenge demands learning not only the sub-patterns (local features) but also the overall pattern (global feature). To address the challenge of classifying heterogeneous IoT sensor data (e.g., categorizing sensor data types like temperature and humidity), we propose a novel deep learning model that incorporates both Convolutional Neural Network and Bi-directional Gated Recurrent Unit to learn local and global features respectively, in an end-to-end manner. Through rigorous experimentation on heterogeneous IoT sensor datasets, we validate the effectiveness of our proposed model, which outperforms recent state-of-the-art classification methods as well as several machine learning and deep learning baselines. In particular, the model achieves an average absolute improvement of 3.37% in Accuracy and 2.85% in F1-Score across datasets
Delving into Multi-modal Multi-task Foundation Models for Road Scene Understanding: From Learning Paradigm Perspectives
Feb 05, 2024



Foundation models have indeed made a profound impact on various fields, emerging as pivotal components that significantly shape the capabilities of intelligent systems. In the context of intelligent vehicles, leveraging the power of foundation models has proven to be transformative, offering notable advancements in visual understanding. Equipped with multi-modal and multi-task learning capabilities, multi-modal multi-task visual understanding foundation models (MM-VUFMs) effectively process and fuse data from diverse modalities and simultaneously handle various driving-related tasks with powerful adaptability, contributing to a more holistic understanding of the surrounding scene. In this survey, we present a systematic analysis of MM-VUFMs specifically designed for road scenes. Our objective is not only to provide a comprehensive overview of common practices, referring to task-specific models, unified multi-modal models, unified multi-task models, and foundation model prompting techniques, but also to highlight their advanced capabilities in diverse learning paradigms. These paradigms include open-world understanding, efficient transfer for road scenes, continual learning, interactive and generative capability. Moreover, we provide insights into key challenges and future trends, such as closed-loop driving systems, interpretability, embodied driving agents, and world models. To facilitate researchers in staying abreast of the latest developments in MM-VUFMs for road scenes, we have established a continuously updated repository at https://github.com/rolsheng/MM-VUFM4DS
CNN Attention Guidance for Improved Orthopedics Radiographic Fracture Classification
Mar 21, 2022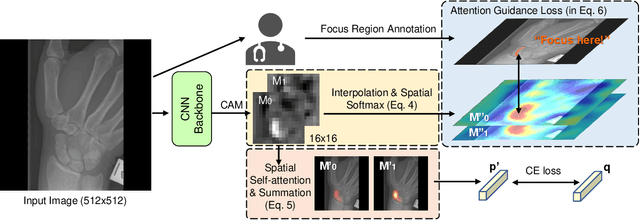
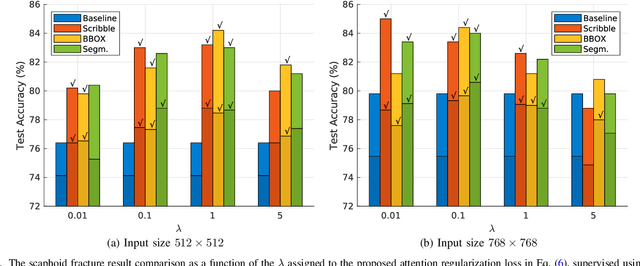
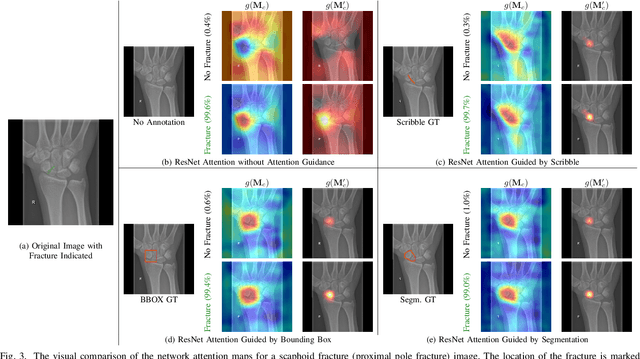
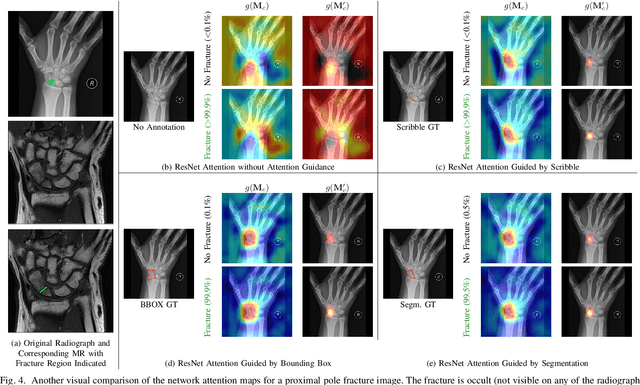
Convolutional neural networks (CNNs) have gained significant popularity in orthopedic imaging in recent years due to their ability to solve fracture classification problems. A common criticism of CNNs is their opaque learning and reasoning process, making it difficult to trust machine diagnosis and the subsequent adoption of such algorithms in clinical setting. This is especially true when the CNN is trained with limited amount of medical data, which is a common issue as curating sufficiently large amount of annotated medical imaging data is a long and costly process. While interest has been devoted to explaining CNN learnt knowledge by visualizing network attention, the utilization of the visualized attention to improve network learning has been rarely investigated. This paper explores the effectiveness of regularizing CNN network with human-provided attention guidance on where in the image the network should look for answering clues. On two orthopedics radiographic fracture classification datasets, through extensive experiments we demonstrate that explicit human-guided attention indeed can direct correct network attention and consequently significantly improve classification performance. The development code for the proposed attention guidance is publicly available on GitHub.
Multi-View Stereo with Transformer
Dec 01, 2021
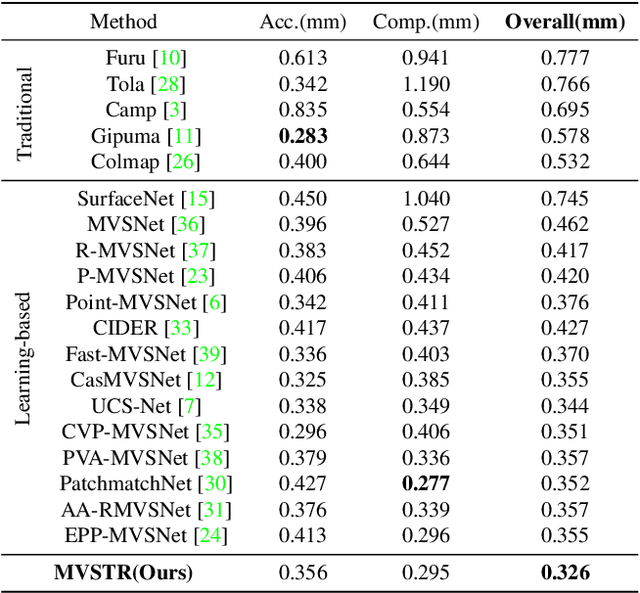
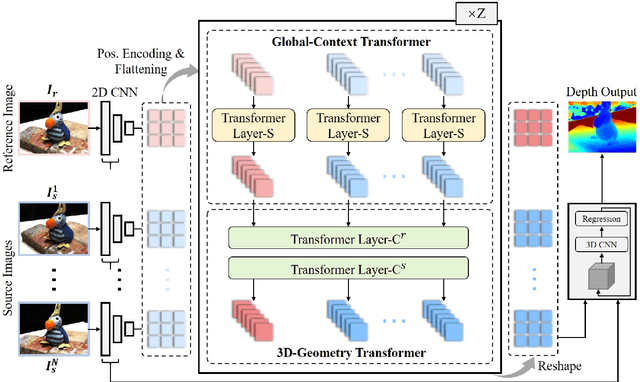
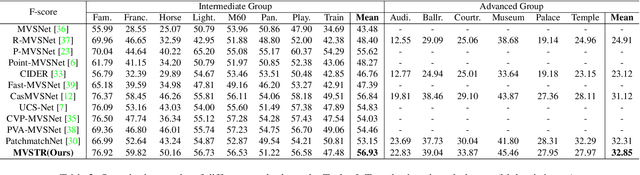
This paper proposes a network, referred to as MVSTR, for Multi-View Stereo (MVS). It is built upon Transformer and is capable of extracting dense features with global context and 3D consistency, which are crucial to achieving reliable matching for MVS. Specifically, to tackle the problem of the limited receptive field of existing CNN-based MVS methods, a global-context Transformer module is first proposed to explore intra-view global context. In addition, to further enable dense features to be 3D-consistent, a 3D-geometry Transformer module is built with a well-designed cross-view attention mechanism to facilitate inter-view information interaction. Experimental results show that the proposed MVSTR achieves the best overall performance on the DTU dataset and strong generalization on the Tanks & Temples benchmark dataset.
Golden Tortoise Beetle Optimizer: A Novel Nature-Inspired Meta-heuristic Algorithm for Engineering Problems
Apr 04, 2021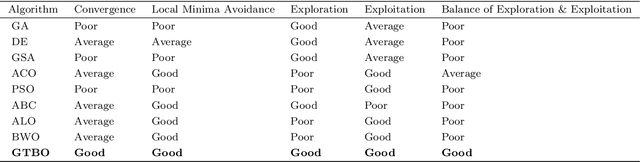


This paper proposes a novel nature-inspired meta-heuristic algorithm called the Golden Tortoise Beetle Optimizer (GTBO) to solve optimization problems. It mimics golden tortoise beetle's behavior of changing colors to attract opposite sex for mating and its protective strategy that uses a kind of anal fork to deter predators. The algorithm is modeled based on the beetle's dual attractiveness and survival strategy to generate new solutions for optimization problems. To measure its performance, the proposed GTBO is compared with five other nature-inspired evolutionary algorithms on 24 well-known benchmark functions investigating the trade-off between exploration and exploitation, local optima avoidance, and convergence towards the global optima is statistically significant. We particularly applied GTBO to two well-known engineering problems including the welded beam design problem and the gear train design problem. The results demonstrate that the new algorithm is more efficient than the five baseline algorithms for both problems. A sensitivity analysis is also performed to reveal different impacts of the algorithm's key control parameters and operators on GTBO's performance.
$P^2$ Net: Augmented Parallel-Pyramid Net for Attention Guided Pose Estimation
Oct 26, 2020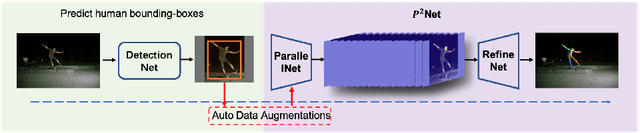

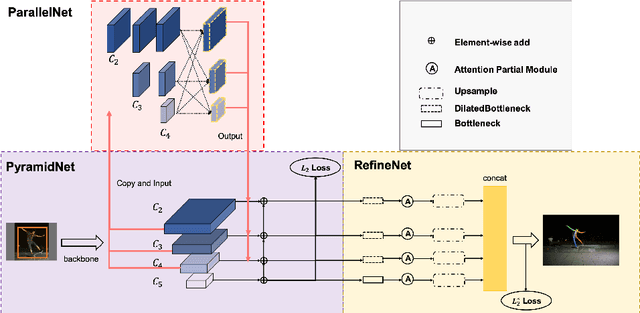
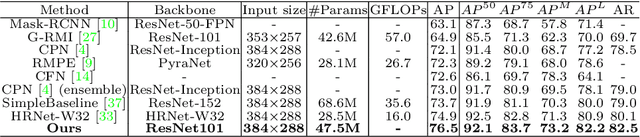
We propose an augmented Parallel-Pyramid Net ($P^2~Net$) with feature refinement by dilated bottleneck and attention module. During data preprocessing, we proposed a differentiable auto data augmentation ($DA^2$) method. We formulate the problem of searching data augmentaion policy in a differentiable form, so that the optimal policy setting can be easily updated by back propagation during training. $DA^2$ improves the training efficiency. A parallel-pyramid structure is followed to compensate the information loss introduced by the network. We innovate two fusion structures, i.e. Parallel Fusion and Progressive Fusion, to process pyramid features from backbone network. Both fusion structures leverage the advantages of spatial information affluence at high resolution and semantic comprehension at low resolution effectively. We propose a refinement stage for the pyramid features to further boost the accuracy of our network. By introducing dilated bottleneck and attention module, we increase the receptive field for the features with limited complexity and tune the importance to different feature channels. To further refine the feature maps after completion of feature extraction stage, an Attention Module ($AM$) is defined to extract weighted features from different scale feature maps generated by the parallel-pyramid structure. Compared with the traditional up-sampling refining, $AM$ can better capture the relationship between channels. Experiments corroborate the effectiveness of our proposed method. Notably, our method achieves the best performance on the challenging MSCOCO and MPII datasets.
Single Image Super-Resolution via a Holistic Attention Network
Aug 20, 2020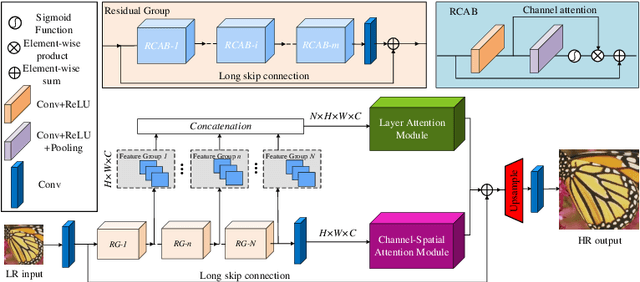

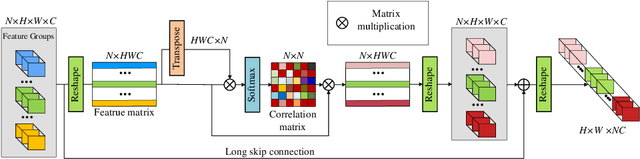

Informative features play a crucial role in the single image super-resolution task. Channel attention has been demonstrated to be effective for preserving information-rich features in each layer. However, channel attention treats each convolution layer as a separate process that misses the correlation among different layers. To address this problem, we propose a new holistic attention network (HAN), which consists of a layer attention module (LAM) and a channel-spatial attention module (CSAM), to model the holistic interdependencies among layers, channels, and positions. Specifically, the proposed LAM adaptively emphasizes hierarchical features by considering correlations among layers. Meanwhile, CSAM learns the confidence at all the positions of each channel to selectively capture more informative features. Extensive experiments demonstrate that the proposed HAN performs favorably against the state-of-the-art single image super-resolution approaches.