 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoReason: Aligning Thinking And Answering In Remote Sensing Vision-Language Models Via Logical Consistency Reinforcement Learning
Jan 08, 2026The evolution of Remote Sensing Vision-Language Models(RS-VLMs) emphasizes the importance of transitioning from perception-centric recognition toward high-level deductive reasoning to enhance cognitive reliability in complex spatial tasks. However, current models often suffer from logical hallucinations, where correct answers are derived from flawed reasoning chains or rely on positional shortcuts rather than spatial logic. This decoupling undermines reliability in strategic spatial decision-making. To address this, we present GeoReason, a framework designed to synchronize internal thinking with final decisions. We first construct GeoReason-Bench, a logic-driven dataset containing 4,000 reasoning trajectories synthesized from geometric primitives and expert knowledge. We then formulate a two-stage training strategy: (1) Supervised Knowledge Initialization to equip the model with reasoning syntax and domain expertise, and (2) Consistency-Aware Reinforcement Learning to refine deductive reliability. This second stage integrates a novel Logical Consistency Reward, which penalizes logical drift via an option permutation strategy to anchor decisions in verifiable reasoning traces. Experimental results demonstrate that our framework significantly enhances the cognitive reliability and interpretability of RS-VLMs, achieving state-of-the-art performance compared to other advanced methods.
SLGNet: Synergizing Structural Priors and Language-Guided Modulation for Multimodal Object Detection
Jan 05, 2026Multimodal object detection leveraging RGB and Infrared (IR) images is pivotal for robust perception in all-weather scenarios. While recent adapter-based approaches efficiently transfer RGB-pretrained foundation models to this task, they often prioritize model efficiency at the expense of cross-modal structural consistency. Consequently, critical structural cues are frequently lost when significant domain gaps arise, such as in high-contrast or nighttime environments. Moreover, conventional static multimodal fusion mechanisms typically lack environmental awareness, resulting in suboptimal adaptation and constrained detection performance under complex, dynamic scene variations. To address these limitations, we propose SLGNet, a parameter-efficient framework that synergizes hierarchical structural priors and language-guided modulation within a frozen Vision Transformer (ViT)-based foundation model. Specifically, we design a Structure-Aware Adapter to extract hierarchical structural representations from both modalities and dynamically inject them into the ViT to compensate for structural degradation inherent in ViT-based backbones. Furthermore, we propose a Language-Guided Modulation module that exploits VLM-driven structured captions to dynamically recalibrate visual features, thereby endowing the model with robust environmental awareness. Extensive experiments on the LLVIP, FLIR, KAIST, and DroneVehicle datasets demonstrate that SLGNet establishes new state-of-the-art performance. Notably, on the LLVIP benchmark, our method achieves an mAP of 66.1, while reducing trainable parameters by approximately 87% compared to traditional full fine-tuning. This confirms SLGNet as a robust and efficient solution for multimodal perception.
Training Data Attribution: Was Your Model Secretly Trained On Data Created By Mine?
Sep 24, 2024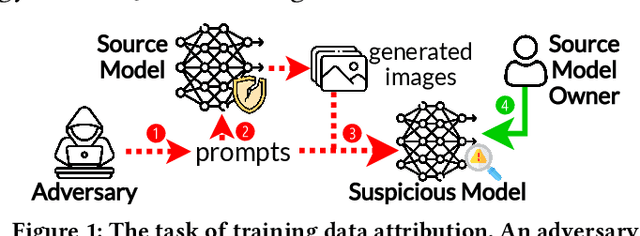
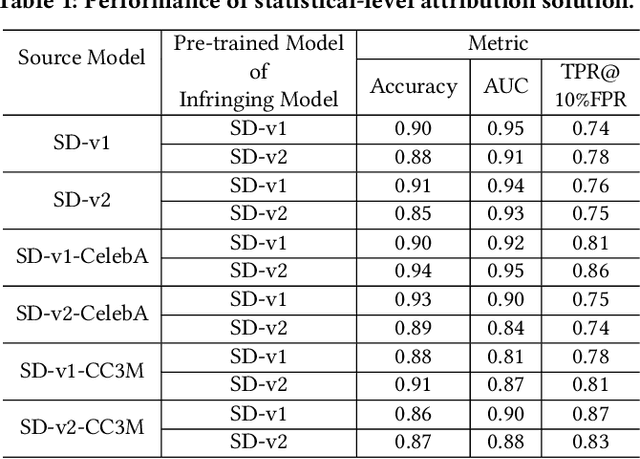

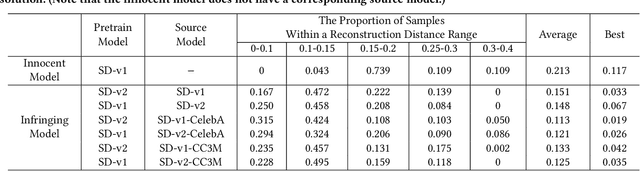
The emergence of text-to-image models has recently sparked significant interest, but the attendant is a looming shadow of potential infringement by violating the user terms. Specifically, an adversary may exploit data created by a commercial model to train their own without proper authorization. To address such risk, it is crucial to investigate the attribution of a suspicious model's training data by determining whether its training data originates, wholly or partially, from a specific source model. To trace the generated data, existing methods require applying extra watermarks during either the training or inference phases of the source model. However, these methods are impractical for pre-trained models that have been released, especially when model owners lack security expertise. To tackle this challenge, we propose an injection-free training data attribution method for text-to-image models. It can identify whether a suspicious model's training data stems from a source model, without additional modifications on the source model. The crux of our method lies in the inherent memorization characteristic of text-to-image models. Our core insight is that the memorization of the training dataset is passed down through the data generated by the source model to the model trained on that data, making the source model and the infringing model exhibit consistent behaviors on specific samples. Therefore, our approach involves developing algorithms to uncover these distinct samples and using them as inherent watermarks to verify if a suspicious model originates from the source model. Our experiments demonstrate that our method achieves an accuracy of over 80\% in identifying the source of a suspicious model's training data, without interfering the original training or generation process of the source model.
Bypassing DARCY Defense: Indistinguishable Universal Adversarial Triggers
Sep 05, 2024Neural networks (NN) classification models for Natural Language Processing (NLP) are vulnerable to the Universal Adversarial Triggers (UAT) attack that triggers a model to produce a specific prediction for any input. DARCY borrows the "honeypot" concept to bait multiple trapdoors, effectively detecting the adversarial examples generated by UAT. Unfortunately, we find a new UAT generation method, called IndisUAT, which produces triggers (i.e., tokens) and uses them to craft adversarial examples whose feature distribution is indistinguishable from that of the benign examples in a randomly-chosen category at the detection layer of DARCY. The produced adversarial examples incur the maximal loss of predicting results in the DARCY-protected models. Meanwhile, the produced triggers are effective in black-box models for text generation, text inference, and reading comprehension. Finally, the evaluation results under NN models for NLP tasks indicate that the IndisUAT method can effectively circumvent DARCY and penetrate other defenses. For example, IndisUAT can reduce the true positive rate of DARCY's detection by at least 40.8% and 90.6%, and drop the accuracy by at least 33.3% and 51.6% in the RNN and CNN models, respectively. IndisUAT reduces the accuracy of the BERT's adversarial defense model by at least 34.0%, and makes the GPT-2 language model spew racist outputs even when conditioned on non-racial context.
Exploring User Acceptance Of Portable Intelligent Personal Assistants: A Hybrid Approach Using PLS-SEM And fsQCA
Aug 30, 2024This research explores the factors driving user acceptance of Rabbit R1, a newly developed portable intelligent personal assistant (PIPA) that aims to redefine user interaction and control. The study extends the technology acceptance model (TAM) by incorporating artificial intelligence-specific factors (conversational intelligence, task intelligence, and perceived naturalness), user interface design factors (simplicity in information design and visual aesthetics), and user acceptance and loyalty. Using a purposive sampling method, we gathered data from 824 users in the US and analyzed the sample through partial least squares structural equation modeling (PLS-SEM) and fuzzy set qualitative comparative analysis (fsQCA). The findings reveal that all hypothesized relationships, including both direct and indirect effects, are supported. Additionally, fsQCA supports the PLS-SEM findings and identifies three configurations leading to high and low user acceptance. This research enriches the literature and provides valuable insights for system designers and marketers of PIPAs, guiding strategic decisions to foster widespread adoption and long-term engagement.
Factors Influencing User Willingness To Use SORA
May 07, 2024Sora promises to redefine the way visual content is created. Despite its numerous forecasted benefits, the drivers of user willingness to use the text-to-video (T2V) model are unknown. This study extends the extended unified theory of acceptance and use of technology (UTAUT2) with perceived realism and novelty value. Using a purposive sampling method, we collected data from 940 respondents in the US and analyzed the sample using covariance-based structural equation modeling and fuzzy set qualitative comparative analysis (fsQCA). The findings reveal that all hypothesized relationships are supported, with perceived realism emerging as the most influential driver, followed by novelty value. Moreover, fsQCA identifies five configurations leading to high and low willingness to use, and the model demonstrates high predictive validity, contributing to theory advancement. Our study provides valuable insights for developers and marketers, offering guidance for strategic decisions to promote the widespread adoption of T2V models.
Patient Dropout Prediction in Virtual Health: A Multimodal Dynamic Knowledge Graph and Text Mining Approach
Jun 07, 2023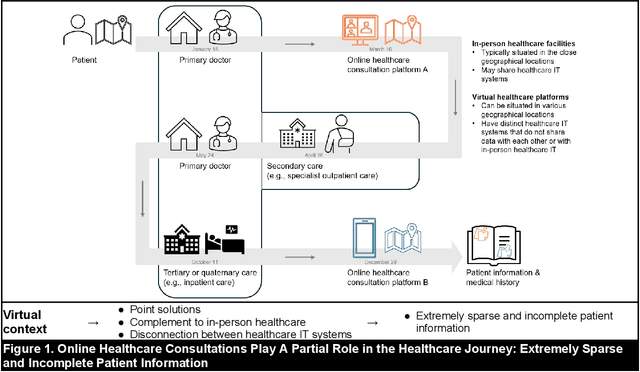
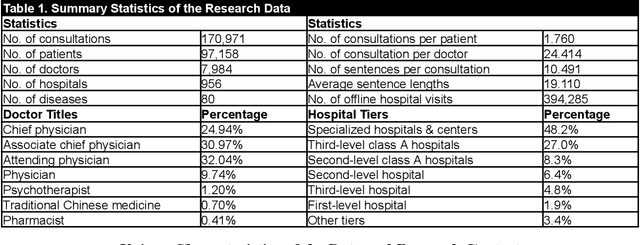


Virtual health has been acclaimed as a transformative force in healthcare delivery. Yet, its dropout issue is critical that leads to poor health outcomes, increased health, societal, and economic costs. Timely prediction of patient dropout enables stakeholders to take proactive steps to address patients' concerns, potentially improving retention rates. In virtual health, the information asymmetries inherent in its delivery format, between different stakeholders, and across different healthcare delivery systems hinder the performance of existing predictive methods. To resolve those information asymmetries, we propose a Multimodal Dynamic Knowledge-driven Dropout Prediction (MDKDP) framework that learns implicit and explicit knowledge from doctor-patient dialogues and the dynamic and complex networks of various stakeholders in both online and offline healthcare delivery systems. We evaluate MDKDP by partnering with one of the largest virtual health platforms in China. MDKDP improves the F1-score by 3.26 percentage points relative to the best benchmark. Comprehensive robustness analyses show that integrating stakeholder attributes, knowledge dynamics, and compact bilinear pooling significantly improves the performance. Our work provides significant implications for healthcare IT by revealing the value of mining relations and knowledge across different service modalities. Practically, MDKDP offers a novel design artifact for virtual health platforms in patient dropout management.
Single Image Super-Resolution via a Holistic Attention Network
Aug 20, 2020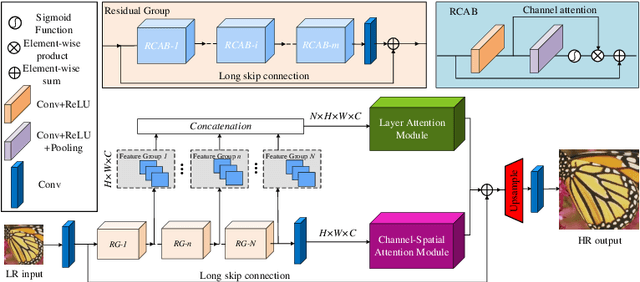

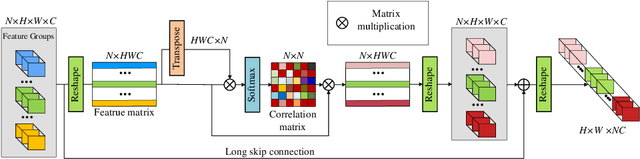

Informative features play a crucial role in the single image super-resolution task. Channel attention has been demonstrated to be effective for preserving information-rich features in each layer. However, channel attention treats each convolution layer as a separate process that misses the correlation among different layers. To address this problem, we propose a new holistic attention network (HAN), which consists of a layer attention module (LAM) and a channel-spatial attention module (CSAM), to model the holistic interdependencies among layers, channels, and positions. Specifically, the proposed LAM adaptively emphasizes hierarchical features by considering correlations among layers. Meanwhile, CSAM learns the confidence at all the positions of each channel to selectively capture more informative features. Extensive experiments demonstrate that the proposed HAN performs favorably against the state-of-the-art single image super-resolution approaches.
Input Perturbation: A New Paradigm between Central and Local Differential Privacy
Feb 20, 2020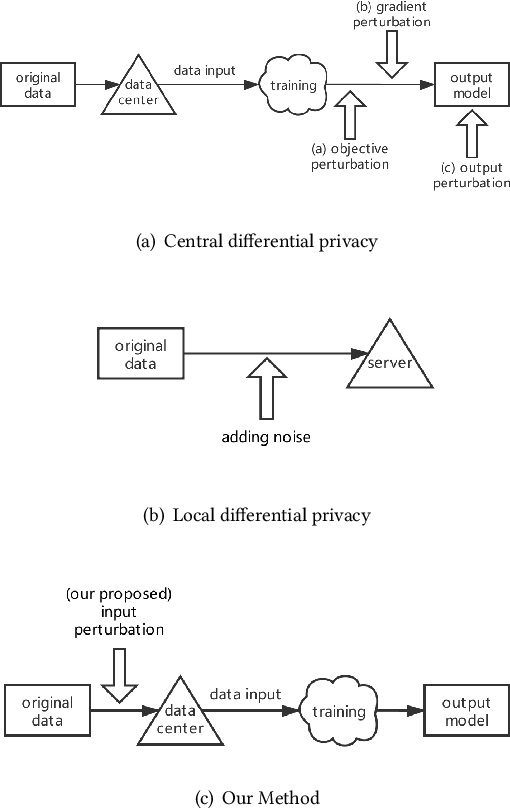
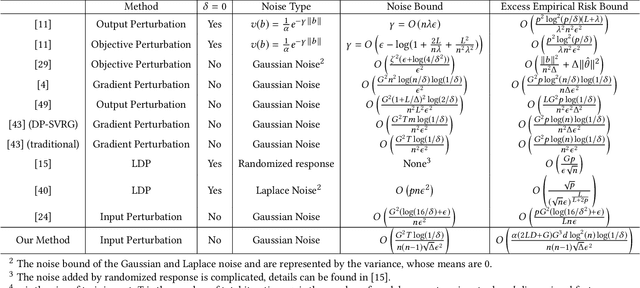
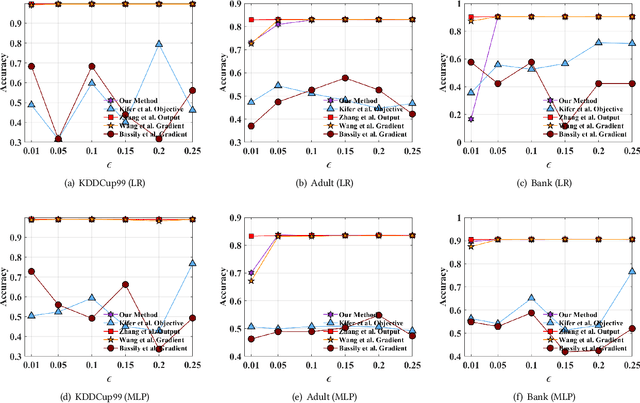
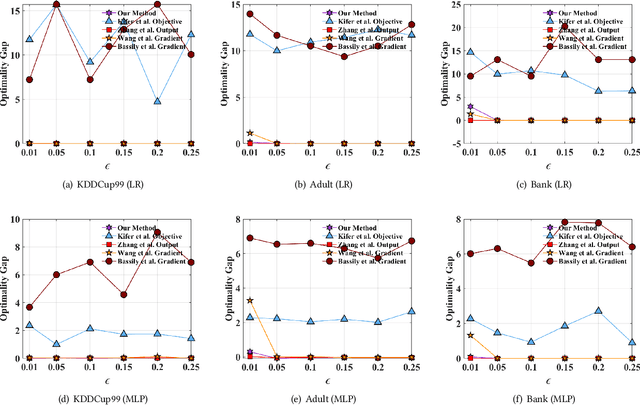
Traditionally, there are two models on differential privacy: the central model and the local model. The central model focuses on the machine learning model and the local model focuses on the training data. In this paper, we study the \textit{input perturbation} method in differentially private empirical risk minimization (DP-ERM), preserving privacy of the central model. By adding noise to the original training data and training with the `perturbed data', we achieve ($\epsilon$,$\delta$)-differential privacy on the final model, along with some kind of privacy on the original data. We observe that there is an interesting connection between the local model and the central model: the perturbation on the original data causes the perturbation on the gradient, and finally the model parameters. This observation means that our method builds a bridge between local and central model, protecting the data, the gradient and the model simultaneously, which is more superior than previous central methods. Detailed theoretical analysis and experiments show that our method achieves almost the same (or even better) performance as some of the best previous central methods with more protections on privacy, which is an attractive result. Moreover, we extend our method to a more general case: the loss function satisfies the Polyak-Lojasiewicz condition, which is more general than strong convexity, the constraint on the loss function in most previous work.