 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyncBreaker:Stage-Aware Multimodal Adversarial Attacks on Audio-Driven Talking Head Generation
Apr 09, 2026Diffusion-based audio-driven talking-head generation enables realistic portrait animation, but also introduces risks of misuse, such as fraud and misinformation. Existing protection methods are largely limited to a single modality, and neither image-only nor audio-only attacks can effectively suppress speech-driven facial dynamics. To address this gap, we propose SyncBreaker, a stage-aware multimodal protection framework that jointly perturbs portrait and audio inputs under modality-specific perceptual constraints. Our key contributions are twofold. First, for the image stream, we introduce nullifying supervision with Multi-Interval Sampling (MIS) across diffusion stages to steer the generation toward the static reference portrait by aggregating guidance from multiple denoising intervals. Second, for the audio stream, we propose Cross-Attention Fooling (CAF), which suppresses interval-specific audio-conditioned cross-attention responses. Both streams are optimized independently and combined at inference time to enable flexible deployment. We evaluate SyncBreaker in a white-box proactive protection setting. Extensive experiments demonstrate that SyncBreaker more effectively degrades lip synchronization and facial dynamics than strong single-modality baselines, while preserving input perceptual quality and remaining robust under purification. Code: https://github.com/kitty384/SyncBreaker.
The PokeAgent Challenge: Competitive and Long-Context Learning at Scale
Mar 17, 2026We present the PokeAgent Challenge, a large-scale benchmark for decision-making research built on Pokemon's multi-agent battle system and expansive role-playing game (RPG) environment. Partial observability, game-theoretic reasoning, and long-horizon planning remain open problems for frontier AI, yet few benchmarks stress all three simultaneously under realistic conditions. PokeAgent targets these limitations at scale through two complementary tracks: our Battling Track, which calls for strategic reasoning and generalization under partial observability in competitive Pokemon battles, and our Speedrunning Track, which requires long-horizon planning and sequential decision-making in the Pokemon RPG. Our Battling Track supplies a dataset of 20M+ battle trajectories alongside a suite of heuristic, RL, and LLM-based baselines capable of high-level competitive play. Our Speedrunning Track provides the first standardized evaluation framework for RPG speedrunning, including an open-source multi-agent orchestration system for modular, reproducible comparisons of harness-based LLM approaches. Our NeurIPS 2025 competition validates both the quality of our resources and the research community's interest in Pokemon, with over 100 teams competing across both tracks and winning solutions detailed in our paper. Participant submissions and our baselines reveal considerable gaps between generalist (LLM), specialist (RL), and elite human performance. Analysis against the BenchPress evaluation matrix shows that Pokemon battling is nearly orthogonal to standard LLM benchmarks, measuring capabilities not captured by existing suites and positioning Pokemon as an unsolved benchmark that can drive RL and LLM research forward. We transition to a living benchmark with a live leaderboard for Battling and self-contained evaluation for Speedrunning at https://pokeagentchallenge.com.
DreamScene: 3D Gaussian-based Text-to-3D Scene Generation via Formation Pattern Sampling
Apr 04, 2024
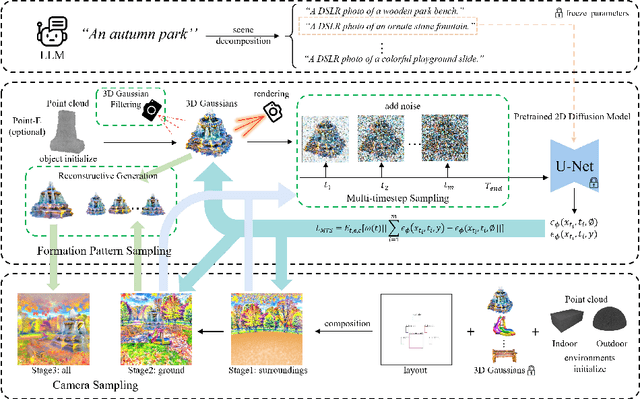
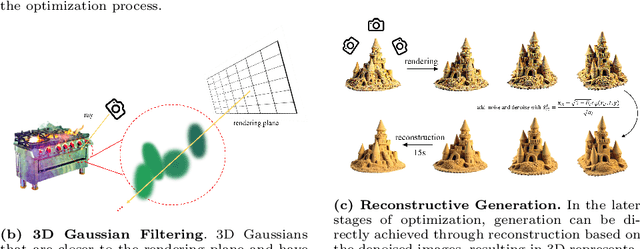
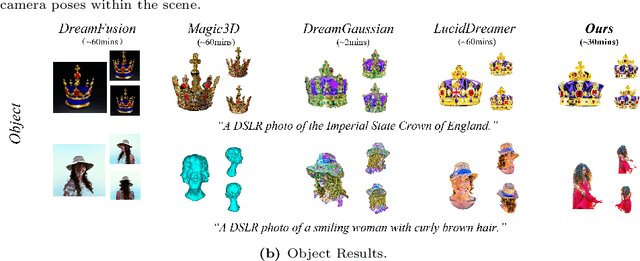
Text-to-3D scene generation holds immense potential for the gaming, film, and architecture sectors. Despite significant progress, existing methods struggle with maintaining high quality, consistency, and editing flexibility. In this paper, we propose DreamScene, a 3D Gaussian-based novel text-to-3D scene generation framework, to tackle the aforementioned three challenges mainly via two strategies. First, DreamScene employs Formation Pattern Sampling (FPS), a multi-timestep sampling strategy guided by the formation patterns of 3D objects, to form fast, semantically rich, and high-quality representations. FPS uses 3D Gaussian filtering for optimization stability, and leverages reconstruction techniques to generate plausible textures. Second, DreamScene employs a progressive three-stage camera sampling strategy, specifically designed for both indoor and outdoor settings, to effectively ensure object-environment integration and scene-wide 3D consistency. Last, DreamScene enhances scene editing flexibility by integrating objects and environments, enabling targeted adjustments. Extensive experiments validate DreamScene's superiority over current state-of-the-art techniques, heralding its wide-ranging potential for diverse applications. Code and demos will be released at https://dreamscene-project.github.io .
rFaceNet: An End-to-End Network for Enhanced Physiological Signal Extraction through Identity-Specific Facial Contours
Mar 17, 2024



Remote photoplethysmography (rPPG) technique extracts blood volume pulse (BVP) signals from subtle pixel changes in video frames. This study introduces rFaceNet, an advanced rPPG method that enhances the extraction of facial BVP signals with a focus on facial contours. rFaceNet integrates identity-specific facial contour information and eliminates redundant data. It efficiently extracts facial contours from temporally normalized frame inputs through a Temporal Compressor Unit (TCU) and steers the model focus to relevant facial regions by using the Cross-Task Feature Combiner (CTFC). Through elaborate training, the quality and interpretability of facial physiological signals extracted by rFaceNet are greatly improved compared to previous methods. Moreover, our novel approach demonstrates superior performance than SOTA methods in various heart rate estimation benchmarks.
Few-Shot Learning for Chronic Disease Management: Leveraging Large Language Models and Multi-Prompt Engineering with Medical Knowledge Injection
Jan 16, 2024This study harnesses state-of-the-art AI technology for chronic disease management, specifically in detecting various mental disorders through user-generated textual content. Existing studies typically rely on fully supervised machine learning, which presents challenges such as the labor-intensive manual process of annotating extensive training data for each disease and the need to design specialized deep learning architectures for each problem. To address such challenges, we propose a novel framework that leverages advanced AI techniques, including large language models and multi-prompt engineering. Specifically, we address two key technical challenges in data-driven chronic disease management: (1) developing personalized prompts to represent each user's uniqueness and (2) incorporating medical knowledge into prompts to provide context for chronic disease detection, instruct learning objectives, and operationalize prediction goals. We evaluate our method using four mental disorders, which are prevalent chronic diseases worldwide, as research cases. On the depression detection task, our method (F1 = 0.975~0.978) significantly outperforms traditional supervised learning paradigms, including feature engineering (F1 = 0.760) and architecture engineering (F1 = 0.756). Meanwhile, our approach demonstrates success in few-shot learning, i.e., requiring only a minimal number of training examples to detect chronic diseases based on user-generated textual content (i.e., only 2, 10, or 100 subjects). Moreover, our method can be generalized to other mental disorder detection tasks, including anorexia, pathological gambling, and self-harm (F1 = 0.919~0.978).
Patient Dropout Prediction in Virtual Health: A Multimodal Dynamic Knowledge Graph and Text Mining Approach
Jun 07, 2023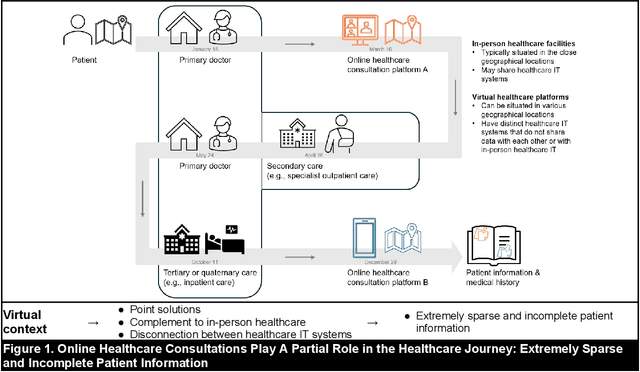
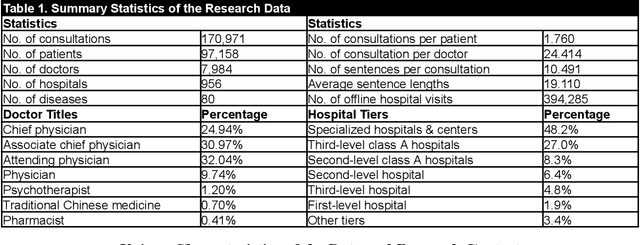


Virtual health has been acclaimed as a transformative force in healthcare delivery. Yet, its dropout issue is critical that leads to poor health outcomes, increased health, societal, and economic costs. Timely prediction of patient dropout enables stakeholders to take proactive steps to address patients' concerns, potentially improving retention rates. In virtual health, the information asymmetries inherent in its delivery format, between different stakeholders, and across different healthcare delivery systems hinder the performance of existing predictive methods. To resolve those information asymmetries, we propose a Multimodal Dynamic Knowledge-driven Dropout Prediction (MDKDP) framework that learns implicit and explicit knowledge from doctor-patient dialogues and the dynamic and complex networks of various stakeholders in both online and offline healthcare delivery systems. We evaluate MDKDP by partnering with one of the largest virtual health platforms in China. MDKDP improves the F1-score by 3.26 percentage points relative to the best benchmark. Comprehensive robustness analyses show that integrating stakeholder attributes, knowledge dynamics, and compact bilinear pooling significantly improves the performance. Our work provides significant implications for healthcare IT by revealing the value of mining relations and knowledge across different service modalities. Practically, MDKDP offers a novel design artifact for virtual health platforms in patient dropout management.
MD-Manifold: A Medical-Distance-Based Representation Learning Approach for Medical Concept and Patient Representation
Apr 30, 2023



Effectively representing medical concepts and patients is important for healthcare analytical applications. Representing medical concepts for healthcare analytical tasks requires incorporating medical domain knowledge and prior information from patient description data. Current methods, such as feature engineering and mapping medical concepts to standardized terminologies, have limitations in capturing the dynamic patterns from patient description data. Other embedding-based methods have difficulties in incorporating important medical domain knowledge and often require a large amount of training data, which may not be feasible for most healthcare systems. Our proposed framework, MD-Manifold, introduces a novel approach to medical concept and patient representation. It includes a new data augmentation approach, concept distance metric, and patient-patient network to incorporate crucial medical domain knowledge and prior data information. It then adapts manifold learning methods to generate medical concept-level representations that accurately reflect medical knowledge and patient-level representations that clearly identify heterogeneous patient cohorts. MD-Manifold also outperforms other state-of-the-art techniques in various downstream healthcare analytical tasks. Our work has significant implications in information systems research in representation learning, knowledge-driven machine learning, and using design science as middle-ground frameworks for downstream explorative and predictive analyses. Practically, MD-Manifold has the potential to create effective and generalizable representations of medical concepts and patients by incorporating medical domain knowledge and prior data information. It enables deeper insights into medical data and facilitates the development of new analytical applications for better healthcare outcomes.
Depression Detection Using Digital Traces on Social Media: A Knowledge-aware Deep Learning Approach
Mar 06, 2023Depression is a common disease worldwide. It is difficult to diagnose and continues to be underdiagnosed. Because depressed patients constantly share their symptoms, major life events, and treatments on social media, researchers are turning to user-generated digital traces on social media for depression detection. Such methods have distinct advantages in combating depression because they can facilitate innovative approaches to fight depression and alleviate its social and economic burden. However, most existing studies lack effective means to incorporate established medical domain knowledge in depression detection or suffer from feature extraction difficulties that impede greater performance. Following the design science research paradigm, we propose a Deep Knowledge-aware Depression Detection (DKDD) framework to accurately detect social media users at risk of depression and explain the critical factors that contribute to such detection. Extensive empirical studies with real-world data demonstrate that, by incorporating domain knowledge, our method outperforms existing state-of-the-art methods. Our work has significant implications for IS research in knowledge-aware machine learning, digital traces utilization, and NLP research in IS. Practically, by providing early detection and explaining the critical factors, DKDD can supplement clinical depression screening and enable large-scale evaluations of a population's mental health status.