 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniCPM-SALA: Hybridizing Sparse and Linear Attention for Efficient Long-Context Modeling
Feb 12, 2026The evolution of large language models (LLMs) towards applications with ultra-long contexts faces challenges posed by the high computational and memory costs of the Transformer architecture. While existing sparse and linear attention mechanisms attempt to mitigate these issues, they typically involve a trade-off between memory efficiency and model performance. This paper introduces MiniCPM-SALA, a 9B-parameter hybrid architecture that integrates the high-fidelity long-context modeling of sparse attention (InfLLM-V2) with the global efficiency of linear attention (Lightning Attention). By employing a layer selection algorithm to integrate these mechanisms in a 1:3 ratio and utilizing a hybrid positional encoding (HyPE), the model maintains efficiency and performance for long-context tasks. Furthermore, we introduce a cost-effective continual training framework that transforms pre-trained Transformer-based models into hybrid models, which reduces training costs by approximately 75% compared to training from scratch. Extensive experiments show that MiniCPM-SALA maintains general capabilities comparable to full-attention models while offering improved efficiency. On a single NVIDIA A6000D GPU, the model achieves up to 3.5x the inference speed of the full-attention model at the sequence length of 256K tokens and supports context lengths of up to 1M tokens, a scale where traditional full-attention 8B models fail because of memory constraints.
Hybrid Linear Attention Done Right: Efficient Distillation and Effective Architectures for Extremely Long Contexts
Jan 29, 2026Hybrid Transformer architectures, which combine softmax attention blocks and recurrent neural networks (RNNs), have shown a desirable performance-throughput tradeoff for long-context modeling, but their adoption and studies are hindered by the prohibitive cost of large-scale pre-training from scratch. Some recent studies have shown that pre-trained softmax attention blocks can be converted into RNN blocks through parameter transfer and knowledge distillation. However, these transfer methods require substantial amounts of training data (more than 10B tokens), and the resulting hybrid models also exhibit poor long-context performance, which is the scenario where hybrid models enjoy significant inference speedups over Transformer-based models. In this paper, we present HALO (Hybrid Attention via Layer Optimization), a pipeline for distilling Transformer models into RNN-attention hybrid models. We then present HypeNet, a hybrid architecture with superior length generalization enabled by a novel position encoding scheme (named HyPE) and various architectural modifications. We convert the Qwen3 series into HypeNet using HALO, achieving performance comparable to the original Transformer models while enjoying superior long-context performance and efficiency. The conversion requires just 2.3B tokens, less than 0.01% of their pre-training data
A Medical Multimodal Diagnostic Framework Integrating Vision-Language Models and Logic Tree Reasoning
Dec 25, 2025With the rapid growth of large language models (LLMs) and vision-language models (VLMs) in medicine, simply integrating clinical text and medical imaging does not guarantee reliable reasoning. Existing multimodal models often produce hallucinations or inconsistent chains of thought, limiting clinical trust. We propose a diagnostic framework built upon LLaVA that combines vision-language alignment with logic-regularized reasoning. The system includes an input encoder for text and images, a projection module for cross-modal alignment, a reasoning controller that decomposes diagnostic tasks into steps, and a logic tree generator that assembles stepwise premises into verifiable conclusions. Evaluations on MedXpertQA and other benchmarks show that our method improves diagnostic accuracy and yields more interpretable reasoning traces on multimodal tasks, while remaining competitive on text-only settings. These results suggest a promising step toward trustworthy multimodal medical AI.
Monocle: Hybrid Local-Global In-Context Evaluation for Long-Text Generation with Uncertainty-Based Active Learning
May 27, 2025Assessing the quality of long-form, model-generated text is challenging, even with advanced LLM-as-a-Judge methods, due to performance degradation as input length increases. To address this issue, we propose a divide-and-conquer approach, which breaks down the comprehensive evaluation task into a series of localized scoring tasks, followed by a final global assessment. This strategy allows for more granular and manageable evaluations, ensuring that each segment of the text is assessed in isolation for both coherence and quality, while also accounting for the overall structure and consistency of the entire piece. Moreover, we introduce a hybrid in-context learning approach that leverages human annotations to enhance the performance of both local and global evaluations. By incorporating human-generated feedback directly into the evaluation process, this method allows the model to better align with human judgment. Finally, we develop an uncertainty-based active learning algorithm that efficiently selects data samples for human annotation, thereby reducing annotation costs in practical scenarios. Experimental results show that the proposed evaluation framework outperforms several representative baselines, highlighting the effectiveness of our approach.
LLM$\times$MapReduce-V2: Entropy-Driven Convolutional Test-Time Scaling for Generating Long-Form Articles from Extremely Long Resources
Apr 08, 2025Long-form generation is crucial for a wide range of practical applications, typically categorized into short-to-long and long-to-long generation. While short-to-long generations have received considerable attention, generating long texts from extremely long resources remains relatively underexplored. The primary challenge in long-to-long generation lies in effectively integrating and analyzing relevant information from extensive inputs, which remains difficult for current large language models (LLMs). In this paper, we propose LLM$\times$MapReduce-V2, a novel test-time scaling strategy designed to enhance the ability of LLMs to process extremely long inputs. Drawing inspiration from convolutional neural networks, which iteratively integrate local features into higher-level global representations, LLM$\times$MapReduce-V2 utilizes stacked convolutional scaling layers to progressively expand the understanding of input materials. Both quantitative and qualitative experimental results demonstrate that our approach substantially enhances the ability of LLMs to process long inputs and generate coherent, informative long-form articles, outperforming several representative baselines.
Few-Shot Learning for Chronic Disease Management: Leveraging Large Language Models and Multi-Prompt Engineering with Medical Knowledge Injection
Jan 16, 2024This study harnesses state-of-the-art AI technology for chronic disease management, specifically in detecting various mental disorders through user-generated textual content. Existing studies typically rely on fully supervised machine learning, which presents challenges such as the labor-intensive manual process of annotating extensive training data for each disease and the need to design specialized deep learning architectures for each problem. To address such challenges, we propose a novel framework that leverages advanced AI techniques, including large language models and multi-prompt engineering. Specifically, we address two key technical challenges in data-driven chronic disease management: (1) developing personalized prompts to represent each user's uniqueness and (2) incorporating medical knowledge into prompts to provide context for chronic disease detection, instruct learning objectives, and operationalize prediction goals. We evaluate our method using four mental disorders, which are prevalent chronic diseases worldwide, as research cases. On the depression detection task, our method (F1 = 0.975~0.978) significantly outperforms traditional supervised learning paradigms, including feature engineering (F1 = 0.760) and architecture engineering (F1 = 0.756). Meanwhile, our approach demonstrates success in few-shot learning, i.e., requiring only a minimal number of training examples to detect chronic diseases based on user-generated textual content (i.e., only 2, 10, or 100 subjects). Moreover, our method can be generalized to other mental disorder detection tasks, including anorexia, pathological gambling, and self-harm (F1 = 0.919~0.978).
Self-Checker: Plug-and-Play Modules for Fact-Checking with Large Language Models
May 24, 2023



Fact-checking is an essential task in NLP that is commonly utilized for validating the factual accuracy of claims. Prior work has mainly focused on fine-tuning pre-trained languages models on specific datasets, which can be computationally intensive and time-consuming. With the rapid development of large language models (LLMs), such as ChatGPT and GPT-3, researchers are now exploring their in-context learning capabilities for a wide range of tasks. In this paper, we aim to assess the capacity of LLMs for fact-checking by introducing Self-Checker, a framework comprising a set of plug-and-play modules that facilitate fact-checking by purely prompting LLMs in an almost zero-shot setting. This framework provides a fast and efficient way to construct fact-checking systems in low-resource environments. Empirical results demonstrate the potential of Self-Checker in utilizing LLMs for fact-checking. However, there is still significant room for improvement compared to SOTA fine-tuned models, which suggests that LLM adoption could be a promising approach for future fact-checking research.
Depression Detection Using Digital Traces on Social Media: A Knowledge-aware Deep Learning Approach
Mar 06, 2023Depression is a common disease worldwide. It is difficult to diagnose and continues to be underdiagnosed. Because depressed patients constantly share their symptoms, major life events, and treatments on social media, researchers are turning to user-generated digital traces on social media for depression detection. Such methods have distinct advantages in combating depression because they can facilitate innovative approaches to fight depression and alleviate its social and economic burden. However, most existing studies lack effective means to incorporate established medical domain knowledge in depression detection or suffer from feature extraction difficulties that impede greater performance. Following the design science research paradigm, we propose a Deep Knowledge-aware Depression Detection (DKDD) framework to accurately detect social media users at risk of depression and explain the critical factors that contribute to such detection. Extensive empirical studies with real-world data demonstrate that, by incorporating domain knowledge, our method outperforms existing state-of-the-art methods. Our work has significant implications for IS research in knowledge-aware machine learning, digital traces utilization, and NLP research in IS. Practically, by providing early detection and explaining the critical factors, DKDD can supplement clinical depression screening and enable large-scale evaluations of a population's mental health status.
Enhancing Task Bot Engagement with Synthesized Open-Domain Dialog
Dec 20, 2022



Many efforts have been made to construct dialog systems for different types of conversations, such as task-oriented dialog (TOD) and open-domain dialog (ODD). To better mimic human-level conversations that usually fuse various dialog modes, it is essential to build a system that can effectively handle both TOD and ODD and access different knowledge sources. To address the lack of available data for the fused task, we propose a framework for automatically generating dialogues that combine knowledge-grounded ODDs and TODs in various settings. Additionally, we introduce a unified model PivotBot that is capable of appropriately adopting TOD and ODD modes and accessing different knowledge sources in order to effectively tackle the fused task. Evaluation results demonstrate the superior ability of the proposed model to switch seamlessly between TOD and ODD tasks.
OPERA: Harmonizing Task-Oriented Dialogs and Information Seeking Experience
Jun 24, 2022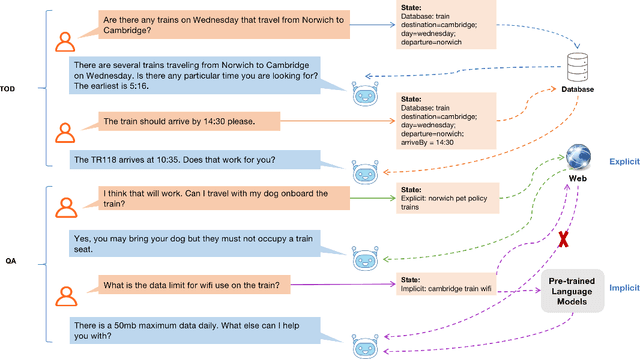
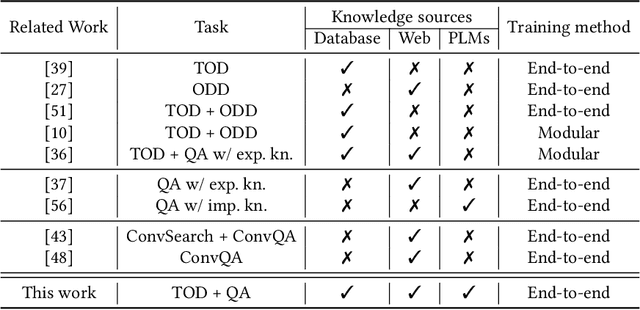
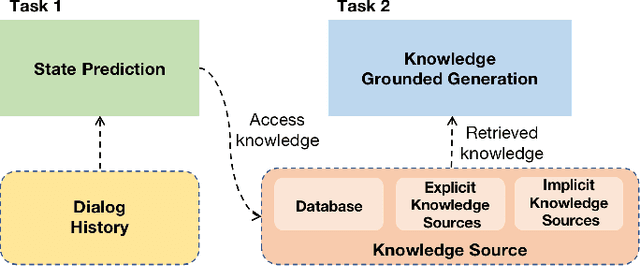

Existing studies in conversational AI mostly treat task-oriented dialog (TOD) and question answering (QA) as separate tasks. Towards the goal of constructing a conversational agent that can complete user tasks and support information seeking, it is important to build a system that handles both TOD and QA with access to various external knowledge. In this work, we propose a new task, Open-Book TOD (OB-TOD), which combines TOD with QA task and expand external knowledge sources to include both explicit knowledge sources (e.g., the Web) and implicit knowledge sources (e.g., pre-trained language models). We create a new dataset OB-MultiWOZ, where we enrich TOD sessions with QA-like information seeking experience grounded on external knowledge. We propose a unified model OPERA (Open-book End-to-end Task-oriented Dialog) which can appropriately access explicit and implicit external knowledge to tackle the defined task. Experimental results demonstrate OPERA's superior performance compared to closed-book baselines and illustrate the value of both knowledge types.